- SQL 面试问题(1)
- SQL面试问题
- SQL面试问题(1)
- SQL 面试问题 | 2套
- SQL 面试问题
- SQL面试问题
- SQL 面试问题 | 2套(1)
- SQL面试问题
- SQL 面试问题 |设置 1(1)
- SQL 面试问题 |设置 1
- F#面试问题(1)
- F#面试问题
- 面试问题
- SQL Server面试问题(1)
- SQL Server面试问题
- JavaScript面试问题(1)
- JavaScript面试问题(1)
- JavaScript面试问题
- JavaScript面试问题
- 高级 SQL 面试问题
- 高级 SQL 面试问题(1)
- PL SQL面试问题(1)
- PL / SQL面试问题
- PL / SQL面试问题
- PL SQL面试问题(1)
- PL / SQL面试问题
- PL / SQL面试问题
- GIT面试问题(1)
- GIT面试问题
📅 最后修改于: 2020-11-16 01:19:36 🧑 作者: Mango

SQL面试题
在许多公司中都提供了SQL面试问题和答案。对于PL / SQL面试问题,请访问我们的下一页。
1)什么是SQL?
SQL代表结构化查询语言。 SQL是一种标准查询语言,用于维护关系数据库并对数据执行许多不同的数据操作操作。 SQL最初是在1970年发明的。它是一种用于数据库创建,删除,获取行和修改行等的数据库语言。有时它被称为“续集”。
2)SQL何时出现?
它于1974年出现。SQL是维护关系数据库的常用语言之一。 SQL。 1986年,SQL成为1987年成为美国国家标准协会(ANSI)和ISO(国际标准化组织)的标准。
3)SQL的用法是什么?
- SQL负责维护关系数据和数据库中存在的数据结构。
- 对数据库执行查询
- 从数据库检索数据
- 在数据库中插入记录
- 更新数据库中的记录
- 从数据库中删除记录
- 创建新数据库
- 在数据库中创建新表
- 在数据库中创建视图
- 对数据库执行复杂的操作。
4)SQL是否支持编程?
SQL是指标准查询语言,实际上不是编程语言。 SQL没有循环,条件语句,逻辑操作,除了数据操作外,它不能用于其他任何用途。它的用法类似于命令(查询)语言来访问数据库。 SQL的主要目的是检索,操纵,更新和执行复杂的操作,例如对数据库中存在的数据进行联接。
5)什么是SQL的子集?
SQL有三个重要的子集:
- 数据定义语言(DDL):DDL用于定义数据结构,它由诸如CREATE,ALTER,DROP等命令组成。
- 数据操作语言(DML):DML用于操作数据库中已经存在的数据。此类别中的命令是SELECT,UPDATE,INSERT等。
- 数据控制语言(DCL):DCL用于控制对数据库中数据的访问,并包含诸如GRANT,REVOKE之类的命令。
6)什么是数据定义语言?
数据定义语言(DDL)是数据库的子集,它在要创建数据库的初始阶段定义数据库的数据结构。它由以下命令组成:CREATE,ALTER和DELETE数据库对象,例如模式,表,视图,序列等。
7)什么是数据处理语言?
数据操纵语言使用户能够检索和操纵数据。用于执行以下操作。
- 通过INSERT命令将数据插入数据库。
- 通过SELECT命令从数据库中检索数据。
- 通过UPDATE命令更新数据库中的数据。
- 通过DELETE命令从数据库中删除数据。
8)什么是数据控制语言?
数据控制语言使您可以控制对数据库的访问。 DCL是数据库的唯一子集,它决定哪个用户在什么时间点应访问数据库的哪一部分。它包括两个命令GRANT和REVOKE。
授予:授予特定用户执行特定任务的权限
撤消:取消以前拒绝或授予的权限。
9)什么是数据库中的表和字段?
表格是一组有组织的数据。它具有行和列。这里的行是指表示简单数据项的元组,而列是特定行中存在的数据项的属性。列可以分类为垂直,行是水平。
一个表包含指定数量的称为字段的列,但可以具有任意数量的行,称为记录。因此,数据库表中的列称为字段,它们代表记录中实体的属性或特征。
10)什么是主键?
主键是唯一地指定行的字段或字段组合。主键是一种特殊的唯一键。主键值不能为NULL。例如,社会保险号可以视为任何人的主键。
11)什么是外键?
将外键指定为与另一个表的主键相关的键。需要通过将外键与另一个表的主键引用来在两个表之间创建关系。外键就像表之间的交叉引用一样,因为它引用其他表的主键,而主键-外键关系是非常关键的关系,因为它有时维护数据库的ACID属性。
12)什么是唯一密钥?
唯一键约束唯一地标识数据库中的每个记录。此键为列或列集提供唯一性。
唯一键不能接受重复的值。
唯一键只能接受Null值。
13)主键和唯一键有什么区别?
主键和唯一键都是SQL的基本约束,但是它们之间的差别很小
主键带有唯一值,但主键的字段不能为Null,另一方面,唯一键也带有唯一值,但可以具有单个Null值字段。
14)什么是数据库?
数据库是数据的组织形式。数据库是一个电子系统,它使数据访问,数据处理,数据检索,数据存储和数据管理变得非常容易和结构化。由于其易于访问且易于操作,几乎每个组织都使用该数据库来存储数据。数据库提供了对数据的完美访问,使我们能够执行所需的任务。
数据库也称为数据的结构形式。由于这种结构化格式,您可以非常轻松地访问数据。
15)什么是DBMS?
DBMS代表数据库管理系统。这是一个用于控制它们的程序。就像文件管理器一样,它管理数据库中的数据,而不是将其保存在文件系统中。
数据库管理系统是数据库和用户之间的接口。它使数据检索,数据访问更加容易。
数据库管理系统是一种软件,它为我们提供了在几乎没有时间的情况下使用简单查询执行诸如创建,维护和使用数据库数据之类的操作的能力。
没有数据库管理系统,用户访问数据库的数据将更加困难。
16)有哪些不同类型的数据库管理系统?
有四种类型的数据库:
- 分层数据库(DBMS)
- 关系数据库(RDBMS)
- 网络数据库(IDMS)
- 面向对象的数据库
RDBMS易于访问并且支持复杂查询,因此是最常用的数据库之一。
17)什么是RDBMS?
RDBMS代表关系数据库管理系统。它是一个基于关系模型的数据库管理系统。 RDBMS将数据存储到表集合中,并在需要时使用关系运算符轻松链接这些表。它使您可以使用关系运算符来操纵存储在表中的数据。关系数据库管理系统的示例包括Microsoft Access,MySQL,SQLServer,Oracle数据库等。
18)什么是数据库中的规范化?
标准化用于通过组织数据库的字段和表来最大程度地减少冗余和依赖性。
数据库规范化有一些规则,通常称为Normal From,它们是:
- 第一范式(1NF)
- 第二范式(2NF)
- 第三范式(3NF)
- 博伊斯·科德范式(BCNF)
使用这些步骤,可以消除数据库中数据的冗余,异常和不一致。
19)规范化的主要用途是什么?
规范化主要用于添加,删除或修改可在单个表中完成的字段。规范化的主要用途是删除冗余并删除插入,删除和更新干扰。规范化将表分成多个小分区,然后使用不同的关系将它们链接在一起,从而避免了冗余的机会。
20)不执行数据库规范化的缺点是什么?
主要缺点是:
- 数据库中出现冗余术语,这会浪费磁盘空间。
- 由于冗余术语,id可能还会发生冲突,id将在一个表的数据中进行任何更改,但不会在另一表的同一数据中进行任何更改,因此将发生不一致,这将导致维护问题并影响ACID属性。
21)什么是不一致的依赖关系?
不一致的依赖性是指访问特定数据的困难,因为到达数据的路径可能丢失或损坏。不一致的依赖关系将导致用户在错误的表中搜索数据,随后将错误作为输出。
22)什么是数据库中的非规范化?
非规范化用于从较高或较低的标准数据库形式访问数据。它还通过合并相关表中的数据将冗余处理到表中。非规范化将所需的冗余项添加到表中,这样我们就可以避免使用复杂的联接和许多其他复杂的操作。归一化并不意味着不会进行归一化,而是去归一化过程在归一化过程之后进行。
23)SQL中可用的运算符类型是什么?
运算符是为执行特定操作而保留的特殊关键字或特殊字符,在SQL查询中使用。 SQL中使用三种类型的运算符:
- 算术运算运算符:加法(+),减法(-),乘法(*),除法(/)等。
- 逻辑运算符:ALL,AND,ANY,ISNULL,EXISTS,BETWEEN,IN,LIKE,NOT或UNIQUE。
- 运算符:=,!=,<>,<,>,<=,> = 、! <,!>
24)SQL中的视图是什么?
视图是一个虚拟表,其中包含表内的数据子集。视图最初不存在,并且占用的空间更少。一个视图可以合并来自一个或多个表的数据,并且取决于关系。视图用于在SQL Server中应用安全性机制。数据库的视图是可搜索的对象,我们可以像在表中那样使用查询来搜索视图。
25)什么是SQL中的索引?
SQL索引是减少查询成本的媒介,因为查询的高成本将导致查询性能下降。索引用于提高性能,并允许从表中更快地检索记录。索引减少了我们需要访问以找到特定数据页面的数据页面的数量。索引还具有唯一的值,这意味着无法复制索引。索引为每个值创建一个条目,并且检索数据会更快。例如,假设您有一本书载有国家/地区的详细信息,并且想要查找有关印度的信息,而不是为什么要浏览该书的每一页,您都可以直接转到索引,然后从索引中查找可以转到提供有关印度的所有信息的特定页面。
26)SQL中有哪些不同类型的索引?
SQL中有三种类型的索引:
- 唯一索引
- 聚集索引
- 非聚集索引
- 位图索引
- 正常指数
- 综合指数
- B树索引
- 基于函数的索引
27)什么是唯一索引?
唯一索引:
为了创建唯一索引,用户必须检查列中的数据,因为当表的任何列具有唯一值时都使用唯一索引。如果列是唯一索引的,则此索引不允许字段具有重复的值。定义主键时,可以自动应用唯一索引。
28)什么是SQL中的聚簇索引?
聚集索引:
聚簇索引用于对表的物理顺序进行重新排序,并根据键值进行搜索。每个表只能有一个聚集索引。聚集索引是生成主键时唯一自动创建的索引。如果需要在表中进行适度的数据修改,则首选聚集索引。
29)什么是SQL中的非聚集索引?
非聚集索引:
创建非聚集索引的原因是搜索数据。我们都知道聚簇索引是自动生成的,但会在生成主键时创建非聚簇索引,但是在查询中使用多个联接条件和各种过滤器时,会创建非聚簇索引。非聚集索引不会更改表的物理顺序,并保持数据的逻辑顺序。每个表可以具有999个非聚集索引。
30)SQL,MySQL和SQL Server有什么区别?
SQL或结构化查询语言是一种用于与关系数据库进行通信的语言。它提供了一种操作和创建数据库的方法。另一方面,MySQL和Microsoft的SQL Server都是使用SQL作为其标准关系数据库语言的关系数据库管理系统。
MySQL是免费的,因为它是开源的,而SQL Server不是开源软件。
31)SQL和PL / SQL有什么区别?
SQL或结构化查询语言是一种用于与关系数据库进行通信的语言。它提供了一种操作和创建数据库的方法。另一方面,PL / SQL是SQL的方言,用于增强SQL的功能。它是由Oracle公司在90年代初期开发的。它添加了SQL编程语言的过程功能。
在SQL中,单个查询一次执行,而在PL / SQL中,整个代码块一次执行。
另一方面,SQL就像我们需要显示的数据源一样。PL/ SQL提供了一个平台,可以在其中显示SQL数据的SQL。
SQL语句可以嵌入到PL / SQL中,但是PL / SQL语句不能嵌入到SQL中,因为SQL不支持任何编程语言和关键字。
32)是否可以使用列别名对列进行排序?
是。您可以使用ORDER BY中的列别名而不是WHERE子句进行排序。
33)SQL中的聚集索引和非聚集索引有什么区别?
SQL中的索引主要有两种类型,即聚集索引和非聚集索引。从SQL性能的角度来看,这两个索引之间的差异非常重要。
- 一个表只能有一个聚集索引,但是它可以有许多非聚集索引。 (大约250个)。
- 聚集索引确定如何在表中物理存储数据。聚簇索引将数据存储在集群中,相关数据存储在一起,因此数据检索变得简单。
- 聚簇索引存储数据信息和数据本身,而非聚簇索引仅存储信息,然后它将引用您访问存储在聚簇数据中的数据。
- 从聚簇索引中读取要比从同一表中从非聚簇索引中读取要快得多。
- 聚集索引根据其键值对表或视图中的数据行进行排序并将其存储,而非聚集索引的结构则与数据行分开。
34)什么是显示当前日期的SQL查询?
SQL中有一个名为GetDate()的内置函数,该函数用于返回当前时间戳。
35)哪些是最常用的SQL连接?
最常用的SQL连接是INNER JOIN和LEFT OUTER JOIN和RIGHT OUTER JOIN。
36)SQL中的联接有哪些不同类型?
联接用于合并两个表或从表中检索数据。这取决于表之间的关系。
以下是SQL中最常用的联接:
内联接:内联接有三种类型:
- Theta加盟
- 自然加入
- 等参
外部联接:外部联接分为三种类型:
- 右外连接
- 左外连接
- 完全外部联接
37)什么是SQL中的内部联接?
内部联接:
当表之间至少有一个行匹配时,内部联接将返回行。 INNER JOIN关键字联接来自两个表的匹配记录。
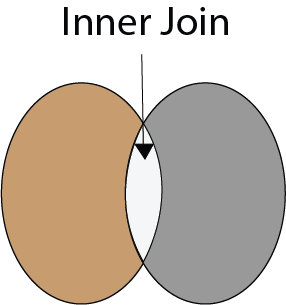
内部联接
38)什么是SQL中的右联接?
正确加入:
右连接用于检索表与右手侧表的所有行之间共有的行。即使左侧表中没有匹配项,它也会从右侧表中返回所有行。
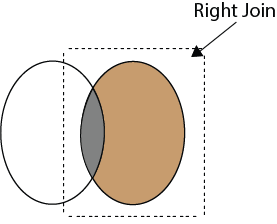
正确加入
39)什么是SQL中的Left Join?
左联接:
左联接用于检索表与左侧表的所有行之间共有的行。即使右侧表上没有匹配项,它也会从左侧表返回所有行。
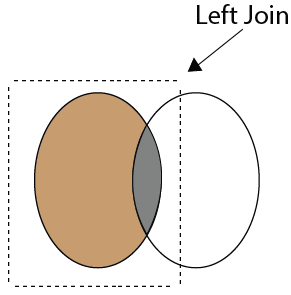
左联接
40)什么是SQL中的完全连接?
完全加入:
当任一表中有匹配的行时,全联接返回行。这意味着它将返回左侧表中的所有行以及右侧表中的所有行。
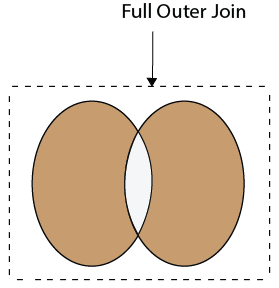
全外连接
41)什么是SQL中的“ TRIGGER”?
- 当对特定表执行插入,更新或删除命令时,触发器可让您执行一批SQL代码,因为据说TRIGGER是每当通过查询给出插入,更新或删除等命令时执行的一组操作。
- 将这些命令提供给系统后,称触发器已激活。
- 触发器是特定类型的存储过程,已定义为在位或在数据修改后自动执行。
- 使用CREATE TRIGGER语句生成触发器。
42)什么是自连接?自连接的要求是什么?
自联接通常对于将层次结构转换为平面结构非常有用。它用于将表联接到自身,就像第二个表一样。
43)SQL中的集合运算符是什么?
包含集合操作的SQL查询称为复合查询。
Union,Union All,Intersect或Minus运算符是SQL中使用的集合运算符。
44)BETWEEN和IN条件运算符之间有什么区别?
BETWEEN运算符用于根据一系列值显示行。值也可以是数字,文本和日期。 BETWEEN运算符为我们提供了在特定范围之间发生的所有值的计数。
IN条件运算符用于检查特定值集中包含的值。当我们有多个值可供选择时,将使用IN运算符。
45)什么是约束?告诉我它的各个级别。
约束是应用于表列的规则和规定,可强制您存储有效数据并防止用户存储不相关的数据。有两个级别:
- 列级约束
- 表级约束
46)编写SQL查询以查找以'A'开头的员工姓名?
SELECT * FROM Employees WHERE EmpName like 'A%'
47)编写一个SQL查询,以从名为employee_table的表中获取雇员的第三高薪。
SELECT TOP 1 salary
FROM (
SELECT TOP 3 salary
FROM employee_table
ORDER BY salary DESC ) AS emp
ORDER BY salary ASC;
48)SQL中的DELETE和TRUNCATE语句有什么区别?
SQL DELETE和TRUNCATE语句之间的主要区别如下:
| No. | DELETE | TRUNCATE |
|---|---|---|
| 1) | DELETE is a DML command. | TRUNCATE is a DDL command. |
| 2) | We can use WHERE clause in DELETE command. | We cannot use WHERE clause with TRUNCATE |
| 3) | DELETE statement is used to delete a row from a table | TRUNCATE statement is used to remove all the rows from a table. |
| 4) | DELETE is slower than TRUNCATE statement. | TRUNCATE statement is faster than DELETE statement. |
| 5) | You can rollback data after using DELETE statement. | It is not possible to rollback after using TRUNCATE statement. |
49)数据库中的ACID属性是什么?
ACID属性用于确保在数据库系统中可靠地处理数据事务。
数据的单个逻辑操作称为事务。
ACID是原子性,一致性,隔离性,耐久性的首字母缩写。
原子性:要求每笔交易全部或全部。这意味着如果事务的一部分失败,则整个事务都会失败,并且数据库状态将保持不变。
一致性:一致性属性可确保数据必须符合所有验证规则。简单来说,您可以说您的事务永远都不会离开数据库而不完成其状态。
隔离:此属性确保不应满足执行的并发属性。提供隔离的主要目标是并发控制。
耐用性:耐用性只是意味着一旦事务被提交,它将保持不变,甚至会导致断电,崩溃或错误。
50)NULL值,零和空格之间有什么区别?
回答:NULL值不等于零或空格。 NULL值是“不可用,未分配,未知或不适用”的值。另一方面,零是一个数字,空格被当作字符。
NULL值也可以视为未知值和缺失值,但是零和空格与NULL值不同。
51)SQL函数的用途是什么?
函数是测量值,不能对SQL Server创建永久的环境更改。 SQL函数用于以下目的:
- 对数据执行计算
- 修改单个数据项
- 操纵输出
- 格式化日期和数字
- 转换数据类型
52)您对案例操作功能有什么了解?
大小写处理功能是将数据从已存储在表中的状态转换为大写,小写或大小写混合的功能。
案例操作函数几乎可以在SQL语句的每个部分中使用。
大小写操作函数通常在需要搜索数据时使用,并且您不知道要查找的数据是小写还是大写。
53)SQL中有哪些不同的大小写处理函数?
SQL中有三种大小写处理函数:
- 小写:将字符转换为小写。
- 大写:将字符转换为大写。
- INITCAP:将每个单词的缩写的字符值转换为大写。
54)解释字符操作功能吗?
字符处理功能被用来改变,提取物,改变该字符的字符串。
应该将一个或多个字符和单词传递到函数,然后该函数将对这些单词执行其操作。
55)SQL中哪些字符处理函数不同?
- CONCAT:将两个或多个值连接在一起。
- SUBSTR:用于提取特定长度的字符串。
- LENGTH:以数字值返回字符串的长度。
- INSTR:找到指定字符的确切数字位置。
- LPAD:将左侧字符值填充为右对齐值。
- RPAD:将右侧字符值填充为左对齐值。
- TRIM:从开头,结尾或开头和结尾两者中删除所有定义的字符。
- REPLACE:用字符的其它序列替换字符的特定序列。
56)NVL()函数的用法是什么?
NVL()函数用于将NULL值转换为另一个值。 NVL()函数在Oracle中使用,而在SQL和MySQL服务器中则不使用。
代替NVL()函数, MySQL具有IFNULL()和SQL Server具有ISNULL()函数。
57)哪个函数用于返回SQL除法运算符中的余数?
MOD函数以除法运算返回余数。
58)COALESCE函数的语法和用途是什么?
COALESCE函数的语法:
COALESCE(exp1, exp2, .... expn)
COALESCE函数用于返回参数列表中给出的第一个非空表达式。
59)DISTINCT关键字的用途是什么?
DISTINCT关键字用于确保获取的值只是一个非重复值。 DISTINCT关键字用于SELECT DISTINCT,它总是从表的列中获取不同的(不同的)。