- 数据管道概述(1)
- 数据管道概述
- 管道的使用 (1)
- aws (1)
- php中的双管道(1)
- DynamoDB-数据管道(1)
- DynamoDB-数据管道
- spark中的数据管道-任何(1)
- php代码示例中的双管道
- 什么是数据科学管道?
- spark中的数据管道-任何代码示例
- 时间管道 (1)
- 管道的使用 - 任何代码示例
- AWS DynamoDB – 使用 AWS Lambda 插入数据(1)
- AWS DynamoDB – 使用 AWS Lambda 插入数据
- 短日期角管道 - Javascript(1)
- Angular 6-管道
- Angular 4-管道
- Angular 7管道(1)
- Angular 7管道
- Angular 6-管道(1)
- Angular 4-管道(1)
- Linux中管道的C程序
- Linux中管道的C程序(1)
- 管道角打字稿(1)
- 日期管道 - Javascript 代码示例
- 短日期角管道 - Javascript代码示例
- aws - 任何代码示例
- 线性管道与非线性管道之间的区别(1)
📅 最后修改于: 2020-11-07 03:48:52 🧑 作者: Mango
为什么我们需要数据管道?
让我们考虑一个专注于技术内容的javaTpoint示例。以下是主要目标:
- 改善内容:显示客户将来希望看到的内容。这样,可以增强内容。
- 高效地管理应用程序:跟踪应用程序中的所有活动并将数据存储在现有数据库中,而不是将数据存储在新数据库中。
- 更快:更快但更便宜地改善业务。
要实现上述目标可能是一项艰巨的任务,因为大量数据以不同的格式存储,因此数据的分析,存储和处理变得非常复杂。各种工具用于存储不同格式的数据。针对这种情况的可行解决方案是使用数据管道。数据管道集成了分布在不同数据源中的数据,并且还在同一位置处理数据。
什么是数据管道?
AWS Data Pipeline是一种Web服务,可以访问来自不同服务的数据并进行分析,在同一位置处理数据,然后将数据存储到其他AWS服务(例如DynamoDB,Amazon S3等)中。
例如,使用数据管道,您可以每天将Web服务器日志归档到Amazon S3存储桶,然后对这些日志运行EMR集群,这些日志每周生成一次。

AWS数据管道的概念

AWS Data Pipeline的概念非常简单。我们的数据管道位于顶部。我们提供的输入存储可能是Amazon S3,Dynamo DB或Redshift。这些输入存储中的数据将发送到数据管道。数据管道分析,处理数据,然后将结果发送到输出存储。这些输出存储可以是Amazon Redshift,Amazon S3或Redshift。
AWS Data Pipeline的优势

- 易于使用的AWS Data Pipeline创建起来非常简单,因为AWS提供了一个拖放控制台,即,您无需编写业务逻辑即可创建数据管道。
- 分布式它基于分布式可靠的基础架构。如果在创建数据管道时活动中发生任何故障,则AWS Data Pipeline服务将重试该活动。
- 灵活的数据管道还支持各种功能,例如计划,依赖性跟踪和错误处理。数据管道可以执行各种操作,例如运行Amazon EMR作业,对数据库执行SQL查询或执行在EC2实例上运行的自定义应用程序。
- 廉价的AWS Data Pipeline使用起来非常便宜,并且每月的构建费用较低。
- Scalabl通过使用数据管道,您可以将工作以串行或并行方式分配到一台或多台计算机。
- 透明的AWS Data Pipeline提供对计算资源(例如EC2实例或EMR报告)的完全控制。
AWS数据管道的组件
以下是AWS Data Pipeline的主要组件:
- 管道定义它指定业务逻辑应如何与数据管道通信。它包含不同的信息:
- 数据节点它指定数据源的名称,位置和格式,例如Amazon S3,Dynamo DB等。
- 活动活动是对数据库执行SQL查询,将数据从一个数据源转换为另一数据源的操作。
- 计划调度是在活动上执行的。
- 前提条件在安排活动之前,必须满足前提条件。例如,您想要从Amazon S3中移动数据,那么前提条件是检查数据是否在Amazon S3中可用。如果满足前提条件,那么将执行该活动。
- 资源您拥有计算资源,例如Amazon EC2或EMR集群。
- 操作它会通过向您发送电子邮件或触发警报来更新有关管道的状态。
- 管道它包括三个重要项目:
- 管道组件我们已经讨论了管道组件。基本上,这是您如何将数据管道与AWS服务进行通信的方式。
- 实例在管道中编译所有管道组件时,它将创建一个可操作的实例,其中包含特定任务的信息。
- 尝试我们知道,数据管道允许您重试失败的操作。这些不过是尝试。
- 任务运行器任务运行器是一个从数据管道中轮询任务并执行任务的应用程序。
任务运行器的体系结构

在上述架构中,任务运行器从数据管道轮询任务。任务完成后,任务运行器将报告其进度。报告后,将检查条件是否成功完成任务。如果任务成功,则任务结束,如果否,则检查重试尝试。如果仍保留重试次数,则整个过程将再次继续;否则,将重新进行整个过程。否则,任务突然结束。
创建数据管道
- 登录到AWS管理控制台。
- 首先,我们将创建Dynamo DB表和两个S3存储桶。
- 现在,我们将创建Dynamo DB表。单击创建表。

- 填写以下详细信息,例如表名称,主键以创建新表。

- 下面的屏幕显示表“ student”已创建。
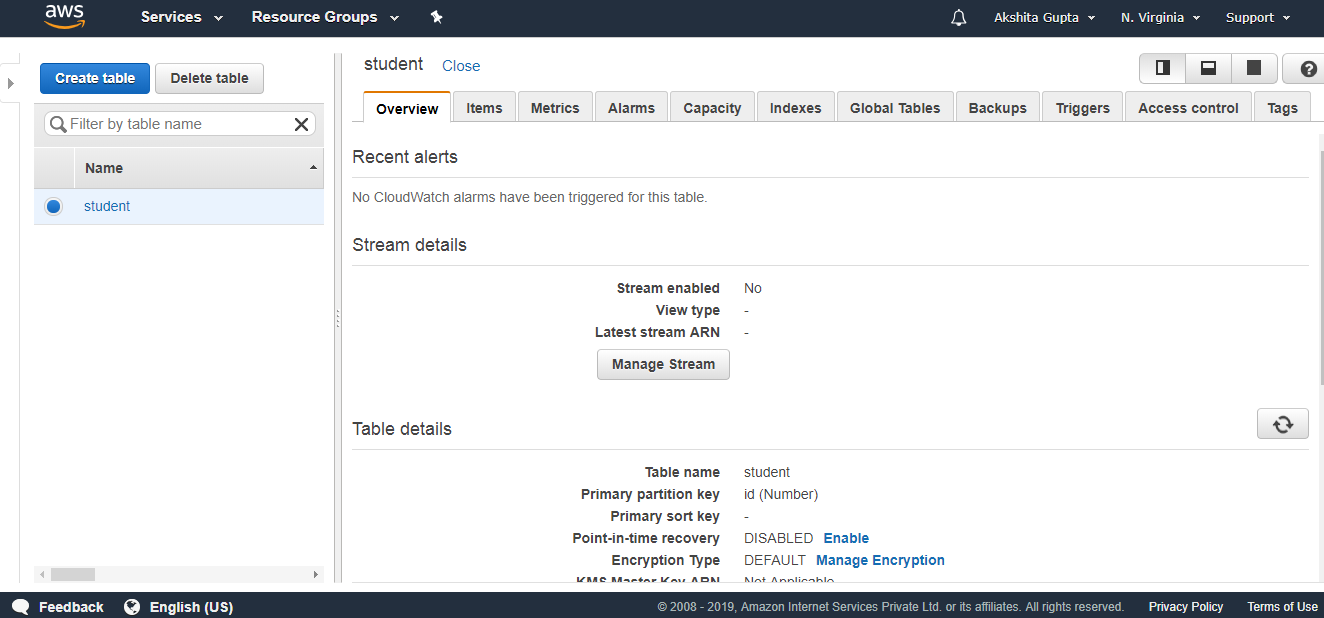
- 单击项目,然后单击创建项目。
- 我们添加了三个项目,即id,Name和Gender。

- 以下屏幕显示数据已插入DynamoDB表中。

- 现在,我们创建两个S3存储桶。首先将存储我们从DynamoDB导出的数据,其次将存储日志。

我们创建了两个存储桶,即logstoredata和studata。 logstoredata存储桶存储日志,而studata存储桶存储我们从DynamoDB导出的数据。
- 现在,我们创建数据管道。移至数据管道服务,然后单击“入门”按钮

- 填写以下详细信息以创建管道,然后如果要更改管道中的任何组件,请单击“在Architect上编辑”。
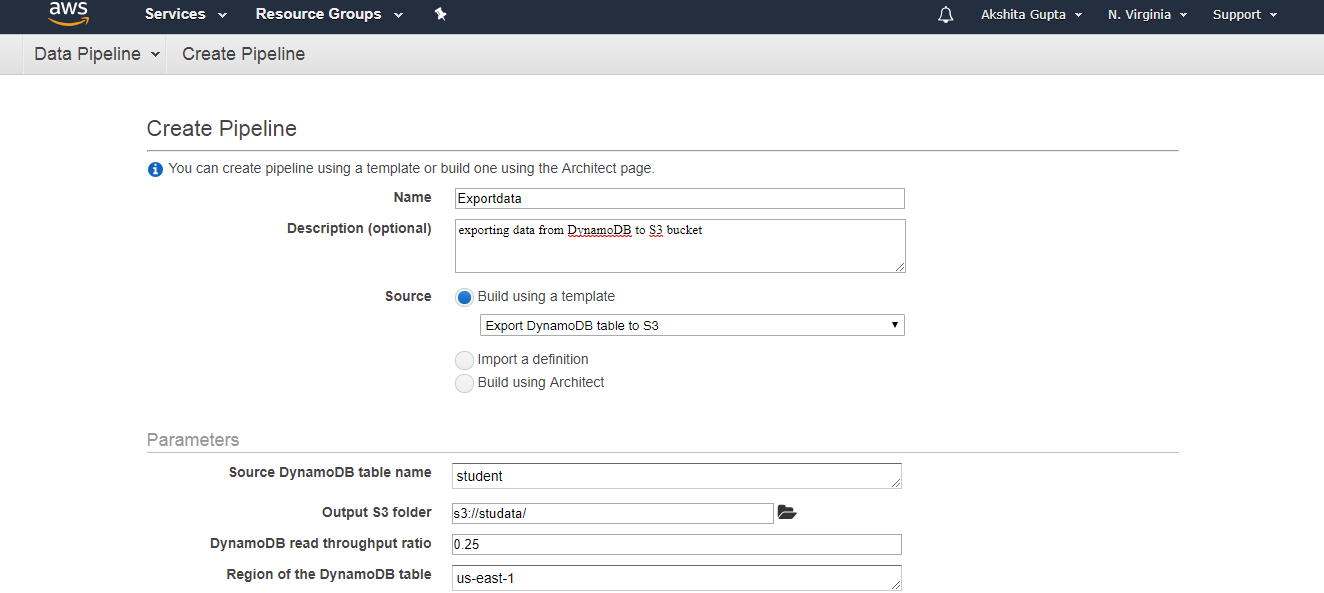


- 单击“在Architect中编辑”时,将出现以下屏幕。我们可以看到警告发生了,即缺少TerminateAfter。要删除此警告,您需要在参考资料中添加TerminateAfter的新字段。添加字段后,单击“激活”按钮。

- 最初,出现WAITING_FOR_DEPENDENCIES状态。刷新时,状态为WAITING_FOR_RUNNER。一旦出现“运行”状态,您就可以检查S3存储桶,数据将存储在其中。
