Beautifulsoup – nextSibling
nextSibling属性用于将指定节点的下一个节点作为 Node 对象返回,如果指定节点是列表中的最后一个,则返回 null。它是只读属性。在本文中,我们将找到满足给定标准并出现在文档中此标签之后的给定标签的下一个兄弟姐妹。
例子:
HTML_DOC :
“””
1957: FORTRAN
1972: C
1983: C++
1991: Python
1993: Ruby
1995: Java
1995: PHP
1995: JavaScript
“””
element :
1957: FORTRAN
Output :
1972: C
1983: C++
1991: Python
1993: Ruby
1995: Java
1995: PHP
1995: JavaScript
所需模块:
- BeautifulSoup (bs4):它是一个Python库,用于从 HTML 和 XML 文件中提取数据。这个模块没有内置于Python。在终端中运行以下命令来安装这个库——
pip install bs4
or
pip install beautifulsoup4寻找下一个兄弟姐妹:
find_next_siblings() function is used to find all the next siblings of a tag / element.
It returns all the next siblings that match.
寻找下一个兄弟姐妹:
find_next_sibling() function is used to find the succeeding sibling of a tag/element.
It only returns the first match next to the tag/element.
示例 1:查找标签/元素的所有下一个同级
Python3
# Import Module
from bs4 import BeautifulSoup
# HTML Document
HTML_DOC = """
Find Next Siblings
1957: FORTRAN
1972: C
1983: C++
1991: Python
1993: Ruby
1995: Java
1995: PHP
1995: JavaScript
"""
# Function to find all the next siblings
def findNextSiblings(html):
# parse html content
soup = BeautifulSoup(html, "html.parser")
element = soup.p
# Extracting all the next siblings of an element
nextSiblings = element.find_next_siblings("p")
# Printing all the next siblings
for nextSibling in nextSiblings:
print(nextSibling)
# Function Call
findNextSiblings(HTML_DOC)Python3
# Import Module
from bs4 import BeautifulSoup
# HTML Document
HTML_DOC = """
Find Next Sibling
1957: FORTRAN
1972: C
1983: C++
1991: Python
1993: Ruby
1995: Java
1995: PHP
1995: JavaScript
"""
# Function to find the next sibling
def findNextSibling(html):
# parse html content
soup = BeautifulSoup(html, "html.parser")
element = soup.p
# Extracting the next sibling of an element
nextSibling = element.find_next_sibling("p")
# Printing next sibling of an element
print(nextSibling)
# Function Call
findNextSibling(HTML_DOC)Python3
# Import Module
from bs4 import BeautifulSoup
# HTML Document
HTML_DOC = """
Find Next Sibling Of Parent
1957: FORTRAN
1995: PHP
1995: JavaScript
"""
# Function to find the next sibling
def findNextSibling(html):
# parse html content
soup = BeautifulSoup(html, "html.parser")
element = soup.p
# Parent tag of the element
parent_tag = element.parent
# Extracting the next sibling of parent
nextSibling = parent_tag.find_next_sibling("div")
# Printing next sibling of parent
print(nextSibling)
# Function Call
findNextSibling(HTML_DOC)Python3
# Import Module
from bs4 import BeautifulSoup
# HTML Document
HTML_DOC = """
Find Next 3 Siblings
1957: FORTRAN
1972: C
1983: C++
1991: Python
1993: Ruby
1995: Java
1995: PHP
1995: JavaScript
"""
# Function to find 3 next siblings
def findNextSiblings(html):
# parse html content
soup = BeautifulSoup(html, "html.parser")
element = soup.p
# Extracting the next 3 siblings of an element
nextSiblings = element.find_next_siblings("p", limit=3)
# Printing the next 3 siblings
for nextSibling in nextSiblings:
print(nextSibling)
# Function Call
findNextSiblings(HTML_DOC)输出:
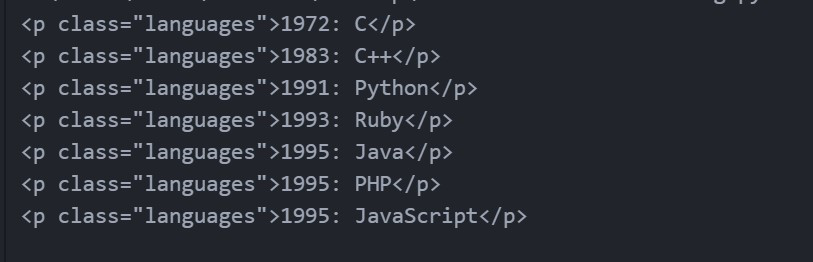
示例 2:查找标签/元素的下一个兄弟
蟒蛇3
# Import Module
from bs4 import BeautifulSoup
# HTML Document
HTML_DOC = """
Find Next Sibling
1957: FORTRAN
1972: C
1983: C++
1991: Python
1993: Ruby
1995: Java
1995: PHP
1995: JavaScript
"""
# Function to find the next sibling
def findNextSibling(html):
# parse html content
soup = BeautifulSoup(html, "html.parser")
element = soup.p
# Extracting the next sibling of an element
nextSibling = element.find_next_sibling("p")
# Printing next sibling of an element
print(nextSibling)
# Function Call
findNextSibling(HTML_DOC)
输出:

示例 3:查找 Parent Tag 的下一个兄弟(在嵌套结构的情况下)
蟒蛇3
# Import Module
from bs4 import BeautifulSoup
# HTML Document
HTML_DOC = """
Find Next Sibling Of Parent
1957: FORTRAN
1995: PHP
1995: JavaScript
"""
# Function to find the next sibling
def findNextSibling(html):
# parse html content
soup = BeautifulSoup(html, "html.parser")
element = soup.p
# Parent tag of the element
parent_tag = element.parent
# Extracting the next sibling of parent
nextSibling = parent_tag.find_next_sibling("div")
# Printing next sibling of parent
print(nextSibling)
# Function Call
findNextSibling(HTML_DOC)
输出:

示例 4:查找指定数量的下一个兄弟姐妹。
例如,仅查找元素的下 3 个兄弟元素。
这可以通过使用limit参数来完成
蟒蛇3
# Import Module
from bs4 import BeautifulSoup
# HTML Document
HTML_DOC = """
Find Next 3 Siblings
1957: FORTRAN
1972: C
1983: C++
1991: Python
1993: Ruby
1995: Java
1995: PHP
1995: JavaScript
"""
# Function to find 3 next siblings
def findNextSiblings(html):
# parse html content
soup = BeautifulSoup(html, "html.parser")
element = soup.p
# Extracting the next 3 siblings of an element
nextSiblings = element.find_next_siblings("p", limit=3)
# Printing the next 3 siblings
for nextSibling in nextSiblings:
print(nextSibling)
# Function Call
findNextSiblings(HTML_DOC)
输出:
