- 使用Pandas在Python中读写CSV文件
- 使用Pandas在Python中读写CSV文件(1)
- pandas xlsx 到数据框 - Python (1)
- 如何在 Node.js 中读写 Excel 文件?
- 如何在 Node.js 中读写 Excel 文件?(1)
- pandas xlsx 到数据框 - Python 代码示例
- pandas xlsx 到 csv - Python (1)
- pandas xlsx 到 csv - Python 代码示例
- python pandas 将 df 保存到 xlsx 文件 - Python (1)
- python pandas read_excel xlrderror excel xlsx 文件不支持 - Shell-Bash (1)
- python pandas read_excel xlrderror excel xlsx 文件不支持 - Shell-Bash 代码示例
- 在Java读写属性文件(1)
- 在Java读写属性文件
- python pandas 将 df 保存到 xlsx 文件 - Python 代码示例
- python 如何读取 xlsx 文件 - Python (1)
- python 如何读取 xlsx 文件 - Python 代码示例
- 将结构读写到C中的文件(1)
- Golang中如何读写文件?(1)
- Golang中如何读写文件?
- 以读写模式打开文件python(1)
- 如何使用 Pandas 将 Excel 文件导入Python ?(1)
- 如何使用 Pandas 将 Excel 文件导入Python ?
- XLRDError:Excel xlsx 文件;不支持 - Python (1)
- 用于读写文件的python生成器 - Python(1)
- 如何使用 Node.js 读写 JSON 文件?(1)
- 如何使用 Node.js 读写 JSON 文件?
- XLRDError:Excel xlsx 文件;不支持 - Python 代码示例
- 以读写模式打开文件python代码示例
- 使用 Pandas 处理 excel 文件
📅 最后修改于: 2020-08-18 05:00:07 🧑 作者: Mango
介绍
就像所有其他类型的文件一样,您也可以使用Pandas库使用Python读取和写入Excel文件。在这个简短的教程中,我们将讨论如何通过DataFrames 读取和写入Excel文件。
除了简单的读写之外,我们还将学习如何将多个DataFrames写入Excel文件,如何从电子表格中读取特定的行和列,以及如何在执行任何操作之前命名文件中的单张或多张工作表。
使用Pandas在Python中读写Excel文件
当然,要使用熊猫,我们首先必须安装它。最简单的安装方法是通过pip。
如果您正在运行Windows:
python pip install pandas如果您使用的是Linux或MacOS:
pip install pandas请注意,运行本文中的代码时,您可能会收到ModuleNotFoundError或ImportError错误消息。例如:
ModuleNotFoundError: No module named 'openpyxl'如果是这种情况,则需要安装缺少的模块:
pip install openpyxl xlsxwriter xlrd使用Pandas编写Excel文件
我们将要写入的信息存储到Excel文件中DataFrame。使用内置to_excel()功能,我们可以将该信息提取到Excel文件中。
首先,让我们导入Pandas模块:
import pandas as pd 现在,让我们使用字典来填充DataFrame:
df = pd.DataFrame({'States':['California', 'Florida', 'Montana', 'Colorodo', 'Washington', 'Virginia'],
'Capitals':['Sacramento', 'Tallahassee', 'Helena', 'Denver', 'Olympia', 'Richmond'],
'Population':['508529', '193551', '32315', '619968', '52555', '227032']})我们字典中的键将用作列名。类似地,这些值成为包含信息的行。
现在,我们可以使用该to_excel()功能将内容写入文件。唯一的参数是文件路径:
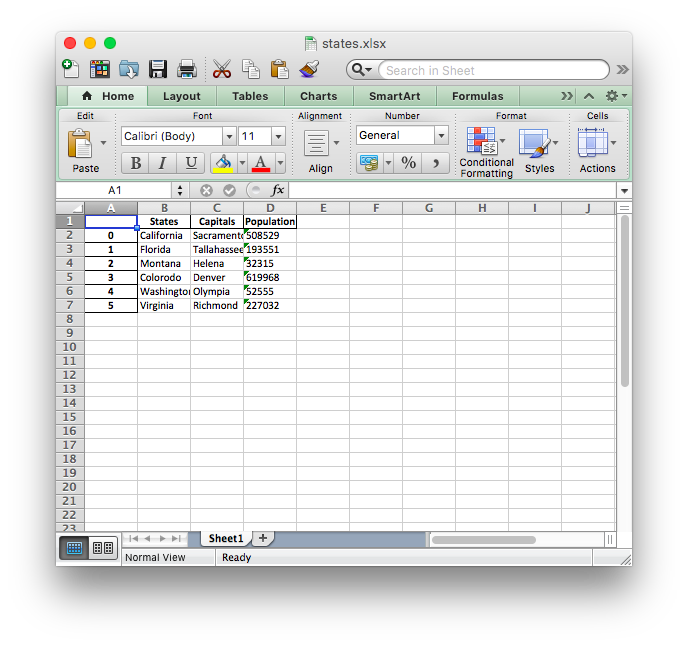
df.to_excel('./states.xlsx')这是创建的Excel文件:

请注意,我们的示例中未使用任何参数。因此,文件中的图纸保留其默认名称- “ Sheet 1″。如您所见,我们的Excel文件还有一个包含数字的附加列。这些数字是从熊猫直接得到的每一行的索引DataFrame。
我们可以通过将sheet_name参数添加到to_excel()调用中来更改工作表的名称:
df.to_excel('./states.xlsx', sheet_name='States')同样,添加index参数并将其设置为False将从输出中删除索引列:
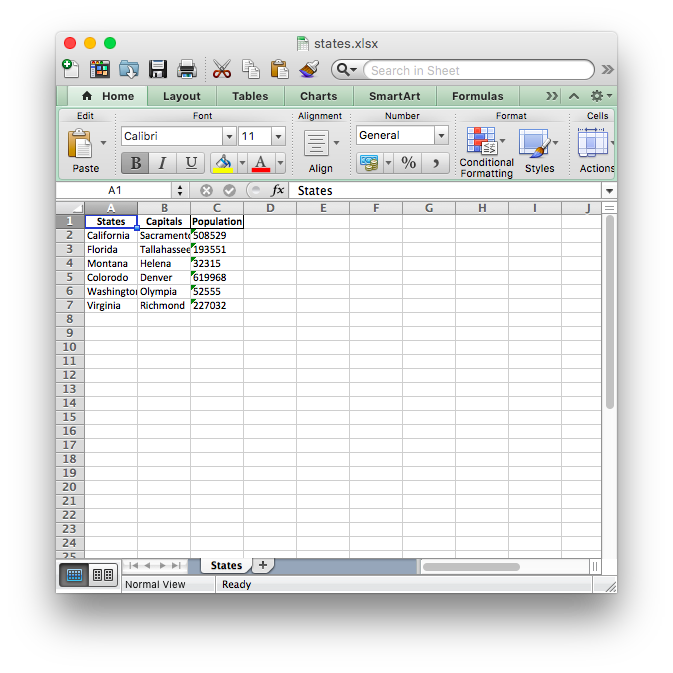
df.to_excel('./states.xlsx', sheet_name='States', index=False)现在,Excel文件如下所示:
请注意,我们的示例中未使用任何参数。因此,文件中的图纸保留其默认名称- “ Sheet 1″。如您所见,我们的Excel文件还有一个包含数字的附加列。这些数字是从熊猫直接得到的每一行的索引DataFrame。
我们可以通过将sheet_name参数添加到to_excel()调用中来更改工作表的名称:
df.to_excel('./states.xlsx', sheet_name='States')同样,添加index参数并将其设置为False将从输出中删除索引列:
df.to_excel('./states.xlsx', sheet_name='States', index=False)现在,Excel文件如下所示:
将多个数据框写入Excel文件
也可以将多个数据框写入Excel文件。如果您愿意,也可以为每个数据框设置不同的工作表:
income1 = pd.DataFrame({'Names': ['Stephen', 'Camilla', 'Tom'],
'Salary':[100000, 70000, 60000]})
income2 = pd.DataFrame({'Names': ['Pete', 'April', 'Marty'],
'Salary':[120000, 110000, 50000]})
income3 = pd.DataFrame({'Names': ['Victor', 'Victoria', 'Jennifer'],
'Salary':[75000, 90000, 40000]})
income_sheets = {'Group1': income1, 'Group2': income2, 'Group3': income3}
writer = pd.ExcelWriter('./income.xlsx', engine='xlsxwriter')
for sheet_name in income_sheets.keys():
income_sheets[sheet_name].to_excel(writer, sheet_name=sheet_name, index=False)
writer.save()在这里,我们创建了3个不同的数据框,其中包含不同名称的员工及其薪水作为数据。这些数据帧中的每一个都由其各自的字典填充。
我们将这三个income_sheets变量组合在一起,其中每个键是工作表名称,每个值是DataFrame对象。
最后,我们使用xlsxwriter引擎创建了一个writer对象。该对象传递给to_excel()函数调用。
在我们写任何东西之前,我们先遍历的键,income对于每个键,将内容写入各自的工作表名称。
这是生成的文件:
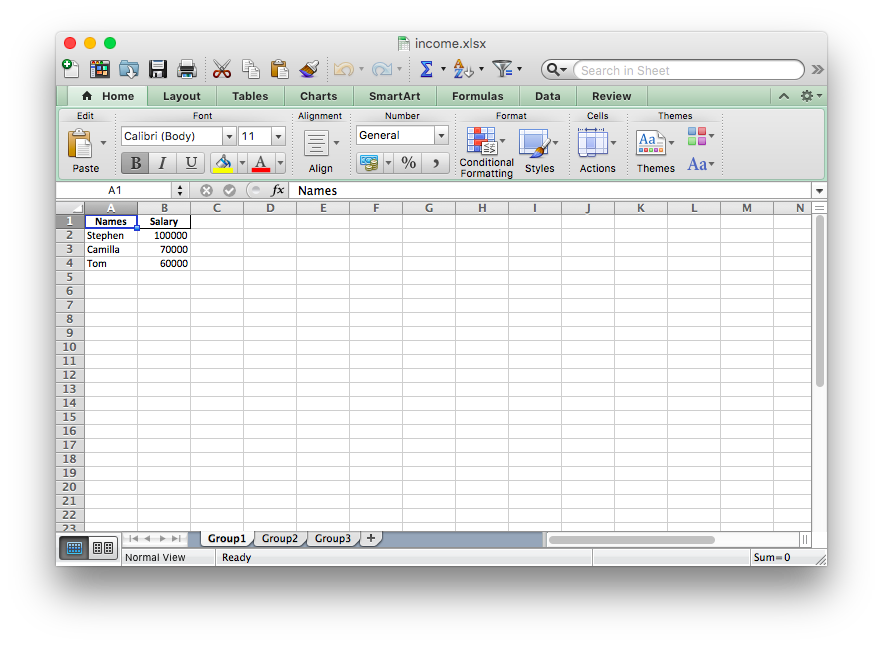
你可以看到,Excel文件有一个名为三个不同的床单Group1,Group2和Group3。这些表中的每一个表都在我们的代码的三个不同数据框中包含有关日期的雇员姓名及其工资。
to_excel()函数中的engine参数用于指定Pandas库使用哪个基础模块来创建Excel文件。在我们的例子中,该xlsxwriter模块用作ExcelWriter该类的引擎。可以根据各自的功能指定不同的引擎。
根据系统上安装的Python模块,引擎属性的其他选项为:(openpyxl用于xlsx和xlsm)和xlwt(用于xls)。
官方文档xlsxwriter中提供了将模块与Pandas库一起使用的更多详细信息。
最后但并非最不重要的一点,在上面的代码中,我们必须使用显式保存文件writer.save(),否则它将不会持久保存在磁盘上。
使用熊猫读取Excel文件
与将DataFrame对象写入Excel文件相反,我们可以通过将Excel文件读入DataFrames 来做相反的事情。将Excel文件的内容打包到中DataFrame就像调用read_excel()函数一样简单:
students_grades = pd.read_excel('./grades.xlsx')
students_grades.head()对于此示例,我们正在读取此Excel文件。
在这里,唯一需要的参数是Excel文件的路径。读取内容并将其打包到中DataFrame,然后我们可以通过head()函数进行预览。
注意:使用此方法虽然最简单,但只会读取第一页。
让我们看一下head()函数的输出:

DataFrame当我们使用该read_excel()功能时,Pandas 默认将行标签或数字索引分配给。
我们可以通过传递Excel文件列中的列之一作为index_col参数来覆盖默认索引:
students_grades = pd.read_excel('./grades.xlsx', sheet_names='Grades', index_col='Grade')
students_grades.head()运行此代码将导致:
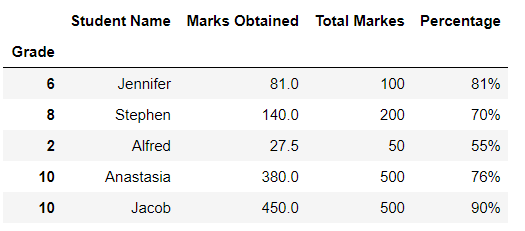
在上面的示例中,我们用Excel文件中的“等级”列替换了默认索引。但是,只有当列中的值可以用作更好的索引时,才应覆盖默认索引。
从Excel文件中读取特定列
完整读取文件很有用,尽管在许多情况下,您确实希望访问某个元素。例如,您可能想要读取元素的值并将其分配给对象的字段。
同样,这是使用read_excel()函数完成的,但是,我们将传递usecols参数。例如,我们可以将函数限制为仅读取某些列。我们添加参数,以便我们读取与“学生姓名”,“成绩”和“获得的分数”值相对应的列。
我们通过指定每列的数字索引来做到这一点:
cols = [0, 1, 3]
students_grades = pd.read_excel('./grades.xlsx', usecols=cols)
students_grades.head()运行此代码将产生:
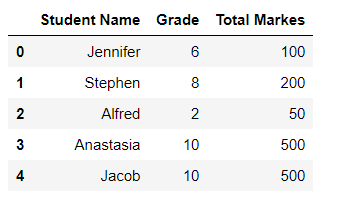
如您所见,我们仅检索cols列表中指定的列。
结论
我们已经介绍了Pandas库的read_excel()和to_excel()函数的一些常规用法。有了它们,我们已经阅读了现有的Excel文件并将我们自己的数据写入其中。
使用各种参数,我们可以更改这些函数的行为,从而允许我们构建自定义文件,而不仅仅是转储所有内容DataFrame。