Amazon Web Services – 在 Sagemaker 中使用自定义 UI 模板
在本文中,我们将研究如何在Amazon Sagemaker ground truth 中使用自定义 UI 模板和 AWS Lambda 函数。
在这里,我们将使用 Jupyter 笔记本创建一个使用自定义 UI 模板和 AWS 提供的 lambda 函数以及使用 AWS 开发工具包(例如 boto3)的基本事实标签作业。为此,请按照以下步骤操作:
步骤 1:首先创建一个名为customui.html的自定义 UI 模板文件,以创建语义分割作业。下面给出了一个示例代码:
HTML
- Inspect the Image
- Add appropriate label for the image.
Use the tools to label the requested items in the image
Python3
import boto3
import os
bucket = 'labelingjobdemoinputz'
prefix ='GroundTruthCustom'
boto3.Session().resource( 's3').Bucket(bucket).Object(os.path.join(prefix,
'customUI.html')).upload_file( 'CustomUI.html')
boto3.Session().resource('s3').Bucket (bucket).Object(os.path.join(prefix,
'input.manifest')).upload_file('input.manifest')
boto3.Session().resource('s3').Bucket (bucket).Object(os.path.join(prefix,
'testLabels.json')).upload_file('testLabels.json')Python3
import boto3
client = boto3.client('sagemaker')
client.create_labeling_job(LabelingJobName='SemanticSeg-CustomUI',
LabelAttributeName='output-ref',
InputConfig={
'DataSource': {
'S3DataSource': {
'ManifestS3Uri': 'INPUT_MANIFEST_IN_S3'
}
},
'DataAttributes': {
'ContentClassifiers' : [
'FreeOfPersonallyIdentifiableInformation',
]
}
},
OutputConfig={
'S3OutputPath' : 'S3_OUTPUT_PATH'
},
RoleArn='IAM_ROLE_ARN',
LabelCategoryConfigS3Uri='LABELS_JSON_FILE_IN_S3,
StoppingConditions={
'MaxPercentageOfInputDatasetLabeled': 100
},
HumanTaskConfig={
'WorkteamArn': 'WORKTEAM_ARN',
'UiConfig': {
'UiTemplateS3Uri' : 'HTML_TEMPLATE_IN_S3'
},
'PreHumanTaskLambdaArn' : 'YOUR_ARNs_HERE',
'TaskKeywords': [
'SemanticSegmentation',
],
'TaskTitle': 'Semantic Segmentation',
'TaskDescription': 'Draw around the specified labels using the tools',
'NumberOfHumanWorkersPerDataObject': 1,
'TaskTimeLimitInSeconds': 3600,
'TaskAvailabilityLifetimeInSeconds': 1800,
'MaxConcurrentTaskCount': 1,
'AnnotationConsolidationConfig': {
'AnnotationConsolidationLambdaArn': 'YOUR_ARNs_HERE
}
},
Tags=[
{
'Key': 'reason',
'Value': 'CustomUI'
}
])第 2 步:现在为标签创建一个名为testlabels.json的 JSON 文件,为 Amazon Simple Storage Service 中的图像创建一个名为input.manifest的输入清单文件。
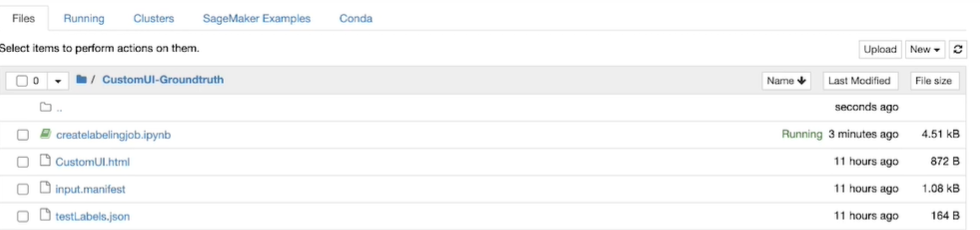
第 3 步:通过执行以下Python代码将 HTML、清单和 JSON 文件上传到亚马逊简单存储服务:
Python3
import boto3
import os
bucket = 'labelingjobdemoinputz'
prefix ='GroundTruthCustom'
boto3.Session().resource( 's3').Bucket(bucket).Object(os.path.join(prefix,
'customUI.html')).upload_file( 'CustomUI.html')
boto3.Session().resource('s3').Bucket (bucket).Object(os.path.join(prefix,
'input.manifest')).upload_file('input.manifest')
boto3.Session().resource('s3').Bucket (bucket).Object(os.path.join(prefix,
'testLabels.json')).upload_file('testLabels.json')
第 4 步:为 AWS 提供的预处理和注释整合 Lambda 函数检索 Amazon 资源名称 (ARN)。例如,这里是语义分割 ARN:

第 5 步:现在使用 AWS 开发工具包创建标签作业。确保将脚本中的默认变量替换为相应的 amazon S3 文件路径和 ARN。
Python3
import boto3
client = boto3.client('sagemaker')
client.create_labeling_job(LabelingJobName='SemanticSeg-CustomUI',
LabelAttributeName='output-ref',
InputConfig={
'DataSource': {
'S3DataSource': {
'ManifestS3Uri': 'INPUT_MANIFEST_IN_S3'
}
},
'DataAttributes': {
'ContentClassifiers' : [
'FreeOfPersonallyIdentifiableInformation',
]
}
},
OutputConfig={
'S3OutputPath' : 'S3_OUTPUT_PATH'
},
RoleArn='IAM_ROLE_ARN',
LabelCategoryConfigS3Uri='LABELS_JSON_FILE_IN_S3,
StoppingConditions={
'MaxPercentageOfInputDatasetLabeled': 100
},
HumanTaskConfig={
'WorkteamArn': 'WORKTEAM_ARN',
'UiConfig': {
'UiTemplateS3Uri' : 'HTML_TEMPLATE_IN_S3'
},
'PreHumanTaskLambdaArn' : 'YOUR_ARNs_HERE',
'TaskKeywords': [
'SemanticSegmentation',
],
'TaskTitle': 'Semantic Segmentation',
'TaskDescription': 'Draw around the specified labels using the tools',
'NumberOfHumanWorkersPerDataObject': 1,
'TaskTimeLimitInSeconds': 3600,
'TaskAvailabilityLifetimeInSeconds': 1800,
'MaxConcurrentTaskCount': 1,
'AnnotationConsolidationConfig': {
'AnnotationConsolidationLambdaArn': 'YOUR_ARNs_HERE
}
},
Tags=[
{
'Key': 'reason',
'Value': 'CustomUI'
}
])
这将导致以下结果:

第 6 步:现在导航到 ground truth 控制台以查看新创建的标签作业。
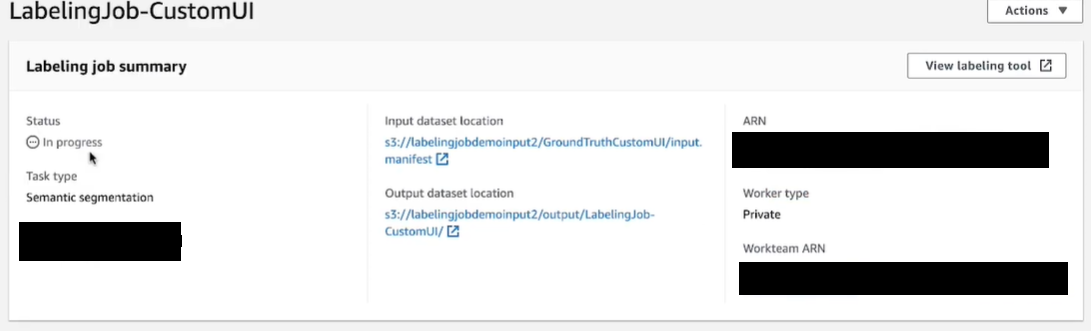
现在您知道如何在基本事实中将自定义 UI 模板与 AWS 提供的 lambda 函数一起使用。