Python中的 HDF5 文件
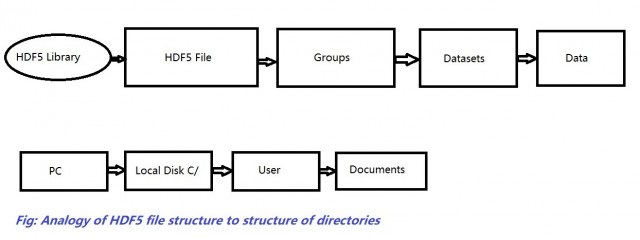
HDF5 文件代表 Hierarchical Data Format 5。它是一个开源文件,可以方便地存储大量数据。顾名思义,它将数据以分层结构存储在单个文件中。因此,如果我们想快速访问文件的特定部分而不是整个文件,我们可以使用 HDF5 轻松实现。此功能在普通文本文件中看不到,因此 HDF5 实际上是一个新概念,看起来很流行。要使用 HDF5,需要导入 numpy。一个重要的特性是它可以将元集附加到文件中的每个数据,从而提供强大的搜索和访问。让我们开始将 HDF5 安装到计算机上。
要安装 HDF5,请在终端中输入:
pip install h5py我们将使用一个名为 HDF5 Viewer 的特殊工具以图形方式查看这些文件并对其进行处理。要安装 HDF5 Viewer,请输入以下代码:
pip install h5pyViewer由于 HDF5 在 numpy 上工作,我们也需要在我们的机器上安装 numpy。
python -m pip install numpy在所有安装完成后,让我们看看如何写入 HDF5 文件。
注意:使用 HDF5 需要对 numpy 及其属性有基本的了解,因此必须熟悉 numpy 才能理解本文后面的代码。要了解有关 numpy 的更多信息,请单击此处。
我们将创建一个文件并在其中保存一个随机的 numpy 数组:
Python3
# Python program to demonstrate
# HDF5 file
import numpy as np
import h5py
# initializing a random numpy array
arr = np.random.randn(1000)
# creating a file
with h5py.File('test.hdf5', 'w') as f:
dset = f.create_dataset("default", data = arr)Python3
# open the file as 'f'
with h5py.File('test.hdf5', 'r') as f:
data = f['default']
# get the minimum value
print(min(data))
# get the maximum value
print(max(data))
# get the values ranging from index 0 to 15
print(data[:15])Python3
import numpy as np
import h5py
arr1 = np.random.randn(10000)
arr2 = np.random.randn(10000)
with h5py.File('test_read.hdf5', 'w') as f:
f.create_dataset('array_1', data = arr1)
f.create_dataset('array_2', data = arr2)Python3
with h5py.File('test_read.hdf5', 'r') as f:
d1 = f['array_1']
d2 = f['array_2']
data = d2[d1[:]>1]输出:
在上面的代码中,我们首先导入之前安装的模块。然后我们将变量 arr 初始化为一个 numpy 的随机数组,范围为 1000。
因此,我们可以说这个数组由大量数据组成。接下来,我们以“只写”属性打开文件。这意味着如果没有任何名为test.hdf5的文件,那么它将创建一个,否则它将删除(覆盖)现有文件的内容。在打开文件时,我们使用 with 而不是 open,因为与 open() 方法相比,它具有优势。如果使用 with 打开文件,我们不需要关闭文件 最后,我们使用 .create_dataset() 将变量dset设置为之前创建的数组。
我们现在将读取我们上面写的文件:
Python3
# open the file as 'f'
with h5py.File('test.hdf5', 'r') as f:
data = f['default']
# get the minimum value
print(min(data))
# get the maximum value
print(max(data))
# get the values ranging from index 0 to 15
print(data[:15])
输出:
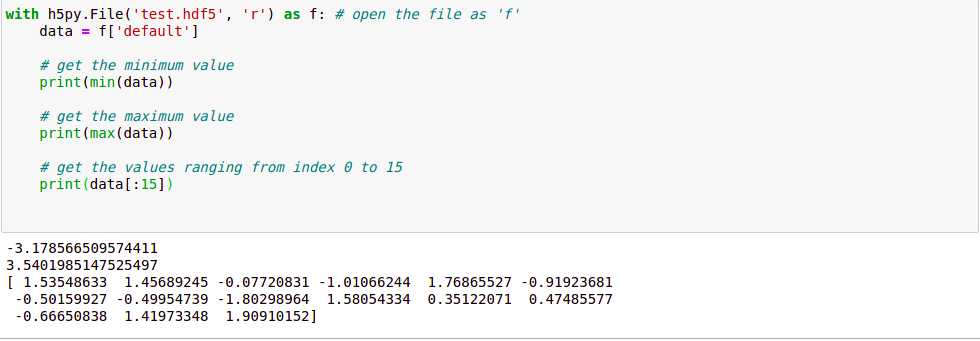
在这里,我们再次打开文件,但这次我们通过“只读”属性打开它,这样就不能对文件进行任何更改。我们将变量数据设置为我们存储在上一个文件中的数据。让我们看看输出:
似乎没有什么新鲜事。它只是一个数组,我们像在数组中一样打印出数字。但是,变量 data 不是数组。它实际上与数组非常不同。这是一个数据集。它不是将数据存储在 RAM 中,而是将其保存在计算机的硬盘驱动器中,从而像目录一样维护结构的层次结构:

当使用下面的行时
data = f['default']在前面的代码中,我们没有直接访问文件的内容,而是创建了一个指向我们内容的指针。让我们看看它的一个优点:
Python3
import numpy as np
import h5py
arr1 = np.random.randn(10000)
arr2 = np.random.randn(10000)
with h5py.File('test_read.hdf5', 'w') as f:
f.create_dataset('array_1', data = arr1)
f.create_dataset('array_2', data = arr2)
我们创建了两个数据集,但整个过程与以前相同。使用“w”属性创建一个名为“test_read.hdf5”的文件,它包含两个随机数数据集( array1和array2 )。现在假设我们只想读取array2的选择性部分。例如,我们要读取array2中对应于array1的值大于1的部分。如果我们使用传统的文本文件而不是 HDF5 文件,几乎不可能实现这一点。这正是我们看到了 HDF5 文件的强大之处:
Python3
with h5py.File('test_read.hdf5', 'r') as f:
d1 = f['array_1']
d2 = f['array_2']
data = d2[d1[:]>1]
我们使用[:]将数据集d1的副本创建到 RAM 中。我们这样做是因为无法将数据集(硬盘驱动器中的数据)与整数进行比较。
输出:

因此,我们得出结论,当我们处理大文件时,HDF5 文件是我们最好的工具,因为它允许我们选择性地读取和写入文件,否则会消耗大量内存和时间。