Python – 计算去除停用词和词干后的词频
在本文中,我们将在Python环境中使用 NLTK 工具包对句子、段落、网页内容进行标记,然后我们将删除停用词并对句子、段落、网页的内容进行词干提取。最后,我们将计算去除停用词和词干后的词频。
需要的模块
bs4: Beautiful Soup (bs4) 是一个Python库,用于从 HTML 和 XML 文件中提取数据。要安装此库,请在 IDE/终端中键入以下命令。
pip install bs4urllib: Urllib 包是用于Python的统一资源定位器处理库。它用于获取 URL。要安装此库,请在 IDE/终端中键入以下命令。
pip install urllibnltk: NLTK 库是Python中用于自然语言处理的大型工具包,该模块通过提供完整的 NLP 方法来帮助我们。要安装此库,请在 IDE/终端中键入以下命令。
pip install nltk逐步实施:
第1步:
- 将文件 sentence.txt、paragraph.txt 保存在当前目录中。
- 使用 open 方法打开文件并将它们存储在名为 file1、file2 的文件运算符中。
- 使用read()方法读取文件内容并将整个文件内容存储到单个字符串中。
- 显示文件内容。
- 关闭文件运算符。
Python
import nltk
s = input('Enter the file name which contains a sentence: ')
file1 = open(s)
sentence = file1.read()
file1.close()
p = input('Enter the file name which contains a paragraph: ')
file2 = open(p)
paragraph = file2.read()
file2.close()Python
import urllib.request
from bs4 import BeautifulSoup
url = input('Enter URL of Webpage: ')
print('\n')
url_request = urllib.request.Request(url)
url_response = urllib.request.urlopen(url)
webpage_data = url_response.read()
soup = BeautifulSoup(webpage_data, 'html.parser')Python
web_page_paragraph_contents = soup('p')
web_page_data = ''
for para in web_page_paragraph_contents:
web_page_data = web_page_data + str(para.text)Python
from nltk.tokenize import word_tokenize
import re
sentence_without_punctuations = re.sub(r'[^\w\s]', '', sentence)
paragraph_without_punctuations = re.sub(r'[^\w\s]', '', paragraph)
web_page_paragraphs_without_punctuations = re.sub(r'[^\w\s]', '', web_page_data)Python
sentence_after_tokenizing = word_tokenize(sentence_without_punctuations)
paragraph_after_tokenizing = word_tokenize(paragraph_without_punctuations)
webpage_after_tokenizing = word_tokenize(web_page_paragraphs_without_punctuations)Python
from nltk.corpus import stopwords
nltk.download('stopwords')
nltk_stop_words = stopwords.words('english')
sentence_without_stopwords = [i for i in sentence_after_tokenizing if not i.lower() in nltk_stop_words]
paragraph_without_stopwords = [j for j in paragraph_after_tokenizing if not j.lower() in nltk_stop_words]
webpage_without_stopwords = [k for k in webpage_after_tokenizing if not k.lower() in nltk_stop_words]Python
from nltk.stem.porter import PorterStemmer
stemmer = PorterStemmer()
sentence_after_stemming= []
paragraph_after_stemming =[]
webpage_after_stemming = [] #creating empty lists for storing stemmed words
for word in sentence_without_stopwords:
sentence_after_stemming.append(stemmer.stem(word))
for word in paragraph_without_stopwords:
paragraph_after_stemming.append(stemmer.stem(word))
for word in webpage_without_stopwords:
webpage_after_stemming.append(stemmer.stem(word))Python
from textblob import TextBlob
final_words_sentence=[]
final_words_paragraph=[]
final_words_webpage=[]
for i in range(len(sentence_after_stemming)):
final_words_sentence.append(0)
present_word=sentence_after_stemming[i]
b=TextBlob(sentence_after_stemming[i])
if str(b.correct()).lower() in nltk_stop_words:
final_words_sentence[i]=present_word
else:
final_words_sentence[i]=str(b.correct())
print(final_words_sentence)
print('\n')
for i in range(len(paragraph_after_stemming)):
final_words_paragraph.append(0)
present_word = paragraph_after_stemming[i]
b = TextBlob(paragraph_after_stemming[i])
if str(b.correct()).lower() in nltk_stop_words:
final_words_paragraph[i] = present_word
else:
final_words_paragraph[i] = str(b.correct())
print(final_words_paragraph)
print('\n')
for i in range(len(webpage_after_stemming)):
final_words_webpage.append(0)
present_word = webpage_after_stemming[i]
b = TextBlob(webpage_after_stemming[i])
if str(b.correct()).lower() in nltk_stop_words:
final_words_webpage[i] = present_word
else:
final_words_webpage[i] = str(b.correct())
print(final_words_webpage)
print('\n')Python
from collections import Counter
sentence_count = Counter(final_words_sentence)
paragraph_count = Counter(final_words_paragraph)
webpage_count = Counter(final_words_webpage)Python
import nltk
s = input('Enter the file name which contains a sentence: ')
file1 = open(s)
sentence = file1.read()
file1.close()
p = input('Enter the file name which contains a paragraph: ')
file2 = open(p)
paragraph = file2.read()
file2.close()
import urllib.request
from bs4 import BeautifulSoup
url = input('Enter URL of Webpage: ')
print( '\n' )
url_request = urllib.request.Request(url)
url_response = urllib.request.urlopen(url)
webpage_data = url_response.read()
soup = BeautifulSoup(webpage_data, 'html.parser')
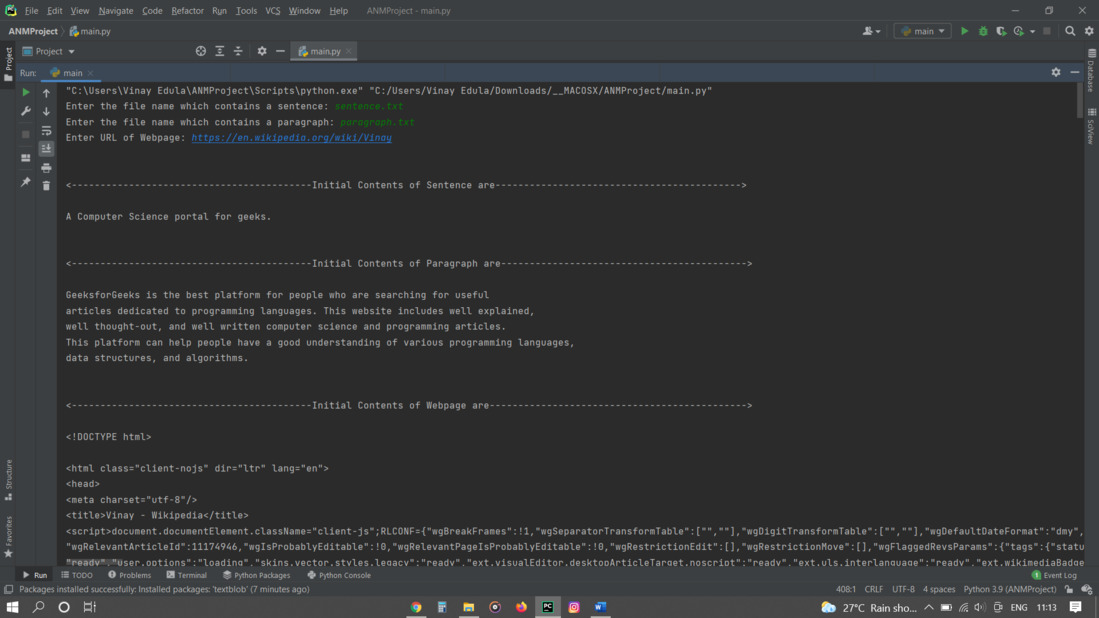
print('<------------------------------------------Initial Contents of Sentence are-------------------------------------------> \n')
print(sentence)
print( '\n' )
print('<------------------------------------------Initial Contents of Paragraph are-------------------------------------------> \n')
print(paragraph)
print( '\n' )
print('<------------------------------------------Initial Contents of Webpage are---------------------------------------------> \n')
print(soup)
print( '\n' )
web_page_paragraph_contents=soup('p')
web_page_data = ''
for para in web_page_paragraph_contents:
web_page_data = web_page_data + str(para.text)
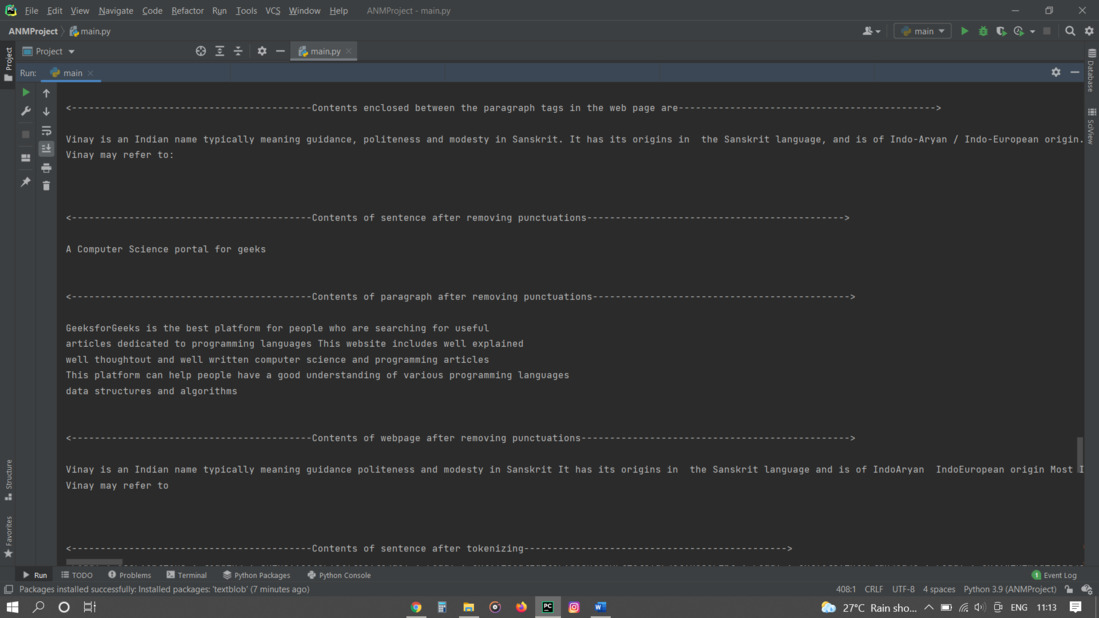
print('<------------------------------------------Contents enclosed between the paragraph tags in the web page are---------------------------------------------> \n')
print(web_page_data)
print('\n')
from nltk.tokenize import word_tokenize
import re
sentence_without_punctuations = re.sub(r'[^\w\s]', '', sentence)
paragraph_without_punctuations = re.sub(r'[^\w\s]', '', paragraph)
web_page_paragraphs_without_punctuations = re.sub(r'[^\w\s]', '', web_page_data)
print('<------------------------------------------Contents of sentence after removing punctuations---------------------------------------------> \n')
print(sentence_without_punctuations)
print('\n')
print('<------------------------------------------Contents of paragraph after removing punctuations---------------------------------------------> \n')
print(paragraph_without_punctuations)
print('\n')
print('<------------------------------------------Contents of webpage after removing punctuations-----------------------------------------------> \n')
print(web_page_paragraphs_without_punctuations)
print('\n')
sentence_after_tokenizing = word_tokenize(sentence_without_punctuations)
paragraph_after_tokenizing = word_tokenize(paragraph_without_punctuations)
webpage_after_tokenizing = word_tokenize(web_page_paragraphs_without_punctuations)
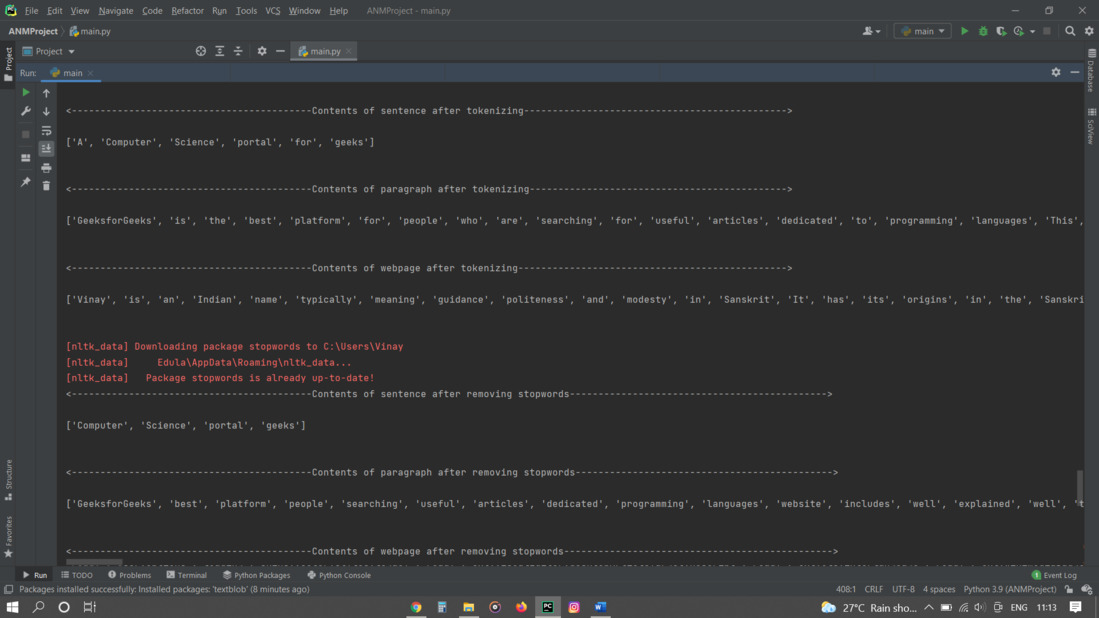
print('<------------------------------------------Contents of sentence after tokenizing----------------------------------------------> \n')
print(sentence_after_tokenizing)
print( '\n' )
print('<------------------ ------------------------Contents of paragraph after tokenizing---------------------------------------------> \n')
print(paragraph_after_tokenizing)
print( '\n' )
print('<------------------------------------------Contents of webpage after tokenizing-----------------------------------------------> \n')
print(webpage_after_tokenizing)
print( '\n' )
from nltk.corpus import stopwords
nltk.download('stopwords')
nltk_stop_words = stopwords.words('english')
sentence_without_stopwords = [i for i in sentence_after_tokenizing if not i.lower() in nltk_stop_words]
paragraph_without_stopwords = [j for j in paragraph_after_tokenizing if not j.lower() in nltk_stop_words]
webpage_without_stopwords = [k for k in webpage_after_tokenizing if not k.lower() in nltk_stop_words]
print('<------------------------------------------Contents of sentence after removing stopwords---------------------------------------------> \n')
print(sentence_without_stopwords)
print( '\n' )
print('<------------------------------------------Contents of paragraph after removing stopwords---------------------------------------------> \n')
print(paragraph_without_stopwords)
print( '\n' )
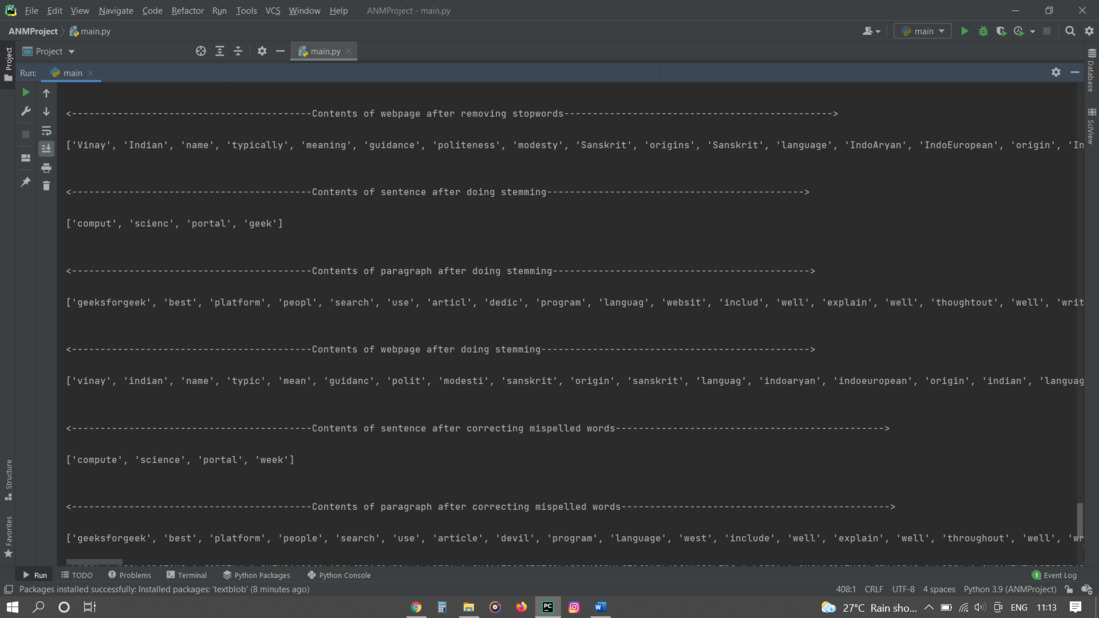
print('<------------------------------------------Contents of webpage after removing stopwords-----------------------------------------------> \n')
print(webpage_without_stopwords)
print( '\n' )
from nltk.stem.porter import PorterStemmer
stemmer = PorterStemmer()
sentence_after_stemming = []
paragraph_after_stemming = []
webpage_after_stemming = [] #creating empty lists for storing stemmed words
for word in sentence_without_stopwords:
sentence_after_stemming.append(stemmer.stem(word))
for word in paragraph_without_stopwords:
paragraph_after_stemming.append(stemmer.stem(word))
for word in webpage_without_stopwords:
webpage_after_stemming.append(stemmer.stem(word))
print('<------------------------------------------Contents of sentence after doing stemming---------------------------------------------> \n')
print(sentence_after_stemming)
print( '\n' )
print('<------------------------------------------Contents of paragraph after doing stemming---------------------------------------------> \n')
print(paragraph_after_stemming)
print( '\n' )
print('<------------------------------------------Contents of webpage after doing stemming-----------------------------------------------> \n')
print(webpage_after_stemming)
print( '\n' )
from textblob import TextBlob
final_words_sentence=[]
final_words_paragraph=[]
final_words_webpage=[]
for i in range(len(sentence_after_stemming)):
final_words_sentence.append(0)
present_word=sentence_after_stemming[i]
b=TextBlob(sentence_after_stemming[i])
if str(b.correct()).lower() in nltk_stop_words:
final_words_sentence[i]=present_word
else:
final_words_sentence[i]=str(b.correct())
print('<------------------------------------------Contents of sentence after correcting mispelled words-----------------------------------------------> \n')
print(final_words_sentence)
print('\n')
for i in range(len(paragraph_after_stemming)):
final_words_paragraph.append(0)
present_word = paragraph_after_stemming[i]
b = TextBlob(paragraph_after_stemming[i])
if str(b.correct()).lower() in nltk_stop_words:
final_words_paragraph[i] = present_word
else:
final_words_paragraph[i] = str(b.correct())
print('<------------------------------------------Contents of paragraph after correcting mispelled words-----------------------------------------------> \n')
print(final_words_paragraph)
print('\n')
for i in range(len(webpage_after_stemming)):
final_words_webpage.append(0)
present_word = webpage_after_stemming[i]
b = TextBlob(webpage_after_stemming[i])
if str(b.correct()).lower() in nltk_stop_words:
final_words_webpage[i] = present_word
else:
final_words_webpage[i] = str(b.correct())
print('<------------------------------------------Contents of webpage after correcting mispelled words-----------------------------------------------> \n')
print(final_words_webpage)
print('\n')
from collections import Counter
sentence_count = Counter(final_words_sentence)
paragraph_count = Counter(final_words_paragraph)
webpage_count = Counter(final_words_webpage)
print('<------------------------------------------Frequency of words in sentence ---------------------------------------------> \n')
print(sentence_count)
print( '\n' )
print('<------------------------------------------Frequency of words in paragraph ---------------------------------------------> \n')
print(paragraph_count)
print( '\n' )
print('<------------------------------------------Frequency of words in webpage -----------------------------------------------> \n')
print(webpage_count)第2步:
- 导入urllib.request用于打开和阅读网页内容。
- 从bs4导入BeautifulSoup ,它允许我们从 HTML 文档中提取数据。
- 使用urllib.request向特定的 url 服务器发出请求。
- 服务器将响应并返回 Html 文档。
- 使用read()方法读取网页内容。
- 将网页数据传递给 BeautifulSoap,它可以帮助我们通过修复错误的 HTML 来组织和格式化混乱的网络数据,并以易于遍历的结构呈现给我们。
Python
import urllib.request
from bs4 import BeautifulSoup
url = input('Enter URL of Webpage: ')
print('\n')
url_request = urllib.request.Request(url)
url_response = urllib.request.urlopen(url)
webpage_data = url_response.read()
soup = BeautifulSoup(webpage_data, 'html.parser')
第三步:
- 为了简化标记化任务,我们将只提取 HTML 页面的一部分。
- 使用BeautifulSoup运算符提取 HTML 文档中存在的所有段落标签。
- Soup('p') 返回包含网页上所有段落标签的项目列表。
- 创建一个名为 web_page_data 的空字符串。
- 对于列表中存在的每个标签,将标签之间的文本连接到空字符串。
Python
web_page_paragraph_contents = soup('p')
web_page_data = ''
for para in web_page_paragraph_contents:
web_page_data = web_page_data + str(para.text)
第4步:
- 使用re.sub()将非字母字符替换为空字符串。
- re.sub()将正则表达式、新字符串和输入字符串作为参数并返回修改后的字符串(将输入字符串中的指定字符替换为新字符串)。
- ^ - 表示它将匹配写在它右侧的模式。
- \w – #在每个非字母字符(不在 a 和 Z 之间的字符。如“!”、“?”空格、包括下划线等的数字)和 \s – 匹配空格。
Python
from nltk.tokenize import word_tokenize
import re
sentence_without_punctuations = re.sub(r'[^\w\s]', '', sentence)
paragraph_without_punctuations = re.sub(r'[^\w\s]', '', paragraph)
web_page_paragraphs_without_punctuations = re.sub(r'[^\w\s]', '', web_page_data)
第五步:
- 将删除标点符号后的句子、段落、网页内容、不必要的字符传递到 word_tokenize() 中,返回标记化的文本、段落、网络字符串。
- 显示分词句子、分词段落、分词网络字符串的内容。
Python
sentence_after_tokenizing = word_tokenize(sentence_without_punctuations)
paragraph_after_tokenizing = word_tokenize(paragraph_without_punctuations)
webpage_after_tokenizing = word_tokenize(web_page_paragraphs_without_punctuations)
第六步:
- 从 nltk.corpus 导入停用词。
- 使用nltk.download('stopwords')下载停用词。
- 将英语停用词存储在nltk_stop_words中。
- 将标记化句子、标记化段落标记化网络字符串中的每个单词与 nltk_stop_words 中存在的单词进行比较,如果我们数据中的任何单词出现在 nltk 停用词中,我们将忽略这些单词。
Python
from nltk.corpus import stopwords
nltk.download('stopwords')
nltk_stop_words = stopwords.words('english')
sentence_without_stopwords = [i for i in sentence_after_tokenizing if not i.lower() in nltk_stop_words]
paragraph_without_stopwords = [j for j in paragraph_after_tokenizing if not j.lower() in nltk_stop_words]
webpage_without_stopwords = [k for k in webpage_after_tokenizing if not k.lower() in nltk_stop_words]
第七步:
- 从 nltk.stem.porter 导入 PorterStemmer。
- 使用 nltk 进行词干提取:删除后缀并考虑词根。
- 创建三个空列表,用于存储句子、段落、网页的词干词。
- 使用 stemmer.stem() 对前一个列表中存在的每个单词进行词干处理,并将其存储在新创建的列表中。
Python
from nltk.stem.porter import PorterStemmer
stemmer = PorterStemmer()
sentence_after_stemming= []
paragraph_after_stemming =[]
webpage_after_stemming = [] #creating empty lists for storing stemmed words
for word in sentence_without_stopwords:
sentence_after_stemming.append(stemmer.stem(word))
for word in paragraph_without_stopwords:
paragraph_after_stemming.append(stemmer.stem(word))
for word in webpage_without_stopwords:
webpage_after_stemming.append(stemmer.stem(word))
第八步:
- 有时在进行词干提取后可能会导致单词拼写错误,因为这是一个实现问题。
- 使用 TextBlob 模块,我们可以为特定拼写错误的单词找到相关的正确单词。
- 对于 sentence_after_stemming、paragraph_after_stemming、webpage_after_stemming 中的每个单词,使用 correct() 方法找到该单词的实际正确。
- 检查停用词中是否存在正确的词。如果它不存在于停用词中,则将正确的词替换为拼写错误的词。
Python
from textblob import TextBlob
final_words_sentence=[]
final_words_paragraph=[]
final_words_webpage=[]
for i in range(len(sentence_after_stemming)):
final_words_sentence.append(0)
present_word=sentence_after_stemming[i]
b=TextBlob(sentence_after_stemming[i])
if str(b.correct()).lower() in nltk_stop_words:
final_words_sentence[i]=present_word
else:
final_words_sentence[i]=str(b.correct())
print(final_words_sentence)
print('\n')
for i in range(len(paragraph_after_stemming)):
final_words_paragraph.append(0)
present_word = paragraph_after_stemming[i]
b = TextBlob(paragraph_after_stemming[i])
if str(b.correct()).lower() in nltk_stop_words:
final_words_paragraph[i] = present_word
else:
final_words_paragraph[i] = str(b.correct())
print(final_words_paragraph)
print('\n')
for i in range(len(webpage_after_stemming)):
final_words_webpage.append(0)
present_word = webpage_after_stemming[i]
b = TextBlob(webpage_after_stemming[i])
if str(b.correct()).lower() in nltk_stop_words:
final_words_webpage[i] = present_word
else:
final_words_webpage[i] = str(b.correct())
print(final_words_webpage)
print('\n')
第九步:
- 使用 Collections 模块中的 Counter 方法查找句子、段落、网页中单词的频率。 Python Counter 是一个容器,它将保存容器中存在的每个元素的计数。
- Counter 方法返回一个键值对为 {'word',word_count} 的字典。
Python
from collections import Counter
sentence_count = Counter(final_words_sentence)
paragraph_count = Counter(final_words_paragraph)
webpage_count = Counter(final_words_webpage)
下面是完整的实现:
Python
import nltk
s = input('Enter the file name which contains a sentence: ')
file1 = open(s)
sentence = file1.read()
file1.close()
p = input('Enter the file name which contains a paragraph: ')
file2 = open(p)
paragraph = file2.read()
file2.close()
import urllib.request
from bs4 import BeautifulSoup
url = input('Enter URL of Webpage: ')
print( '\n' )
url_request = urllib.request.Request(url)
url_response = urllib.request.urlopen(url)
webpage_data = url_response.read()
soup = BeautifulSoup(webpage_data, 'html.parser')
print('<------------------------------------------Initial Contents of Sentence are-------------------------------------------> \n')
print(sentence)
print( '\n' )
print('<------------------------------------------Initial Contents of Paragraph are-------------------------------------------> \n')
print(paragraph)
print( '\n' )
print('<------------------------------------------Initial Contents of Webpage are---------------------------------------------> \n')
print(soup)
print( '\n' )
web_page_paragraph_contents=soup('p')
web_page_data = ''
for para in web_page_paragraph_contents:
web_page_data = web_page_data + str(para.text)
print('<------------------------------------------Contents enclosed between the paragraph tags in the web page are---------------------------------------------> \n')
print(web_page_data)
print('\n')
from nltk.tokenize import word_tokenize
import re
sentence_without_punctuations = re.sub(r'[^\w\s]', '', sentence)
paragraph_without_punctuations = re.sub(r'[^\w\s]', '', paragraph)
web_page_paragraphs_without_punctuations = re.sub(r'[^\w\s]', '', web_page_data)
print('<------------------------------------------Contents of sentence after removing punctuations---------------------------------------------> \n')
print(sentence_without_punctuations)
print('\n')
print('<------------------------------------------Contents of paragraph after removing punctuations---------------------------------------------> \n')
print(paragraph_without_punctuations)
print('\n')
print('<------------------------------------------Contents of webpage after removing punctuations-----------------------------------------------> \n')
print(web_page_paragraphs_without_punctuations)
print('\n')
sentence_after_tokenizing = word_tokenize(sentence_without_punctuations)
paragraph_after_tokenizing = word_tokenize(paragraph_without_punctuations)
webpage_after_tokenizing = word_tokenize(web_page_paragraphs_without_punctuations)
print('<------------------------------------------Contents of sentence after tokenizing----------------------------------------------> \n')
print(sentence_after_tokenizing)
print( '\n' )
print('<------------------ ------------------------Contents of paragraph after tokenizing---------------------------------------------> \n')
print(paragraph_after_tokenizing)
print( '\n' )
print('<------------------------------------------Contents of webpage after tokenizing-----------------------------------------------> \n')
print(webpage_after_tokenizing)
print( '\n' )
from nltk.corpus import stopwords
nltk.download('stopwords')
nltk_stop_words = stopwords.words('english')
sentence_without_stopwords = [i for i in sentence_after_tokenizing if not i.lower() in nltk_stop_words]
paragraph_without_stopwords = [j for j in paragraph_after_tokenizing if not j.lower() in nltk_stop_words]
webpage_without_stopwords = [k for k in webpage_after_tokenizing if not k.lower() in nltk_stop_words]
print('<------------------------------------------Contents of sentence after removing stopwords---------------------------------------------> \n')
print(sentence_without_stopwords)
print( '\n' )
print('<------------------------------------------Contents of paragraph after removing stopwords---------------------------------------------> \n')
print(paragraph_without_stopwords)
print( '\n' )
print('<------------------------------------------Contents of webpage after removing stopwords-----------------------------------------------> \n')
print(webpage_without_stopwords)
print( '\n' )
from nltk.stem.porter import PorterStemmer
stemmer = PorterStemmer()
sentence_after_stemming = []
paragraph_after_stemming = []
webpage_after_stemming = [] #creating empty lists for storing stemmed words
for word in sentence_without_stopwords:
sentence_after_stemming.append(stemmer.stem(word))
for word in paragraph_without_stopwords:
paragraph_after_stemming.append(stemmer.stem(word))
for word in webpage_without_stopwords:
webpage_after_stemming.append(stemmer.stem(word))
print('<------------------------------------------Contents of sentence after doing stemming---------------------------------------------> \n')
print(sentence_after_stemming)
print( '\n' )
print('<------------------------------------------Contents of paragraph after doing stemming---------------------------------------------> \n')
print(paragraph_after_stemming)
print( '\n' )
print('<------------------------------------------Contents of webpage after doing stemming-----------------------------------------------> \n')
print(webpage_after_stemming)
print( '\n' )
from textblob import TextBlob
final_words_sentence=[]
final_words_paragraph=[]
final_words_webpage=[]
for i in range(len(sentence_after_stemming)):
final_words_sentence.append(0)
present_word=sentence_after_stemming[i]
b=TextBlob(sentence_after_stemming[i])
if str(b.correct()).lower() in nltk_stop_words:
final_words_sentence[i]=present_word
else:
final_words_sentence[i]=str(b.correct())
print('<------------------------------------------Contents of sentence after correcting mispelled words-----------------------------------------------> \n')
print(final_words_sentence)
print('\n')
for i in range(len(paragraph_after_stemming)):
final_words_paragraph.append(0)
present_word = paragraph_after_stemming[i]
b = TextBlob(paragraph_after_stemming[i])
if str(b.correct()).lower() in nltk_stop_words:
final_words_paragraph[i] = present_word
else:
final_words_paragraph[i] = str(b.correct())
print('<------------------------------------------Contents of paragraph after correcting mispelled words-----------------------------------------------> \n')
print(final_words_paragraph)
print('\n')
for i in range(len(webpage_after_stemming)):
final_words_webpage.append(0)
present_word = webpage_after_stemming[i]
b = TextBlob(webpage_after_stemming[i])
if str(b.correct()).lower() in nltk_stop_words:
final_words_webpage[i] = present_word
else:
final_words_webpage[i] = str(b.correct())
print('<------------------------------------------Contents of webpage after correcting mispelled words-----------------------------------------------> \n')
print(final_words_webpage)
print('\n')
from collections import Counter
sentence_count = Counter(final_words_sentence)
paragraph_count = Counter(final_words_paragraph)
webpage_count = Counter(final_words_webpage)
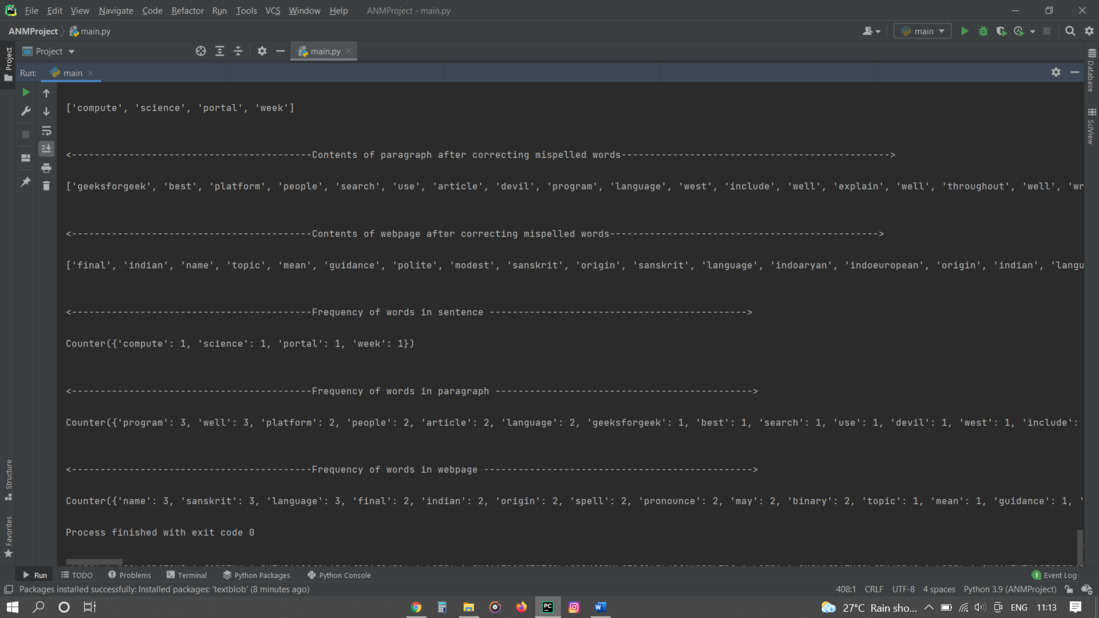
print('<------------------------------------------Frequency of words in sentence ---------------------------------------------> \n')
print(sentence_count)
print( '\n' )
print('<------------------------------------------Frequency of words in paragraph ---------------------------------------------> \n')
print(paragraph_count)
print( '\n' )
print('<------------------------------------------Frequency of words in webpage -----------------------------------------------> \n')
print(webpage_count)
输出: