- Beautiful Soup-安装
- Beautiful Soup-安装(1)
- Beautiful Soup-搜索树
- Beautiful Soup-搜索树(1)
- Beautiful Soup教程
- Beautiful Soup教程(1)
- Beautiful Soup-编码(1)
- Beautiful Soup-编码
- 讨论Beautiful Soup
- Beautiful Soup-概述(1)
- Beautiful Soup-概述
- Beautiful Soup-修改树
- Beautiful Soup-修改树(1)
- Beautiful Soup-有用的资源(1)
- Beautiful Soup-有用的资源
- Beautiful Soup-BeautifulSoup对象
- Beautiful Soup-BeautifulSoup对象(1)
- Beautiful Soup-通过标签导航(1)
- Beautiful Soup-通过标签导航
- pip install Beautiful Soup - Shell-Bash (1)
- pip install Beautiful Soup - Shell-Bash 代码示例
- Beautiful Soup-汤页(1)
- Beautiful Soup-汤页
- Beautiful Soup-各种物品
- Beautiful Soup-各种物品(1)
- Beautiful Soup-仅解析文档的一部分
- Beautiful Soup-仅解析文档的一部分(1)
- Ansible-故障排除
- Ansible-故障排除(1)
📅 最后修改于: 2020-11-09 14:29:13 🧑 作者: Mango
错误处理
在BeautifulSoup中,需要处理两种主要的错误。这两个错误不是来自脚本,而是来自代码段的结构,因为BeautifulSoup API会引发错误。
两个主要错误如下-
AttributeError
当点表示法找不到当前HTML标签的同级标签时,会导致此错误。例如,您可能遇到此错误,因为缺少“ anchor tag”,cost-key遍历并需要定位标记时会抛出错误。
KeyError
如果缺少必需的HTML标签属性,则会发生此错误。例如,如果我们在代码段中没有data-pid属性,则pid键将引发key-error。
为了避免在解析结果时出现上面列出的两个错误,将绕过该结果以确保未将格式错误的代码段插入数据库中-
except(AttributeError, KeyError) as er:
pass
诊断()
每当我们发现要理解BeautifulSoup对我们的文档或HTML所做的任何困难时,只需将其传递给diagnostic()函数。通过将文档文件传递给diagnostic()函数,我们可以显示不同解析器列表如何处理文档。
下面是一个示例来演示如何使用diagnostic()函数-
from bs4.diagnose import diagnose
with open("20 Books.html",encoding="utf8") as fp:
data = fp.read()
diagnose(data)
输出
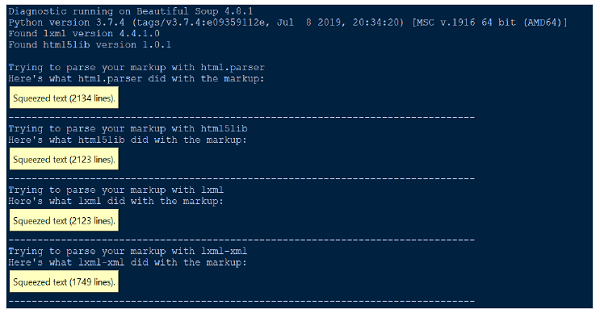
解析错误
解析错误主要有两种。当您将文档提供给BeautifulSoup时,可能会遇到HTMLParseError之类的异常。您还可能会得到意想不到的结果,其中BeautifulSoup解析树看起来与解析文档中的预期结果有很大差异。
没有任何解析错误是由于BeautifulSoup引起的。因为BeautifulSoup不包含任何解析器代码,所以由于使用了外部解析器(html5lib,lxml)。解决上述解析错误的一种方法是使用另一个解析器。
from HTMLParser import HTMLParser
try:
from HTMLParser import HTMLParseError
except ImportError, e:
# From python 3.5, HTMLParseError is removed. Since it can never be
# thrown in 3.5, we can just define our own class as a placeholder.
class HTMLParseError(Exception):
pass
Python内置的HTML解析器会导致两个最常见的解析错误:HTMLParser.HTMLParserError:格式错误的开始标记和HTMLParser.HTMLParserError:错误的结束标记,要解决此问题,主要是使用另一个解析器:lxml或html5lib。
另一种常见的意外行为类型是您找不到文档中已知的标签。但是,当您运行find_all()返回[]或find()返回None。
这可能是由于Python内置HTML解析器有时会跳过不了解的标签。
XML解析器错误
默认情况下,BeautifulSoup软件包将文档解析为HTML,但是,它非常易于使用,并且可以使用beautifulsoup4以非常优雅的方式处理格式错误的XML。
要将文档解析为XML,您需要具有lxml解析器,并且只需要将“ xml”作为第二个参数传递给Beautifulsoup构造函数-
soup = BeautifulSoup(markup, "lxml-xml")
要么
soup = BeautifulSoup(markup, "xml")
一个常见的XML解析错误是-
AttributeError: 'NoneType' object has no attribute 'attrib'
如果使用find()或findall()函数某些元素丢失或未定义,则可能会发生这种情况。
其他解析错误
下面给出的是我们将在本节中讨论的其他一些解析错误-
环境问题
除了上述解析错误外,您还可能遇到其他解析问题,例如环境问题,其中脚本可能在一个操作系统中运行,但在另一操作系统中无法运行,或者可能在一个虚拟环境中运行,但在另一虚拟环境中无法运行,或者可能无法运行虚拟环境之外。所有这些问题可能是因为两个环境具有可用的不同解析器库。
建议在当前的工作环境中了解或检查默认的解析器。您可以检查可用于当前工作环境的当前默认解析器,也可以将所需的解析器库作为第二个参数明确传递给BeautifulSoup构造函数。
不区分大小写
由于HTML标记和属性不区分大小写,因此所有三个HTML解析器都将标记和属性名称转换为小写。但是,如果要保留大小写混合的标签和属性,则最好将文档解析为XML。
UnicodeEncodeError
让我们看看下面的代码段-
soup = BeautifulSoup(response, "html.parser")
print (soup)
输出
UnicodeEncodeError: 'charmap' codec can't encode character '\u011f'
上述问题可能是由于两种主要情况。您可能正在尝试打印出您的控制台不知道如何显示的unicode字符。其次,您尝试写入文件,并传入默认编码不支持的Unicode字符。
解决上述问题的一种方法是在使汤获得所需结果之前对响应文本/字符进行编码,如下所示:
responseTxt = response.text.encode('UTF-8')
KeyError:[attr]
这是由于相关标签未定义attr属性时访问tag [‘attr’]引起的。最常见的错误是:“ KeyError:’href’”和“ KeyError:’class’”。如果不确定是否定义了attr,请使用tag.get(’attr’)。
for item in soup.fetch('a'):
try:
if (item['href'].startswith('/') or "tutorialspoint" in item['href']):
(...)
except KeyError:
pass # or some other fallback action
AttributeError
您可能会遇到AttributeError,如下所示:
AttributeError: 'list' object has no attribute 'find_all'
发生上述错误的主要原因是,您期望find_all()返回单个标记或字符串。但是,soup.find_all返回一个Python元素列表。
您需要做的就是遍历列表并从这些元素中捕获数据。