- 添加分区 mysql - C++ (1)
- 添加分区 mysql - C++ 代码示例
- 在分区 (1)
- 在分区 - 任何代码示例
- 固定分区和可变分区的区别
- 固定分区和可变分区的区别
- 在数组中查找分区点(1)
- 在数组中查找分区点
- 最大字符串分区(1)
- 最大字符串分区(1)
- 最大字符串分区
- 最大字符串分区
- 最大字符串分区
- 最大字符串分区(1)
- 固定分区和可变分区之间的区别
- 分区操作 Java (1)
- Redis-分区(1)
- Redis分区
- Redis-分区
- Redis分区(1)
- Cassandra中的表分区
- Cassandra 中的表分区
- Cassandra 中的表分区(1)
- 分区操作 Java 代码示例
- Python| K分区分组
- Python| K分区分组(1)
- 最小化数组分区,使得一个元素在每个分区中最多重复一次
- mysql (1)
- MYSQL (1)
📅 最后修改于: 2020-11-19 00:53:54 🧑 作者: Mango
MySQL中的分区是什么?
MySQL中的分区用于将表的行拆分或划分为位于不同位置的单独表,但是仍然将其视为单个表。它根据我们设置为需求的规则在整个文件系统中分配表数据的各个部分。我们为完成表数据的划分而设置的规则称为分区函数(模,线性或内部哈希函数等)。所选函数基于我们指定的分区类型,并采用用户提供的表达式作为其参数。用户表达式可以是列值,也可以是作用于列值的函数,具体取决于所使用的分区类型。
MySQL 8.0仅支持InnoDB和NDB存储引擎中的分区。其他存储引擎(例如MyISAM,MERGE,CSV和FEDERATED)不支持分区。
MySQL主要有两种分区形式:
1.水平分区
此分区根据我们的逻辑将一个表的行拆分为多个表。在水平分区中,每个表中的列数相同,但是无需保持相同的行数。它从物理上划分表,但在逻辑上将其视为一个整体。目前,MySQL仅支持此分区。
2.垂直分区
此分区将表拆分为多个表,而原始表中的列较少。它使用一个附加表来存储剩余的列。当前,MySQL不提供对此分区的支持。
分区的好处
以下是在MySQL中进行分区的好处:
- 它优化了查询性能。当我们查询表时,它仅扫描表中满足特定语句的部分。
- 可以将大量数据存储在一个表中,该表可以保存在单个磁盘或文件系统分区上。
- 它提供了更多控制来管理数据库中的数据。
我们如何在MySQL中对表进行分区?
我们可以使用CREATE TABLE或ALTER TABLE语句在MySQL中创建分区。以下是使用CREATE TABLE命令创建分区的语法:
CREATE TABLE [IF NOT EXISTS] table_name
(column_definitions)
[table_options]
[partition_options]
partition_options: It provides control on the table partition.
PARTITION BY
{ [LINEAR] HASH(exp)
| [LINEAR] KEY [ALGORITHM={1 | 2}] (colm_list)
| RANGE{(exp) | COLUMNS(colm_list)}
| LIST{(exp) | COLUMNS(colm_list)} }
[PARTITIONS num]
[SUBPARTITION BY
{ [LINEAR] HASH(exp)
| [LINEAR] KEY [ALGORITHM={1 | 2}] (colm_list) }
[SUBPARTITIONS num]
]
[(partition_definition [, partition_definition] ...)]
partition_definition: It defines each partition individually.
PARTITION part_name
[VALUES
{LESS THAN {(exp | val_list) | MAXVALUE}
|
IN (val_list)}]
[[STORAGE] ENGINE = engine_name]
[COMMENT = 'string' ]
[DATA DIRECTORY = 'data_dir']
[INDEX DIRECTORY = 'index_dir']
[MAX_ROWS = max_number_of_rows]
[MIN_ROWS = min_number_of_rows]
[TABLESPACE = tablespace_name]
[(subpartition_definition [, subpartition_definition] ...)]
subpartition_definition: It is optional.
SUBPARTITION logical_name
[[STORAGE] ENGINE [=] engine_name]
[COMMENT [=] 'string' ]
[DATA DIRECTORY [=] 'data_dir']
[INDEX DIRECTORY [=] 'index_dir']
[MAX_ROWS [=] max_number_of_rows]
[MIN_ROWS [=] min_number_of_rows]
[TABLESPACE [=] tablespace_name]
以下是使用ALTER TABLE命令创建分区的语法:
ALTER TABLE [IF EXISTS] tab_name
(colm_definitions)
[tab_options]
[partition_options]
MySQL分区的类型
MySQL主要有六种分区类型,如下所示:
- 范围分区
- 列表分区
- 栏分割
- 哈希分区
- 按键分区
- 子分区
让我们详细讨论每个分区。
MySQL RANGE分区
通过这种分区,我们可以基于落在指定范围内的列值对表的行进行分区。给定的范围始终是连续的形式,但不应彼此重叠,并且还使用VALUES LESS THAN运算符来定义范围。
在以下示例中,我们将创建一个名为“ Sales”的表,其中包含五列cust_id,name,store_id,bill_no,bill_date和amount。接下来,我们将根据需要通过几种方式使用范围来对该表进行分区。在这里,我们将使用bill_date列进行分区,然后使用PARTITION BY RANGE子句以四种方式对表的数据进行分区:
CREATE TABLE Sales ( cust_id INT NOT NULL, name VARCHAR(40),
store_id VARCHAR(20) NOT NULL, bill_no INT NOT NULL,
bill_date DATE PRIMARY KEY NOT NULL, amount DECIMAL(8,2) NOT NULL)
PARTITION BY RANGE (year(bill_date))(
PARTITION p0 VALUES LESS THAN (2016),
PARTITION p1 VALUES LESS THAN (2017),
PARTITION p2 VALUES LESS THAN (2018),
PARTITION p3 VALUES LESS THAN (2020));
接下来,我们需要将记录插入到表中,如下所示:
INSERT INTO Sales VALUES
(1, 'Mike', 'S001', 101, '2015-01-02', 125.56),
(2, 'Robert', 'S003', 103, '2015-01-25', 476.50),
(3, 'Peter', 'S012', 122, '2016-02-15', 335.00),
(4, 'Joseph', 'S345', 121, '2016-03-26', 787.00),
(5, 'Harry', 'S234', 132, '2017-04-19', 678.00),
(6, 'Stephen', 'S743', 111, '2017-05-31', 864.00),
(7, 'Jacson', 'S234', 115, '2018-06-11', 762.00),
(8, 'Smith', 'S012', 125, '2019-07-24', 300.00),
(9, 'Adam', 'S456', 119, '2019-08-02', 492.20);
为了验证记录,我们将执行以下语句:
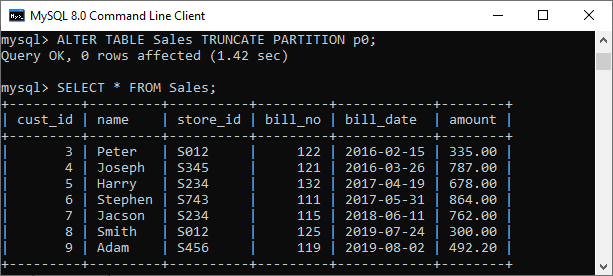
SELECT * FROM Sales;
我们可以看到记录已成功插入到Sales表中。

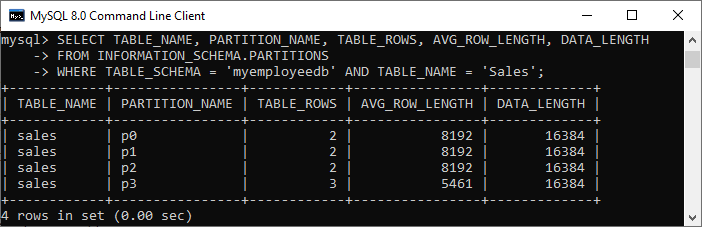
我们可以使用以下查询查看由CREATE TABLE语句创建的分区:
SELECT TABLE_NAME, PARTITION_NAME, TABLE_ROWS, AVG_ROW_LENGTH, DATA_LENGTH
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA = 'myemployeedb' AND TABLE_NAME = 'Sales';
我们将获得以下输出,其中成功创建了四个分区:
删除MySQL分区
有时我们的表包含分区表中无用的数据。在这种情况下,我们可以根据需要删除单个或多个分区。以下语句用于从表Sales的分区p0中删除所有行:
ALTER TABLE Sales TRUNCATE PARTITION p0;
成功执行后,我们可以看到从表中删除了这两行。
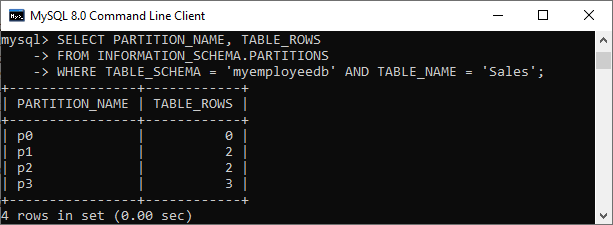
我们可以使用以下查询来验证分区表:
SELECT PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA = 'myemployeedb' AND TABLE_NAME = 'Sales';
在输出中,我们可以看到分区p0不包含任何行。
MySQL LIST分区
它与范围分区相同。在此,根据与一组离散值列表之一而不是一组连续值范围匹配的列来定义和选择分区。它由PARTITION BY LIST(exp)子句执行。 exp是返回整数值的表达式或列值。 VALUES IN(value_lists)语句将用于定义每个分区。
在下面的示例中,假设我们有12家门店根据其区域分布在四个特许经营店中。该表对其进行了更清晰的说明:
| Region | Store ID Number |
|---|---|
| East | 101, 103, 105 |
| West | 102, 104, 106 |
| North | 107, 109, 111 |
| South | 108, 110, 112 |
我们可以对上表进行分区,其中存储行的行属于同一区域,并将存储在同一分区中。以下语句使用LIST分区将存储区排列在同一区域中,如下所示:
CREATE TABLE Stores (
cust_name VARCHAR(40),
bill_no VARCHAR(20) NOT NULL,
store_id INT PRIMARY KEY NOT NULL,
bill_date DATE NOT NULL,
amount DECIMAL(8,2) NOT NULL
)
PARTITION BY LIST(store_id) (
PARTITION pEast VALUES IN (101, 103, 105),
PARTITION pWest VALUES IN (102, 104, 106),
PARTITION pNorth VALUES IN (107, 109, 111),
PARTITION pSouth VALUES IN (108, 110, 112));
成功执行后,将给出以下输出;

MySQL HASH分区
此分区用于基于预定义数量的分区来分发数据。换句话说,它将表拆分为用户定义的表达式返回的值。它主要用于将数据均匀分布到分区中。它通过PARTITION BY HASH(expr)子句执行。在这里,我们可以基于要散列的column_name和表划分为的分区数指定列值。
该语句用于使用CREATE TABLE命令创建表Store,并在store_id列上使用哈希将其分为四个分区:
CREATE TABLE Stores (
cust_name VARCHAR(40),
bill_no VARCHAR(20) NOT NULL,
store_id INT PRIMARY KEY NOT NULL,
bill_date DATE NOT NULL,
amount DECIMAL(8,2) NOT NULL
)
PARTITION BY HASH(store_id)
PARTITIONS 4;
注:如果不使用PARTITIONS子句,则默认情况下,分区数将为1。如果未使用PARTITIONS关键字指定数字,则将引发错误。
MySQL COLUMN分区
这种分区使我们可以使用分区键中的多个列。这些列的目的是将行放在分区中,并确定将验证哪个分区匹配行。它主要分为两种类型:
- RANGE列分区
- LIST列分区
它们为使用非整数列定义范围或值列表提供支持。它们支持以下数据类型:
- 所有整数类型: TINYINT,SMALLINT,MEDIUMINT,INT(INTEGER)和BIGINT。
- 字符串类型: CHAR,VARCHAR,BINARY和VARBINARY。
- DATE和DATETIME数据类型。
范围列分区:与范围分区相似,只是有一个区别。它使用基于各种列的范围作为分区键来定义分区。定义的范围是非整数类型的列类型。
以下是“范围列分区”的语法。
CREATE TABLE tab_name
PARTITIONED BY RANGE COLUMNS(colm_list) (
PARTITION part_name VALUES LESS THAN (val_list)[,
PARTITION parti_name VALUES LESS THAN (val_list)][,
...]
)
colm_list: It is a list of one or more columns.
colm_name[, colm_name][, ...]
val_list: It is a list of values that supplied for each partition definition and have the same number of values as of columns.
val[, val][, ...]
让我们用下面的例子来理解它。
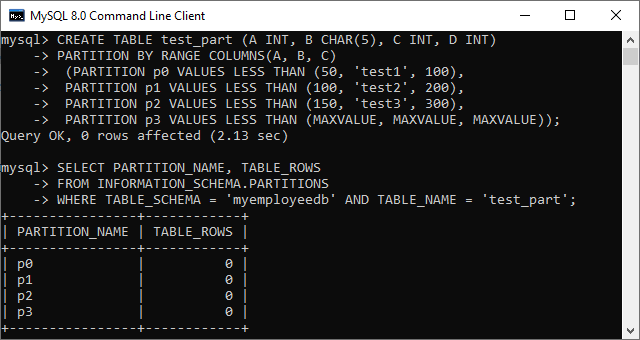
CREATE TABLE test_part (A INT, B CHAR(5), C INT, D INT)
PARTITION BY RANGE COLUMNS(A, B, C)
(PARTITION p0 VALUES LESS THAN (50, 'test1', 100),
PARTITION p1 VALUES LESS THAN (100, 'test2', 200),
PARTITION p2 VALUES LESS THAN (150, 'test3', 300),
PARTITION p3 VALUES LESS THAN (MAXVALUE, MAXVALUE, MAXVALUE));
在此示例中,表“ test_part”包含四个列A,B,C和D。我们在分区中使用了前三列,顺序为A,B,C。而且,每个列表值都用于定义一个分区,该分区包含三个与INT,CHAR和INT顺序相同的值。执行后,我们将获得以下输出,并通过SELECT语句成功验证。
列表列分区:将一个或多个列的列表作为分区键。它使我们能够使用除整数类型以外的各种类型的列作为分区列。在此分区中,我们可以使用String数据类型,DATE和DATETIME列。
以下示例对其进行了更清晰的说明。假设一家公司在三个城市有许多代理商用于营销目的。我们可以将其组织如下:
| City | Marketing Agents |
|---|---|
| New York | A1, A2, A3 |
| Texas | B1, B2, B3 |
| California | C1, C2, C3 |
以下语句使用“列表列分区”来组织代理:
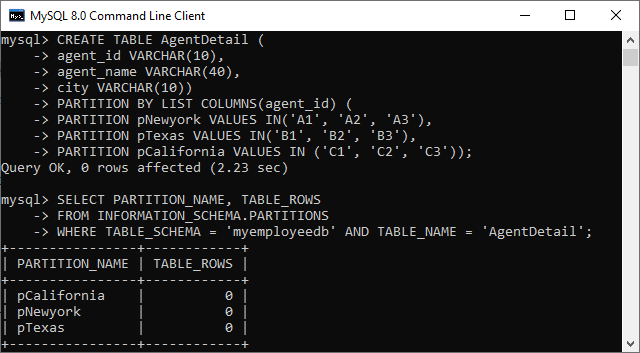
CREATE TABLE AgentDetail (
agent_id VARCHAR(10),
agent_name VARCHAR(40),
city VARCHAR(10))
PARTITION BY LIST COLUMNS(agent_id) (
PARTITION pNewyork VALUES IN('A1', 'A2', 'A3'),
PARTITION pTexas VALUES IN('B1', 'B2', 'B3'),
PARTITION pCalifornia VALUES IN ('C1', 'C2', 'C3'));
成功执行后,我们将获得如下输出:
MySQL密钥分区
它类似于HASH分区,其中的哈希分区使用用户指定的表达式,而MySQL服务器为密钥提供了哈希函数。如果我们使用其他存储引擎,则MySQL服务器将使用通过使用PARTITION BY KEY子句执行的内部哈希函数。在这里,我们将使用KEY而不是只能接受零个或多个列名列表的HASH。
如果该表包含一个PRIMARY KEY,并且我们没有为分区指定任何列,则将主键用作分区键。以下示例对其进行了更清晰的说明:
CREATE TABLE AgentDetail (
agent_id INT NOT NULL PRIMARY KEY,
agent_name VARCHAR(40)
)
PARTITION BY KEY()
PARTITIONS 2;
如果表具有唯一键但不包含主键,则将UNIQUE KEY用作分区键。
CREATE TABLE AgentDetail (
agent_id INT NOT NULL UNIQUE KEY,
agent_name VARCHAR(40)
)
PARTITION BY KEY()
PARTITIONS 2;
换位
它是一个复合分区,可进一步拆分分区表中的每个分区。下面的示例有助于我们更清楚地理解它:
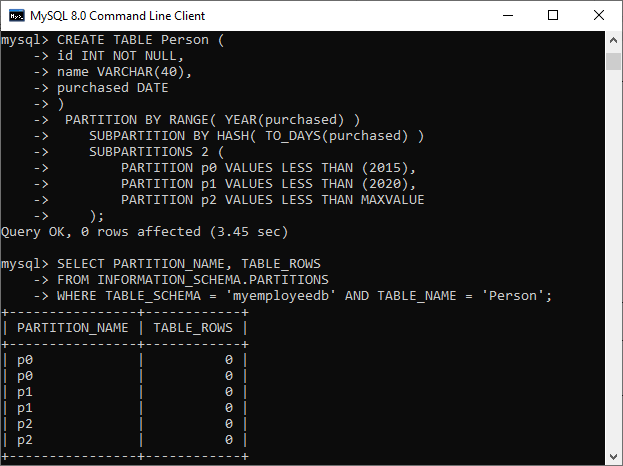
CREATE TABLE Person (
id INT NOT NULL PRIMARY KEY,
name VARCHAR(40),
purchased DATE
)
PARTITION BY RANGE( YEAR(purchased) )
SUBPARTITION BY HASH( TO_DAYS(purchased) )
SUBPARTITIONS 2 (
PARTITION p0 VALUES LESS THAN (2015),
PARTITION p1 VALUES LESS THAN (2020),
PARTITION p2 VALUES LESS THAN MAXVALUE
);
执行以下语句来验证子分区:
SELECT PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA = 'myemployeedb' AND TABLE_NAME = 'Person';
它将给出如下输出: