- 深度神经网络(1)
- 深度神经网络
- 深度神经网络中的反向传播过程
- 深度神经网络中的反向传播过程(1)
- 具有 L 层的深度神经网络(1)
- 具有 L 层的深度神经网络
- 深度神经网络的测试
- 深度神经网络的实现(1)
- 深度神经网络的实现
- 深度神经网络的体系结构
- 神经网络中的架构和学习过程
- 神经网络中的架构和学习过程(1)
- 神经网络和深度学习系统之间的区别
- 神经网络和深度学习系统之间的区别(1)
- 在Python中实现神经网络训练过程
- 在Python中实现神经网络训练过程(1)
- 深度神经网络的权重初始化技术(1)
- 深度神经网络的权重初始化技术
- 深度可分离卷积神经网络(1)
- 深度可分离卷积神经网络
- 深度参数连续卷积神经网络(1)
- 深度参数连续卷积神经网络
- PyBrain-使用前馈网络
- PyBrain-使用前馈网络(1)
- 深度神经网络中的非线性边界(1)
- 深度神经网络中的非线性边界
- 深度学习中的变压器神经网络——概述(1)
- 深度学习中的变压器神经网络——概述
- 深度智能可分离卷积神经网络(1)
📅 最后修改于: 2020-11-11 00:52:07 🧑 作者: Mango
深度神经网络中的前馈过程
现在,我们知道具有不同权重和偏差的线的组合如何导致非线性模型。神经网络如何知道每一层应具有的权重和偏差值?这与我们对基于单个感知器模型的处理方式没有什么不同。
我们仍在使用梯度下降优化算法,该算法通过在最陡峭的下降方向(该方向在确保最小误差的同时更新我们的模型参数)上反复移动来最大限度地减少模型误差。它会更新每个图层中每个模型的权重。稍后,我们将更多地讨论优化算法和反向传播。
认识到我们神经网络的后续训练很重要。通过将我们的数据样本除以某个决策边界来完成识别。
“接收输入以产生某种输出以进行某种预测的过程称为前馈。”前馈神经网络是许多其他重要神经网络(例如卷积神经网络)的核心。
在前馈神经网络中,网络中没有任何反馈回路或连接。这里只是一个输入层,一个隐藏层和一个输出层。
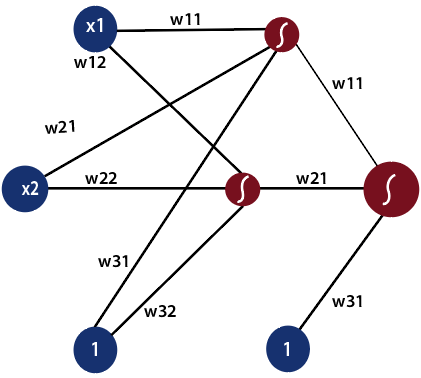
可能有多个隐藏层,具体取决于您要处理的数据类型。隐藏层的数量称为神经网络的深度。深度神经网络可以从更多功能中学习。输入层首先为神经网络提供数据,然后输出层根据一系列功能对该数据进行预测。 ReLU函数是深度神经网络中最常用的激活函数。
为了深入了解前馈过程,让我们从数学上看一下。
1)第一个输入被馈送到网络,其表示为矩阵x1,x2,其中一个是偏置值。
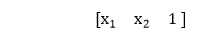
2)将每个输入相对于第一模型和第二模型的权重相乘,以获得它们在每个模型中处于正数区域的概率。
因此,我们将使用矩阵乘法将输入乘以权重矩阵。
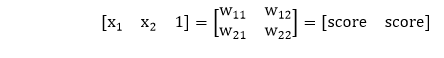
3)之后,我们将分数取为S形,并给出两个模型中该点处于正区域的概率。

4)我们将从上一步获得的概率乘以第二组权重。每当组合输入时,我们总是将偏差设为1。

并且我们知道要获得该点在该模型的正区域中的概率,我们采用S型曲线,从而在前馈过程中产生最终输出。
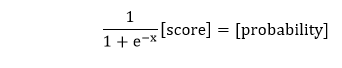
让我们以先前具有以下线性模型的神经网络和隐藏层组合在一起,在输出层中形成非线性模型。

因此,我们将使用非线性模型来执行输出操作,以描述该点位于正区域中的概率。该点由2和2表示。连同偏差,我们将输入表示为

隐藏层调用中的第一个线性模型及其方程式定义了该模型
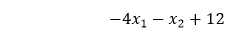
这意味着在第一层中,为了获得线性组合,将输入乘以-4,-1,并将偏置值乘以十二。
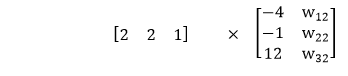
输入的权重乘以-1 / 5、1,偏差乘以3,即可在我们的第二个模型中获得同一点的线性组合。
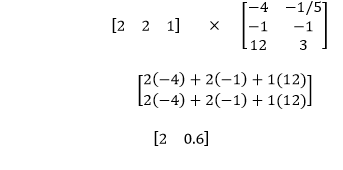
现在,为了获得该点相对于两个模型的正区域中的概率,我们将S形应用于两个点
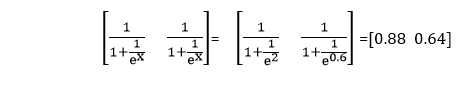
第二层包含权重,该权重指示第一层中的线性模型的组合以获得第二层中的非线性模型。权重为1.5、1,偏差值为0.5。
现在,我们必须将第一层的概率乘以第二组权重
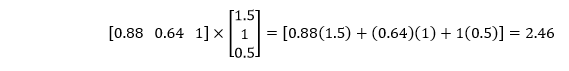
现在,我们将以最终分数的S形表示
这是前馈过程背后的完整数学运算,在该过程中,来自输入的输入遍历了神经网络的整个深度。在此示例中,只有一个隐藏层。无论是一个隐藏层还是二十个隐藏层,所有隐藏层的计算过程都相同。