- 卷积神经网络
- 卷积神经网络(1)
- TensorFlow-卷积神经网络(1)
- TensorFlow-卷积神经网络
- 卷积神经网络简介(1)
- 卷积神经网络简介
- 卷积神经网络(CNN)在 Tensorflow 中的工作(1)
- 卷积神经网络(CNN)在 Tensorflow 中的工作
- PyTorch-卷积神经网络
- PyTorch-卷积神经网络(1)
- Keras-卷积神经网络
- 卷积神经网络模型的测试(1)
- 卷积神经网络模型的测试
- 神经网络如何工作 (1)
- 卷积神经网络模型的验证(1)
- 卷积神经网络模型的验证
- 卷积神经网络模型实现
- 使用卷积神经网络的多个标签
- 使用卷积神经网络的多个标签(1)
- TensorFlow中卷积神经网络的介绍
- TensorFlow中卷积神经网络的介绍(1)
- CNTK-卷积神经网络
- CNTK-卷积神经网络(1)
- 卷积神经网络模型的训练
- 卷积神经网络模型的训练(1)
- 神经网络如何工作 - 无论代码示例
- 如何工作神经网络 - 无论代码示例
- Tensorflow 中的卷积神经网络 (CNN)(1)
- Tensorflow 中的卷积神经网络 (CNN)
📅 最后修改于: 2021-01-11 10:40:15 🧑 作者: Mango
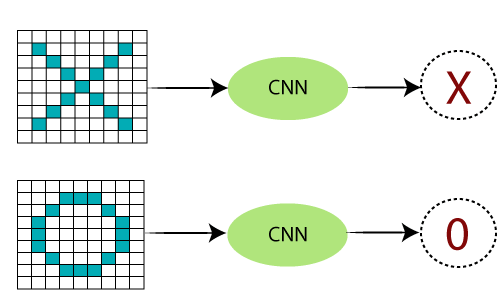
卷积神经网络的工作
CNN(卷积神经网络或ConvNet)是一种前馈人工网络,其神经元之间的连接方式受动物视觉皮层组织的启发。
视觉皮层有一小部分细胞,对视野的特定区域敏感。我们大脑中的某些单个神经元细胞在存在特定方向的边缘时会做出反应。
例如,
当暴露于顶点边缘时,一些神经元会激发,而当显示水平或对角线边缘时,一些神经元会激发。
CNN利用输入数据中存在的空间相关性。神经网络的每个并发层都连接一些输入神经元。该区域称为局部感受野。局部感受野集中在隐藏的神经元上。
隐藏的神经元在提到的字段内处理输入数据,而不实现特定边界之外的更改。
CNN的工作
通常,卷积神经网络具有三层。并且,借助分类器的示例,我们逐层理解了每一层。借助它可以对X和O的图像进行分类。因此,对于这种情况,我们将了解所有四个层。
卷积神经网络具有以下几层:
- 卷积
- ReLU层
- 汇集
- 全连接层
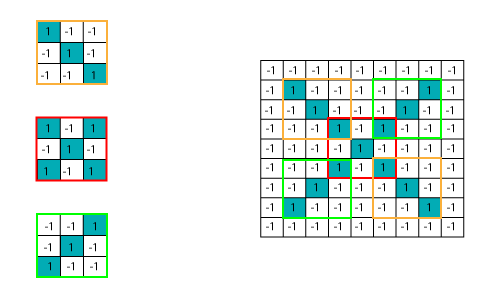
在某些棘手的情况下, X可以以这四种形式以及右侧来表示,因此这些不过是变形图像的影响。在这里,有多个X和O的表示。这使计算机难以识别。但是目标是,如果输入信号看起来像以前看到的先前图像,则“图像”参考信号将与输入信号卷积。然后将生成的输出信号传递到下一层。考虑下图所示:

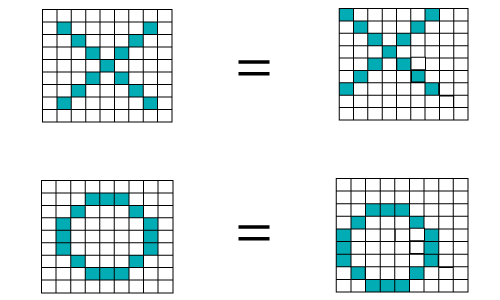
计算机使用每个像素上的数字来理解图像。
在我们的示例中,我们考虑了蓝色像素的值为1 ,白色像素的值为-1。这是我们在原始二进制分类中实现区分像素的方法。

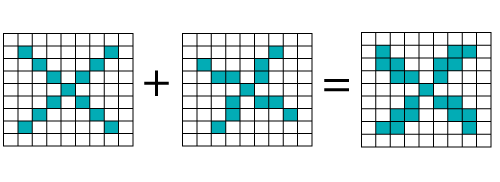
当我们使用标准技术比较这两个图像时,一个是X的正确图像,另一个是X的失真图像。我们发现计算机无法对X的变形图像进行分类。因此,当我们将这两个图像的像素值相加时,我们得到了某种东西,因此计算机无法识别它是否为X。
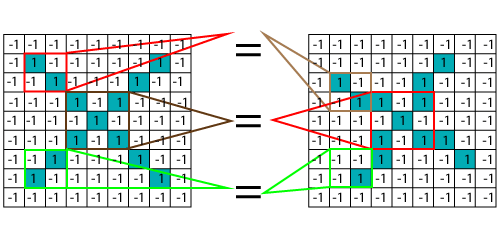
在CNN的帮助下,我们拍摄了图像的小块,因此这些块或小片称为过滤器。我们在两张图片的相同位置发现了粗糙的特征匹配。整个图像匹配方案之间的相似性使CNN变得更好。我们有这些滤镜,因此请考虑这第一个滤镜正好等于变形图像中图像部分的特征,并且这是正确的图像。
CNN逐段比较图像。
通过在两个图像中大致相同的位置找到粗略匹配,CNN在看到相似性方面比全图像匹配方案好得多。
我们具有三个功能或过滤器,如下所示。
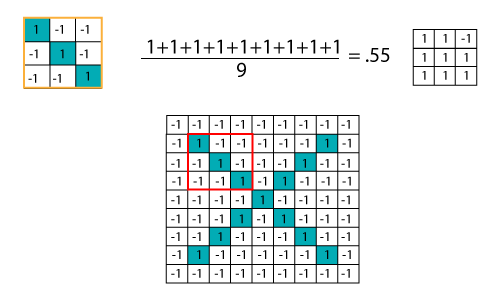
乘以对应的像素值
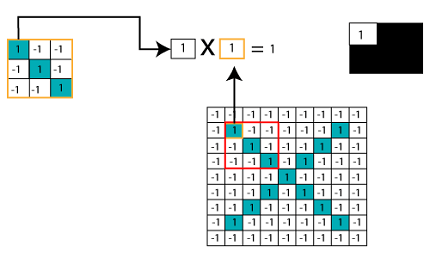
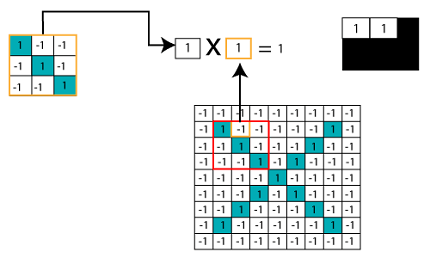
加和除以像素总数

创建地图以将过滤器的值放在该位置
为了跟踪创建地图的要素并在该位置放置一定数量的过滤器。

将滤镜滑动到整个图像
现在,使用相同的功能并将其移至另一个位置,然后再次执行过滤。
卷积层输出
我们将要素转移到图像的每个其他位置,并查看要素如何与该区域匹配。最后,我们将得到如下输出:
同样,我们对其他所有滤镜执行相同的卷积。

ReLU层
在这一层中,我们从过滤的图像中删除每个负值,并将它们替换为零。
正在避免将这些值相加为零。
整流线性单位(ReLU)变换功能仅在输入大于一定数量时才激活节点。当数据低于零时,输出为零,但是当信息超过阈值时。它与因变量具有线性关系。
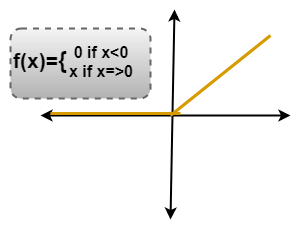
我们考虑了具有上述值的任何简单函数。因此,该函数仅在因变量获得该值的情况下运行。例如,获得以下值。

消除负值
输出一项功能

输出所有功能

池化层
在该层中,我们将图像堆栈缩小为较小的尺寸。在经过激活层之后进行合并。为此,我们执行以下4个步骤:
- 选择一个窗口大小(通常为2或3)
- 大步前进(通常2个)
- 走在你的过滤图像的窗口
- 从每个Window取最大值
让我们通过一个例子来理解这一点。考虑在窗口大小为2且跨度为2的情况下执行合并。
计算每个窗口中的最大值
让我们开始第一个过滤后的图像。在我们的第一个窗口中,最大值或最大值为1,因此我们对其进行跟踪并将窗口移动两个步幅。
在整个图像中移动窗口

穿过池化层后的输出

堆叠层
这样一来,在输入经过3层(卷积,ReLU和Pooling)之后,我们就得到了7×7矩阵中的4×4矩阵,从而得到一张图片中的时间帧,如下所示:
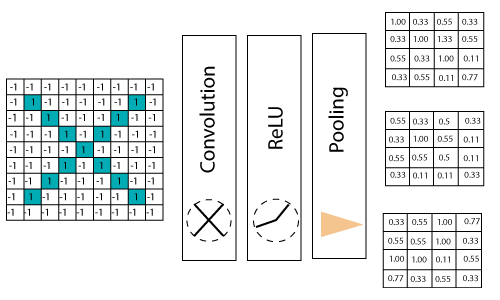
我们将图片从4×4缩小到较小的图片?我们需要在第一次通过后执行3次操作。因此,第二遍之后,我们得出了一个2×2矩阵,如下所示:
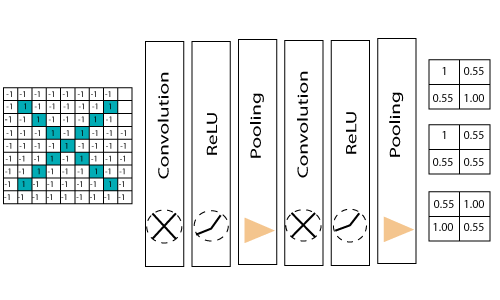
网络中的最后一层是完全连接的,这意味着前一层的神经元连接到后一层的每个神经元。
这模仿了高级推理,其中考虑了从输入到输出的所有可能路径。
然后,将缩小的图像放入单个列表中,这样我们就可以通过两层卷积relo和合并,然后将其转换为单个文件或向量。
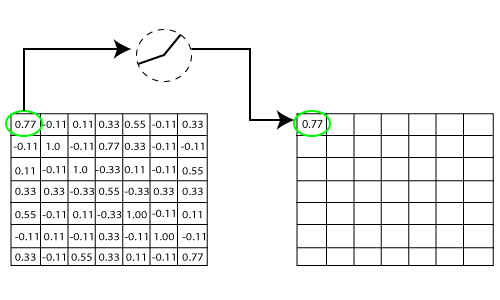
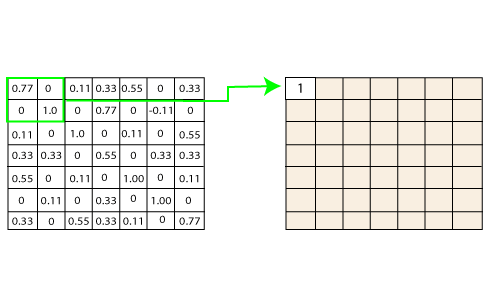
我们取第一个值1,然后取0.55,取0.55,然后取1。然后取1,然后取0.55,然后取1,然后取0.55和0.55,然后再次取0.55,取0.55,1、1,和0.55。因此,这不过是向量。完全连接的层是进行分类的最后一层。在这里,我们将经过过滤和缩小的图像放入一个列表中,如下所示。

输出量
当我们输入时,“ X ”和“ 0 ”。然后向量中将有一些元素很高。考虑下图,因为我们看到“ X”有不同的顶部元素,同样,对于“ O”我们有各种高元素。
在我的清单中有一些很高的特定值,如果我们重复针对不同的个人成本所讨论的整个过程,则该值很高。这将是更高的,因此对于一个X我们有第一,第4,第5,第10,和11矢量值的第i个元素是更高。对于O,我们有较高的2nd , 3rd , 9th和12th元素向量。我们现在知道,如果我们有具有1次,第4,第5,第10,和第11个元素矢量高的值的输入图像。我们可以把它归类为X类似地,如果我们的输入图像具有其具有第2次第3次第9和第12元素矢量值高,使我们可以将其安排列表
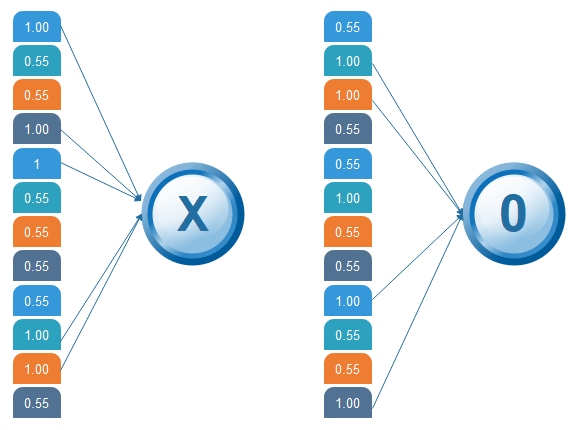
然后第1,第4,第5,第10,和第11的值是高的,我们可以将图像分类为“X”。其他字母的概念也相似-当某些值按其原样排列时,它们可以映射为实际字母或我们需要的数字
将输入向量与X进行比较
训练完成后,“ X”和“ O”的整个过程。然后,我们得到这个12元素向量,所有这些值都有0.9、0.65,然后我们如何将其分类为X或O。我们将其与X和O的列表进行比较,因此,如果我们注意到X和O有两个不同的列表,我们将在上一张幻灯片中得到文件。我们正在将与X一起到达的这个新输入图像列表进行比较。和O.首先我们来比较,与X以及现在的X有一定的价值,这将是更高,不过1日4日5日10日和11日的价值。因此,我们将对它们求和,得到5 = 1 + 1 + 1 + 1 + 1 + 1乘以1得到5,我们将对图像矢量的相应值求和。因此,第一个值是0.9,然后第四个值是0.87,第五个值是0.96,第10个值是0.89,第11个值是0.94,所以这些值的总和为4.56,然后除以5,得到0.9 。
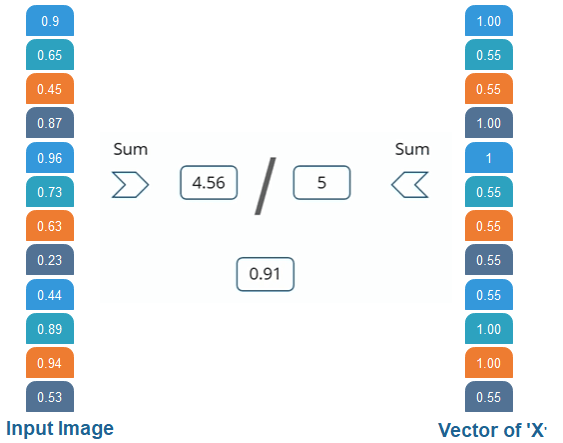
我们正在将输入向量与0进行比较。
对于X,我们对O做相同的过程,我们注意到2 nd 3 rd 9 th ,第12个元素矢量值很高。因此,当我们对这些值求和时,我们得到4,而对输入图像的相应值求和时,我们得到4。我们得到2.07,当我们将其除以4时得到0.51 。
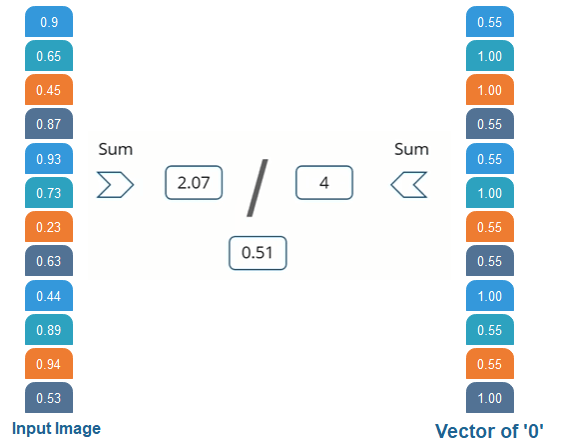
结果
现在,我们注意到0.91是与0.5相比更高的值,因此我们将输入图像与X的值进行了比较,得到的值高于然后将输入图像与4的值进行比较后得到的值。输入图像被分类为X。

CNN用例
脚步:
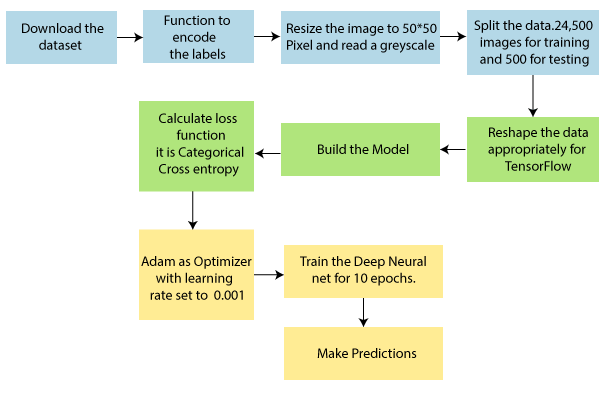
在这里,一旦训练完成,我们将在不同类型的狗和猫图像上训练我们的模型。我们将提供它将分类输入的是狗还是猫。
