- 卷积神经网络模型的测试
- 卷积神经网络模型的测试(1)
- 卷积神经网络模型实现
- 卷积神经网络
- 卷积神经网络(1)
- 卷积神经网络模型的训练
- 卷积神经网络模型的训练(1)
- 卷积神经网络的工作
- 卷积神经网络的工作(1)
- TensorFlow-卷积神经网络(1)
- TensorFlow-卷积神经网络
- 卷积神经网络简介(1)
- 卷积神经网络简介
- PyTorch-卷积神经网络
- PyTorch-卷积神经网络(1)
- Keras-卷积神经网络
- 使用卷积神经网络的多个标签(1)
- 使用卷积神经网络的多个标签
- TensorFlow中卷积神经网络的介绍(1)
- TensorFlow中卷积神经网络的介绍
- CNTK-卷积神经网络
- CNTK-卷积神经网络(1)
- Tensorflow 中的卷积神经网络 (CNN)(1)
- Tensorflow 中的卷积神经网络 (CNN)
- 深度可分离卷积神经网络(1)
- 深度可分离卷积神经网络
- 深度参数连续卷积神经网络(1)
- 深度参数连续卷积神经网络
- 卷积神经网络的重要性 |机器学习(1)
📅 最后修改于: 2020-11-11 01:06:23 🧑 作者: Mango
卷积神经网络模型的验证
在训练部分,我们在MNIST数据集(无尽数据集)上训练了CNN模型,它似乎达到了合理的损失和准确性。如果模型可以利用它所学到的知识并将其自身概括为新数据,那么它将是其性能的真实证明。这将以与上一个主题相同的方式进行。
步骤1:
我们将在训练部分创建的训练数据集的帮助下创建验证集。在这个时候,我们将训练等于false设置为:
validation_dataset=datasets.MNIST(root='./data',train=False,download=True,transform=transform1)
第2步:
现在,类似于我们在训练部分中声明训练加载程序的原因,我们将定义一个验证加载程序。验证加载程序的创建方式也与创建训练加载程序的方式相同,但是这次我们传递的是训练加载程序,而不是训练数据集,并且我们将shuffle设置为false,因为我们不会训练验证数据。无需将其改组,因为它仅用于测试目的。
validation_loader=torch.utils.data.DataLoader(dataset=validation_dataset,batch_size=100,shuffle=False)
第三步:
我们的下一步是分析每个时期的验证损失和准确性。为此,我们必须为丢失的验证运行和校正运行丢失创建两个列表。
val_loss_history=[]
val_correct_history=[]
第四步:
在下一步中,我们将验证模型。该模型将验证相同的纪元。在完成整个训练集的迭代以训练我们的数据之后,我们现在将迭代验证集以测试我们的数据。
我们将首先测量两件事。第一个是我们模型的性能,即多少个正确的分类。我们的模型基于验证集上的测试集来检查是否过拟合。我们将运行损失和验证的运行更正设置为:
val_loss=0.0
val_correct=0.0
步骤5:
现在,我们可以遍历我们的测试数据。因此,在else语句之后,我们将为标签和输入定义一个循环语句为:
for val_input,val_labels in validation_loader:
步骤6:
我们正在处理首先将输入传递到的卷积神经网络。我们将专注于这些图像的四个维度。因此,无需压平它们。
正如我们将模型分配给设备一样,我们也将输入和标签也分配给了设备。
input=input.to(device)
labels=input.to(device)
现在,借助这些输入,我们得到的输出为
val_outputs=model(val_inputs)
步骤7:
借助输出,我们将计算总分类交叉熵损失,最终将输出与实际标签进行比较。
val_loss1=criteron(val_outputs,val_labels)
我们没有训练我们的神经网络,因此不需要调用zero_grad(),backward()或任何其他方法。并且也不再需要计算导数。在节省内存的操作范围内,我们在For循环之前使用手电筒调用no_grad()方法:
with torch.no_grad():
它将暂时将所有require grad标志设置为false。
步骤8:
现在,我们将以与计算训练损失和训练准确性相同的方式来计算验证损失和准确性:
_,val_preds=torch.max(val_outputs,1)
val_loss+=val_loss1.item()
val_correct+=torch.sum(val_preds==val_labels.data)
步骤9:
现在,我们将计算验证时间损失,其方法与计算训练时间损失的方法相同,在该方法中,我们将总运行损失除以数据集的长度。因此它将写为:
val_epoch_loss=val_loss/len(validation_loader)
val_epoch_acc=val_correct.float()/len(validation_loader)
val_loss_history.append(val_epoch_loss)
val_correct_history.append(val_epoch_acc)
步骤10:
我们将验证损失和验证准确性print为:
print('validation_loss:{:.4f},{:.4f}'.format(val_epoch_loss,val_epoch_acc.item()))

步骤11:
现在,我们将其绘制以用于可视化目的。我们将其绘制为:
plt.plot(loss_history,label='Training Loss')
plt.plot(val_loss_history,label='Validation Loss')
plt.legend()
plt.show()
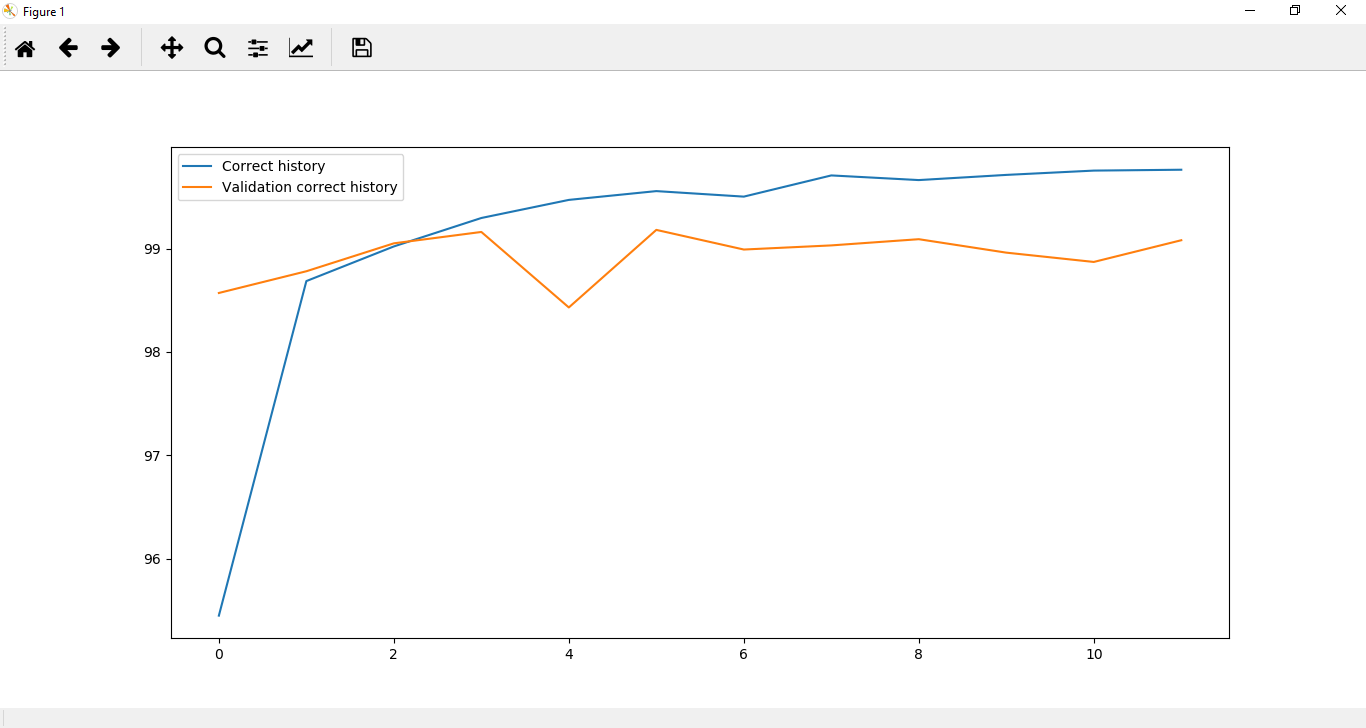
plt.plot(correct_history,label='Training accuracy')
plt.plot(val_correct_history,label='Validation accuracy')
plt.legend()
plt.show()

从上图可以清楚地看出,在CNN中发生了过拟合。为了减少这种过度拟合,我们将介绍另一种称为Dropout Layer的快速技术。
步骤12:
在下一步中,我们将移至LeNet类并添加特定的图层类型,这将减少数据的过拟合。此图层类型称为“退出”图层。该层实质上是通过将输入单元的分数比率随机设置为0并在训练期间进行每次更新来实现的。
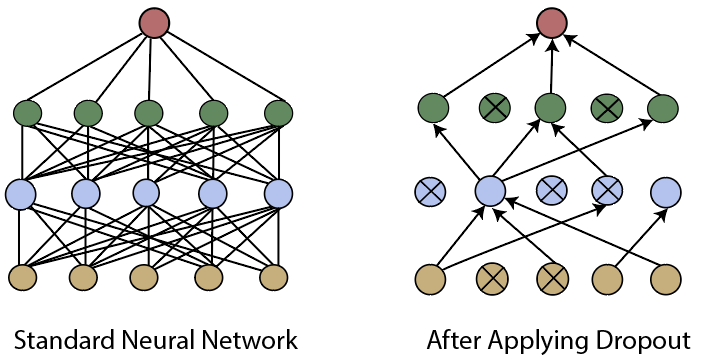
上图显示了一个标准的神经网络,也显示了应用辍学后的相同神经网络。我们可以看到某些节点已关闭,并且不再与网络信息通信。
我们将使用不止一个辍学层,将其用于给定的网络中以获得所需的性能。我们将这些辍学层放置在卷积层之间以及完全连接的层之间。辍学层用于具有大量参数的层之间,因为这些高参数层更可能过度拟合并存储训练数据。因此,我们将辍学层设置在完全连接的层之间。
我们将在nn.Dropout模块的帮助下初始化辍学层,并将辍学率作为参数传递给初始化程序。给定节点丢失的概率将设置为0.5:
self.dropout1=nn.dropout(0.5)
步骤13:
在下一步中,我们将在正向函数的完全连接层之间定义第二个退出层:
x=self.dropout1(x)
现在,我们将运行我们的程序,它将为我们提供更准确的结果,如下所示:

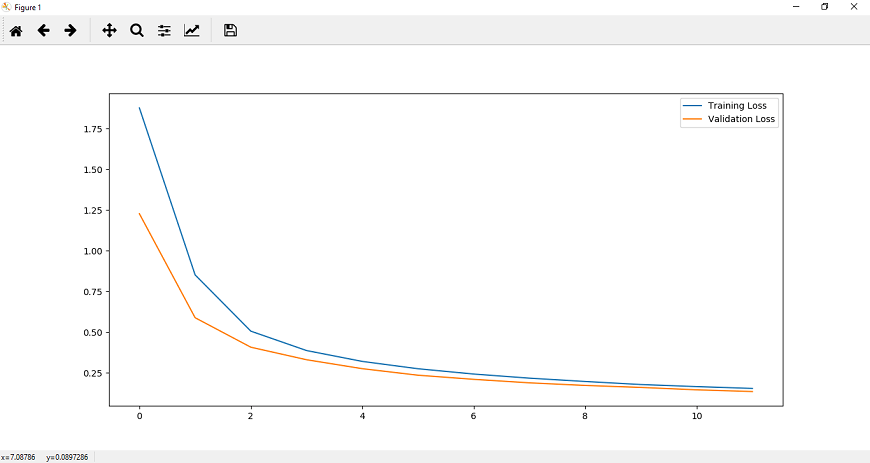
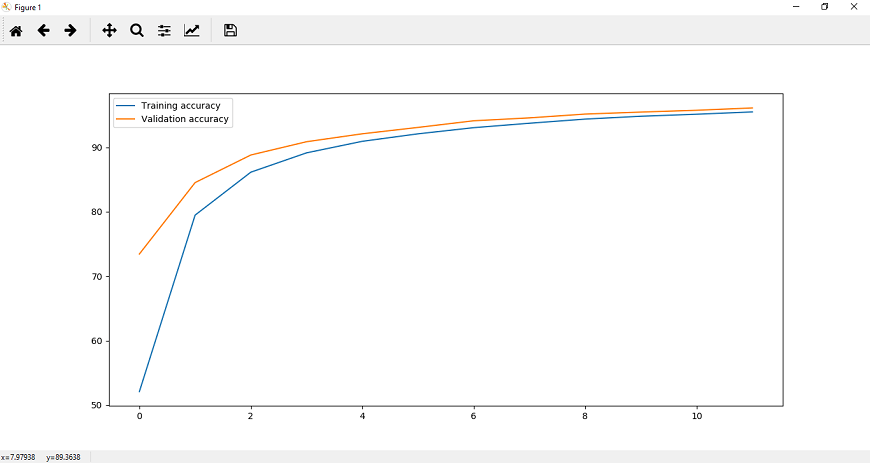
完整的代码
import torch
import matplotlib.pyplot as plt
import numpy as np
import torch.nn.functional as func
import PIL.ImageOps
from torch import nn
from torchvision import datasets,transforms
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
transform1=transforms.Compose([transforms.Resize((28,28)),transforms.ToTensor(),transforms.Normalize((0.5,),(0.5,))])
training_dataset=datasets.MNIST(root='./data',train=True,download=True,transform=transform1)
validation_dataset=datasets.MNIST(root='./data',train=False,download=True,transform=transform1)
training_loader=torch.utils.data.DataLoader(dataset=training_dataset,batch_size=100,shuffle=True)
validation_loader=torch.utils.data.DataLoader(dataset=validation_dataset,batch_size=100,shuffle=False)
class LeNet(nn.Module):
def __init__(self):
super().__init__()
self.conv1=nn.Conv2d(1,20,5,1)
self.conv2=nn.Conv2d(20,50,5,1)
self.fully1=nn.Linear(4*4*50,500)
self.dropout1=nn.Dropout(0.5)
self.fully2=nn.Linear(500,10)
def forward(self,x):
x=func.relu(self.conv1(x))
x=func.max_pool2d(x,2,2)
x=func.relu(self.conv2(x))
x=func.max_pool2d(x,2,2)
x=x.view(-1,4*4*50) #Reshaping the output into desired shape
x=func.relu(self.fully1(x)) #Applying relu activation function to our first fully connected layer
x=self.dropout1(x)
x=self.fully2(x) #We will not apply activation function here because we are dealing with multiclass dataset
return x
model=LeNet().to(device)
criteron=nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(model.parameters(),lr=0.00001)
epochs=12
loss_history=[]
correct_history=[]
val_loss_history=[]
val_correct_history=[]
for e in range(epochs):
loss=0.0
correct=0.0
val_loss=0.0
val_correct=0.0
for input,labels in training_loader:
input=input.to(device)
labels=labels.to(device)
outputs=model(input)
loss1=criteron(outputs,labels)
optimizer.zero_grad()
loss1.backward()
optimizer.step()
_,preds=torch.max(outputs,1)
loss+=loss1.item()
correct+=torch.sum(preds==labels.data)
else:
with torch.no_grad():
for val_input,val_labels in validation_loader:
val_input=val_input.to(device)
val_labels=val_labels.to(device)
val_outputs=model(val_input)
val_loss1=criteron(val_outputs,val_labels)
_,val_preds=torch.max(val_outputs,1)
val_loss+=val_loss1.item()
val_correct+=torch.sum(val_preds==val_labels.data)
epoch_loss=loss/len(training_loader)
epoch_acc=correct.float()/len(training_loader)
loss_history.append(epoch_loss)
correct_history.append(epoch_acc)
val_epoch_loss=val_loss/len(validation_loader)
val_epoch_acc=val_correct.float()/len(validation_loader)
val_loss_history.append(val_epoch_loss)
val_correct_history.append(val_epoch_acc)
print('training_loss:{:.4f},{:.4f}'.format(epoch_loss,epoch_acc.item()))
print('validation_loss:{:.4f},{:.4f}'.format(val_epoch_loss,val_epoch_acc.item()))
plt.plot(loss_history,label='Training Loss')
plt.plot(val_loss_history,label='Validation Loss')
plt.legend()
plt.show()
plt.plot(correct_history,label='Training accuracy')
plt.plot(val_correct_history,label='Validation accuracy')
plt.legend()
plt.show()