- nlp (1)
- 理解语义分析——NLP
- 理解语义分析——NLP(1)
- nlp - 任何代码示例
- Python | NLP餐厅评论的分析
- Python | NLP餐厅评论分析
- Python | NLP餐厅评论分析(1)
- Python | NLP餐厅评论的分析(1)
- NLP的应用
- NLP的应用(1)
- nlp 中的转换器 - C++ (1)
- NLP 中的词嵌入(1)
- NLP 中的词嵌入
- 如何使用 pytho nlp 获取单词实体 (1)
- nlp 中的转换器 - C++ 代码示例
- 使用 NLP 和 SQLite 进行餐厅评论分析(1)
- 使用 NLP 和 SQLite 进行餐厅评论分析
- 如何使用 pytho nlp 获取单词实体 - 无论代码示例
- 算法分析|大O分析
- 算法分析|大O分析
- 算法分析|大O分析(1)
- nlp 的文本拆分器 - Python (1)
- NLP-语言资源
- NLP-语言资源(1)
- nlp 完整形式 (1)
- nlp 在 python 中生成解析树(1)
- 注意 nlp - C++ (1)
- nlp 的文本拆分器 - Python 代码示例
- 树命令级别 (1)
📅 最后修改于: 2020-11-23 04:38:29 🧑 作者: Mango
在本章中,我们将了解自然语言处理中的世界级分析。
常用表达
正则表达式(RE)是一种用于指定文本搜索字符串的语言。 RE帮助我们匹配或查找其他字符串或字符串集,用一个模式举行了专门的语法。正则表达式用于以相同方式在UNIX和MS WORD中搜索文本。我们有使用各种RE功能的各种搜索引擎。
正则表达式的属性
以下是RE的一些重要属性-
-
美国数学家Stephen Cole Kleene正式化了正则表达式语言。
-
RE是一种特殊语言的公式,可用于指定简单的字符串类(符号序列)。换句话说,我们可以说RE是表征一组字符串的代数符号。
-
正则表达式需要两件事,一是我们希望搜索的模式,另一是我们需要从中搜索的文本语料库。
数学上,正则表达式可以定义如下-
-
ε是一个正则表达式,表示该语言的字符串为空。
-
φ是一个正则表达式,表示它是一种空语言。
-
如果X和Y是正则表达式,则
-
X,Y
-
XY(XY的串联)
-
X + Y(X和Y的联盟)
-
X *,Y *(X和Y的Kleen闭包)
-
也是正则表达式。
-
如果从上述规则派生出字符串,则该字符串也将是正则表达式。
正则表达式的例子
下表显示了一些正则表达式示例-
| Regular Expressions | Regular Set |
|---|---|
| (0 + 10*) | {0, 1, 10, 100, 1000, 10000, … } |
| (0*10*) | {1, 01, 10, 010, 0010, …} |
| (0 + ε)(1 + ε) | {ε, 0, 1, 01} |
| (a+b)* | It would be set of strings of a’s and b’s of any length which also includes the null string i.e. {ε, a, b, aa , ab , bb , ba, aaa…….} |
| (a+b)*abb | It would be set of strings of a’s and b’s ending with the string abb i.e. {abb, aabb, babb, aaabb, ababb, …………..} |
| (11)* | It would be set consisting of even number of 1’s which also includes an empty string i.e. {ε, 11, 1111, 111111, ……….} |
| (aa)*(bb)*b | It would be set of strings consisting of even number of a’s followed by odd number of b’s i.e. {b, aab, aabbb, aabbbbb, aaaab, aaaabbb, …………..} |
| (aa + ab + ba + bb)* | It would be string of a’s and b’s of even length that can be obtained by concatenating any combination of the strings aa, ab, ba and bb including null i.e. {aa, ab, ba, bb, aaab, aaba, …………..} |
正则集及其属性
它可以定义为代表正则表达式的值并包含特定属性的集合。
常规集的属性
-
如果我们将两个常规集合进行并集,则所得集合也将成为规则。
-
如果我们做两个规则集的交集,那么结果集也将是规则的。
-
如果我们对常规集进行补充,那么结果集也将是常规的。
-
如果我们做两个常规集的差,那么结果集也将是常规的。
-
如果我们进行常规集的逆转,则结果集也将是常规的。
-
如果我们关闭常规集,则结果集也将是常规的。
-
如果我们将两个常规集进行串联,那么结果集也将是常规的。
有限状态自动机
源自希腊语“αὐτόματα”的意思是“自作用”,是自动机的复数形式,可以定义为自动遵循预定操作顺序的抽象自走式计算设备。
具有有限状态数的自动机称为有限自动机(FA)或有限状态自动机(FSA)。
在数学上,自动机可以用5元组(Q,Σ,δ,q0,F)表示,其中-
-
Q是一组有限的状态。
-
Σ是一组有限的符号,称为自动机的字母。
-
δ是转移函数
-
q0是处理任何输入的初始状态(q0∈Q)。
-
F是Q的一组最终状态(F⊆Q)。
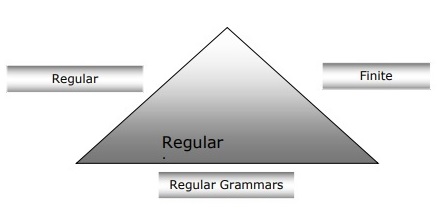
有限自动机,正则语法和正则表达式之间的关系
以下几点将使我们对有限自动机,正则语法和正则表达式之间的关系有清晰的认识-
-
众所周知,有限状态自动机是计算工作的理论基础,而正则表达式是描述它们的一种方式。
-
我们可以说任何正则表达式都可以实现为FSA,并且任何FSA都可以用正则表达式描述。
-
另一方面,正则表达式是表征一种称为正则语言的语言的方式。因此,我们可以说,可以借助FSA和正则表达式来描述正则语言。
-
规则语法是可以描述规则语言的另一种方法,它可以是右规则或左规则的形式语法。
下图显示了有限自动机,正则表达式和正则语法是描述正则语言的等效方法。
有限状态自动化(FSA)的类型
有限状态自动化有两种类型。让我们看看类型是什么。
确定性有限自动化(DFA)
它可以定义为有限自动化的类型,其中,对于每个输入符号,我们可以确定机器将要移动到的状态。它具有有限数量的状态,这就是为什么将该机器称为确定性有限自动机(DFA)的原因。
在数学上,DFA可以由5元组(Q,Σ,δ,q0,F)表示,其中-
-
Q是一组有限的状态。
-
Σ是一组有限的符号,称为自动机的字母。
-
δ是转移函数,其中δ:Q×Σ→Q。
-
q0是处理任何输入的初始状态(q0∈Q)。
-
F是Q的一组最终状态(F⊆Q)。
而在图形上,DFA可以通过称为状态图的图来表示,其中-
-
状态由顶点表示。
-
过渡用标记的弧线表示。
-
初始状态由空的传入弧表示。
-
最终状态由双圈表示。
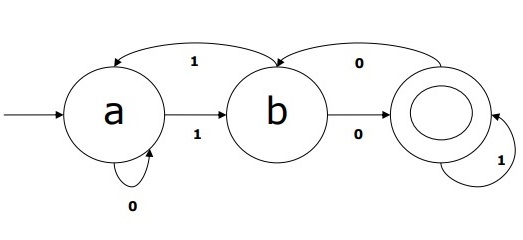
DFA示例
假设DFA为
-
Q = {a,b,c},
-
Σ= {0,1},
-
q 0 = {a},
-
F = {c},
-
过渡函数δ如下表所示-
| Current State | Next State for Input 0 | Next State for Input 1 |
|---|---|---|
| A | a | B |
| B | b | A |
| C | c | C |
此DFA的图形表示如下-
非确定性有限自动化(NDFA)
可以将其定义为有限自动化的类型,其中对于每个输入符号,我们都无法确定机器将要移动到的状态,即机器可以移动到状态的任何组合。它具有有限数量的状态,这就是为什么将该机器称为不确定性有限自动化(NDFA)的原因。
从数学上讲,NDFA可以用5元组(Q,Σ,δ,q0,F)表示,其中-
-
Q是一组有限的状态。
-
Σ是一组有限的符号,称为自动机的字母。
-
δ:-是转移函数,其中δ:Q×Σ→2 Q。
-
q0:-是处理任何输入的初始状态(q0∈Q)。
-
F:-是Q的一组最终状态(F⊆Q)。
以图形方式(与DFA相同),NDFA可以通过称为状态图的图来表示,其中-
-
状态由顶点表示。
-
过渡用标记的弧线表示。
-
初始状态由空的传入弧表示。
-
最终状态由双圈表示。
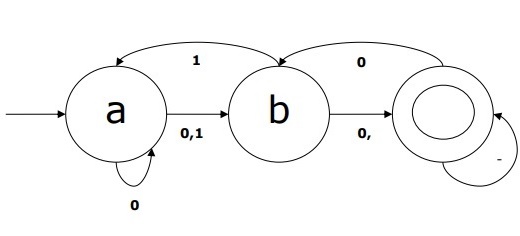
NDFA的例子
假设NDFA为
-
Q = {a,b,c},
-
Σ= {0,1},
-
q 0 = {a},
-
F = {c},
-
过渡函数δ如下表所示-
| Current State | Next State for Input 0 | Next State for Input 1 |
|---|---|---|
| A | a, b | B |
| B | C | a, c |
| C | b, c | C |
此NDFA的图形表示如下-
形态解析
术语词法分析与词素的分析有关。我们可以将形态学解析定义为以下问题:识别单词分解为更小的有意义的单元,称为语素,从而为其产生某种语言结构。例如,我们可以将单词foxes分为两个fox和-es 。我们可以看到单词foxes由两个词素组成,一个是fox ,另一个是-es 。
换句话说,我们可以说形态学是-
-
词的形成。
-
单词的由来。
-
单词的语法形式。
-
在单词形成中使用前缀和后缀。
-
语言的词性(PoS)的形成方式。
词素的类型
语素是最小的含义单位,可以分为两种类型-
-
茎
-
词序
茎
它是单词的核心意义单元。我们也可以说这是这个词的根源。例如,在单词foxes中,词干是fox。
-
词缀-顾名思义,它们为单词增加了一些其他含义和语法功能。例如,在单词foxes中,后缀是-es。
此外,词缀也可以分为以下四种类型-
-
前缀-顾名思义,前缀在词干之前。例如,在单词unbuckle中,un是前缀。
-
后缀-顾名思义,后缀跟随词根。例如,在单词cats中,-s是后缀。
-
中缀-顾名思义,中缀插入到茎中。例如,单词cupful可通过使用-s作为中缀将其复数为cupsful。
-
后缀-他们在词干之前和之后。很少有用英语做的绕环的例子。一个非常常见的示例是“ A-ing”,其中我们可以在词干之前使用-A,然后使用-ing。
词序
单词的顺序将通过词法分析来确定。现在让我们看看构建形态解析器的要求-
词典
建立词法分析器的第一个要求是词典,它包括词干和词缀的列表以及有关它们的基本信息。例如,诸如词干是名词词干还是动词词干等信息。
形态策略
它基本上是词素排序的模型。换句话说,解释词素中哪些词素类别可以跟随词素的其他类别的模型。例如,词法策略事实是英语复数词素总是跟随名词而不是名词。
拼字规则
这些拼写规则用于对单词中发生的变化进行建模。例如,将y转换为ie的规则,例如city + s =城市而不是城市。