- jMeter-函数
- jMeter-函数(1)
- jMeter教程
- jMeter教程(1)
- JMeter mac (1)
- 讨论jMeter(1)
- 讨论jMeter
- jMeter-环境
- jMeter-环境(1)
- jMeter-概述
- JMeter 中的线程组
- JMeter 中的线程组(1)
- JMeter mac - 任何代码示例
- JMeter 中的断言(1)
- JMeter 中的断言
- jMeter-侦听器(1)
- jMeter-侦听器
- JMeter 中的监听器(1)
- JMeter 中的监听器
- Apache JMeter – 简介
- Apache JMeter – 简介(1)
- jMeter-有用的资源(1)
- jMeter-有用的资源
- JMeter 中的定时器(1)
- JMeter 中的定时器
- 如何在 Linux 上安装 Apache JMeter?
- jMeter-测试计划元素
- jMeter-测试计划元素(1)
- jmeter get var - Java (1)
📅 最后修改于: 2020-11-13 05:51:23 🧑 作者: Mango
正则表达式用于根据模式搜索和操作文本。 JMeter通过包含模式匹配软件Apache Jakarta ORO来解释在整个JMeter测试计划中使用的正则表达式或模式的形式。
通过使用正则表达式,当我们创建或增强测试计划时,我们当然可以节省大量时间并获得更大的灵活性。正则表达式提供了一种在无法或很难预测结果时从页面获取信息的简单方法。
使用表达式的标准用法示例是从服务器响应中获取会话ID。如果服务器返回唯一的会话密钥,我们可以使用加载脚本中的表达式轻松获取它。
要在测试计划中使用正则表达式,您需要使用JMeter的正则表达式提取器。您可以在测试计划的任何组件中放置正则表达式。
值得强调的是包含和匹配之间的区别,如在“响应声明”测试元素上使用的-
-
包含意味着正则表达式至少匹配目标的某些部分,因此“字母”“包含”“ ph.b”。因为正则表达式与子字符串“ phabe”匹配。
-
match表示正则表达式匹配整个目标。因此,“字母”与“ al。* t”“匹配”。
假设您要匹配网页的以下部分-
name = "file" value = "readme.txt"
并且您要提取readme.txt。合适的正则表达式为-
name = "file" value = "(.+?)">
上面的特殊字符是-
-
(和) -这些将匹配字符串的部分括起来
-
。 −匹配任何字符
-
+ -一或多次
-
? −第一场比赛成功后停止
创建JMeter测试计划
让我们通过编写测试计划来了解正则表达式提取器中的正则表达式的使用-后处理器元素。该元素使用正则表达式从当前页面提取文本,以标识所需元素所符合的文本模式。
首先,我们编写一个HTML页面,其中包含人员列表及其电子邮件ID。我们将其部署到我们的tomcat服务器。 html(index.html)的内容如下-
Sr.No
Field & Description
1
Reference Name
The name of the variable in which the extracted test will be stored (refname).
2
Regular Expression
The pattern against which the text to be extracted will be matched. The text groups that will extracted are enclosed by the characters '(' and ')'. We use '.+?' to indicate a single instance of the text enclosed by the ..
(+?) \s*(+?) \s*
3
Template
Each group of extracted text placed as a member of the variable Person, following the order of each group of pattern enclosed by '(' and ')'. Each group is stored as refname_g#, where refname is the string you entered as the reference name, and # is the group number. $1$ to refers to group 1, $2$ to refers to group 2, etc. $0$ refers to whatever the entire expression matches. In this example, the ID we extract is maintained in Person_g1, while the Name value is stored in Person_g2.
4
Match No.
Since we plan to extract only the second occurrence of this pattern, matching the second volunteer, we use value 2. Value 0 would make a random matching, while a negative value needs to be used with the ForEach Controller.
5
Default
If the item is not found, this will be the default value. This is an optional field. You may leave it blank.
在将其部署到tomcat服务器上时,此页面将类似于以下屏幕截图所示-
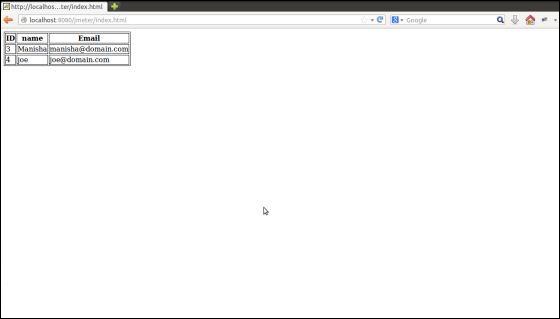
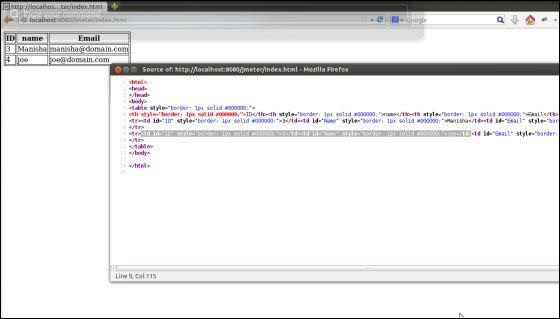
在我们的测试计划中,我们将在上面的人员列表页面中看到的人员表的第一行中选择人员。要获取此人的ID,首先让我们确定在第二行中找到该人的模式。
从下面的快照中可以看出,第二个人的ID被
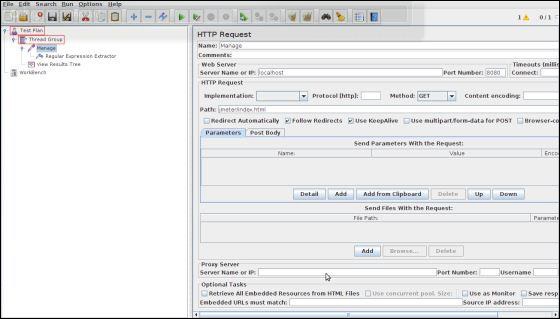
启动JMeter,添加线程组Test Plan→添加→线程(用户)→线程组。
接下来添加一个采样器HTTP请求,选择测试计划,右键单击添加→采样器→HTTP请求,然后输入详细信息,如下所示-
-
名称-管理
-
服务器名称或IP-本地主机
-
端口号-8080
-
协议-我们将其保留为空白,这意味着我们希望使用HTTP作为协议。
-
路径-jmeter / index.html
接下来,添加一个正则表达式提取器。选择HTTP请求采样器(管理),右键单击添加→后处理器→正则表达式提取器。
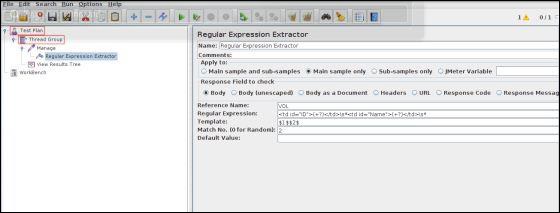
下表提供了上述屏幕快照中使用的字段的描述-
| 序号 | 栏位说明 | |||
|---|---|---|---|---|
| 1个 |
参考名称 提取的测试将存储在其中的变量的名称(refname)。 |
|||
| 2 |
正则表达式 要提取的文本将与之匹配的模式。将提取的文本组用字符“(”和“)”括起来。我们使用’。+?’表示由 | .. 标记括起来的单个文本实例。在我们的示例中,表达式为- | (+?) \ s * | (+?) \ s * |
| 3 |
模板 每组提取的文本作为变量Person的成员放置,并遵循由“(”和“)”包围的每组模式的顺序。每个组都存储为refname_g#,其中refname是您输入的作为参考名称的字符串,而#是组号。 $ 1 $表示组1,$ 2 $表示组2,依此类推。$ 0 $表示整个表达式匹配的内容。在此示例中,我们提取的ID保留在Person_g1中,而Name值存储在Person_g2中。 |
|||
| 4 |
比赛编号 由于我们计划仅提取该模式的第二次出现(与第二位志愿者匹配),因此我们使用值2。值0将进行随机匹配,而ForEach控制器需要使用负值。 |
|||
| 5 |
默认 如果找不到该项目,则它将是默认值。这是个可选的选项。您可以将其留空。 |
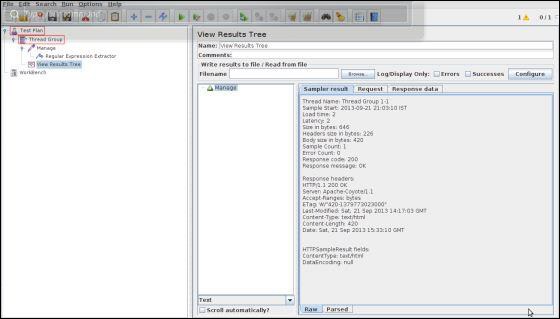
添加一个侦听器以捕获此测试计划的结果。右键单击线程组,然后选择添加→侦听器→查看结果树选项以添加侦听器。
将测试计划另存为reg_express_test.jmx并运行测试。输出将成功,如以下屏幕截图所示-