- pandas 选择带有子字符串的行 - Python (1)
- 带有Python的AI教程(1)
- 带有Python的AI教程
- Python Pandas DataFrame
- Python Pandas DataFrame(1)
- Python Pandas教程(1)
- Python Pandas教程
- pandas 显示带有正则表达式的列 - Python 代码示例
- pandas 显示带有正则表达式的列 - Python (1)
- pandas python 教程 - Python 代码示例
- pandas python 教程 - Python (1)
- Python Pandas| Python Pandas教程
- Python Pandas| Python Pandas教程(1)
- 带有示例的C++中的方法与函数(1)
- 带有示例的C++中的方法与函数
- Python中的 pandas.DataFrame.T()函数
- Python中的 pandas.DataFrame.T()函数(1)
- 带有列名的 pandas 空数据框 - Python 代码示例
- Python – 删除带有子字符串值的键
- Python – 删除带有子字符串值的键(1)
- 带有 IN 的 pandas 过滤列 - Python 代码示例
- 带有列名的 pandas 空数据框 - Python (1)
- 如何在 pandas 中删除带有 nan 的行 - Python 代码示例
- 带有条件的 pandas 数据帧总和 - Python 代码示例
- 如何在 pandas 中删除带有 nan 的行 - Python (1)
- pandas 显示带有正则表达式的列 - Javascript 代码示例
- 带有条件的 pandas 数据帧总和 - Python (1)
- Python | Pandas 数据 DataFrame(1)
- Python | Pandas 数据 DataFrame
📅 最后修改于: 2020-08-31 06:43:37 🧑 作者: Mango
Pandas是用于数据分析的开源Python库。它旨在高效,直观地处理和处理结构化数据。
熊猫的两个主要数据结构是Series和DataFrame。Series本质上是任何类型的数据的一维标记数组,而DataFrames是具有潜在异构数据类型的二维的,任何类型的数据标记数组。异构意味着并非所有“行”都必须具有相同的大小。
在本文中,我们将介绍创建DataFrame和更改其结构的方法的最常用方法。
我们将使用Jupyter Notebook,因为它可以很好地呈现DataFrames。不过,任何IDE都可以完成此工作,只需print()在DataFrame对象上调用一条语句即可。
创建数据框
无论何时创建DataFrame,无论是手动创建一个还是从文件之类的数据源生成一个,都必须以表格的形式对数据进行排序,即包含数据的行序列。
这意味着各行共享相同的字段顺序,即,如果要DataFrame获取有关某人的姓名和年龄的信息,则要确保所有行都以相同的方式保存该信息。
任何差异都会导致DataFrame出现故障,从而导致错误。
创建一个空的DataFrame
创建一个空DataFrame很简单:
import pandas as pd
dataFrame1 = pd.DataFrame()我们将研究如何DataFrame在操纵行和列的结构时向其添加行和列。
从列表创建数据框
遵循“具有相同字段顺序的行的顺序”的原则,您可以DataFrame从包含此类序列的列表中创建一个,也可以从多个列表中创建一个zip()-ed,从而以这样的方式提供一个序列:
import pandas as pd
listPepper = [
[50, "Bell pepper", "Not even spicy"],
[5000, "Espelette pepper", "Uncomfortable"],
[500000, "Chocolate habanero", "Practically ate pepper spray"]
]
dataFrame1 = pd.DataFrame(listPepper)
dataFrame1
# If you aren't using Jupyter, you'll have to call `print()`
# print(dataFrame1)
结果是:

通过将数据放在多个列表中并将zip()它们组合在一起,可以达到相同的效果。当为我们拥有的数据提供单个列(字段)的值列表时,可以使用这种方法,而不是前面提到的列表包含每个特定行的数据作为单位的方式。
意味着我们分别拥有按列的所有数据(按顺序),这些数据压缩在一起后就创建行。
您可能已经注意到,在DataFrame我们创建的列和行标签中,信息不是很丰富。创建时DataFrame,您可以传递其他信息,您可以做的一件事就是给您要使用的行/列标签:
import pandas as pd
listScoville = [50, 5000, 500000]
listName = ["Bell pepper", "Espelette pepper", "Chocolate habanero"]
listFeeling = ["Not even spicy", "Uncomfortable", "Practically ate pepper spray"]
dataFrame1 = pd.DataFrame(zip(listScoville, listName, listFeeling), columns = ['Scoville', 'Name', 'Feeling'])
# Print the dataframe
dataFrame1
这将为我们提供与以前相同的输出,只是具有更有意义的列名:

您可以在此处使用的另一种数据表示形式是以下列格式将数据作为字典列表提供:
listPepper = [
{ columnName1 : valueForRow1, columnName2: valueForRow1, ... },
{ columnName1 : valueForRow2, columnName2: valueForRow2, ... },
...
]在我们的示例中,表示形式如下所示:
listPepper = [
{'Scoville' : 50, 'Name' : 'Bell pepper', 'Feeling' : 'Not even spicy'},
{'Scoville' : 5000, 'Name' : 'Espelette pepper', 'Feeling' : 'Uncomfortable'},
{'Scoville' : 500000, 'Name' : 'Chocolate habanero', 'Feeling' : 'Practically ate pepper spray'},
]我们将以DataFrame与之前相同的方式创建:
dataFrame1 = pd.DataFrame(listPepper)
从字典创建数据框
字典是以列方式提供数据的另一种方式。每列均按顺序列出了行所包含的值的列表:
dictionaryData = {
'columnName1' : [valueForRow1, valueForRow2, valueForRow3...],
'columnName2' : [valueForRow1, valueForRow2, valueForRow3...],
....
}我们使用字典格式表示与之前相同的数据:
import pandas as pd
dictionaryData = {
'Scoville' : [50, 5000, 500000],
'Name' : ["Bell pepper", "Espelette pepper", "Chocolate habanero"],
'Feeling' : ["Not even spicy", "Uncomfortable", "Practically ate pepper spray"]
}
dataFrame1 = pd.DataFrame(dictionaryData)
# Print the dataframe
dataFrame1
这给了我们预期的输出:

从文件读取DataFrame
有许多支持读取和写入DataFrame的文件类型。每个相应的文件类型函数遵循相同的语法read_filetype(),例如read_csv(),read_excel(),read_json(),read_html(),等…
一个非常常见的文件类型是.csv(逗号分隔值)。这些行以行的形式提供,它们应该包含的值之间用定界符(通常是逗号)分隔。您可以通过sep参数设置另一个定界符。
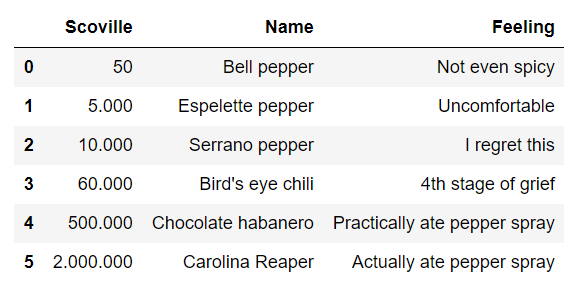
如果您不熟悉.csv文件类型,则可以使用以下示例:
Scoville, Name, Feeling
50, Bell pepper, Not even spicy
5.000, Espelette pepper, Uncomfortable
10.000, Serrano pepper, I regret this
60.000, Bird's eye chili, 4th stage of grief
500.000, Chocolate habanero, Practically ate pepper spray
2.000.000, Carolina Reaper, Actually ate pepper spray请注意,文件中的第一行是列名。当然,您可以指定Pandas应该从哪一行开始读取数据,但是默认情况下,Pandas将第一行视为列名,并从第二行开始加载数据:
import pandas as pd
pepperDataFrame = pd.read_csv('pepper_example.csv')
# For other separators, provide the `sep` argument
# pepperDataFrame = pd.read_csv('pepper_example.csv', sep=';')
pepperDataFrame
#print(pepperDataFrame)这给了我们输出:
操纵数据框
本节将介绍更改DataFrame的结构的基本方法。但是,在进入该主题之前,您应该知道如何访问单个行或行组以及列。
访问/定位元素
熊猫有两种选择数据的方式- loc[]和iloc[]。
loc[]允许您使用标签来选择行和列,例如row [‘Value’]和column [‘Other Value’]。同时,iloc[]要求您输入要选择的条目的索引,因此只能使用数字。您也可以仅通过在方括号中输入其名称来选择列。让我们看看它如何起作用:
# Location by label
# Here, '5' is treated as the *label* of the index, not its value
print(pepperDataFrame.loc[5])
# Location by index
print(pepperDataFrame.iloc[1]) 输出:
Scoville 2.000.000
Name Carolina Reaper
Feeling Actually ate pepper spray
Name: 5, dtype: object
Scoville 5.000
Name Espelette pepper
Feeling Uncomfortable
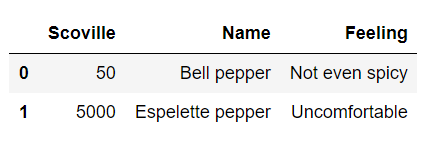
Name: 1, dtype: object这也适用于一组行,例如从0 … n开始:
print(pepperDataFrame.loc[:1]) 输出:
重要的是要注意iloc[]始终期望一个整数。loc[]也支持其他数据类型。我们也可以在这里使用整数,尽管我们也可以使用其他数据类型,例如字符串。
您还可以访问元素的特定值。例如,尽管只返回其Name值,我们可能想访问第二行中的元素:
print(pepperDataFrame.loc[2, 'Name'])返回:
Chocolate habanero 访问列就像编写dataFrameName.ColumnName或一样简单dataFrameName['ColumnName']。首选第二个选项,因为该列可以与预定义的Pandas方法具有相同的名称,在这种情况下使用第一个选项可能会导致错误:
print(pepperDataFrame['Name'])
# Same output as print(pepperDataFrame.Name)输出:
0 Bell pepper
1 Espelette pepper
2 Chocolate habanero
Name: Name, dtype: object也可以使用loc[]和来访问列iloc[]。例如,我们将访问所有的行,从0...n哪里n是行数并获取第一列。与上一行代码具有相同的输出:
dataFrame1.iloc[:, 1] # or dataFrame1.loc[:, 'Name']操纵指数
索引是中的行标签DataFrame,它们是我们要访问行时使用的标签。由于我们没有更改Pandas DataFrame在创建s时分配给s 的默认索引,因此我们所有的行均已标记为0至更高的整数。
我们可以更改索引的DataFrame第set_index()一种方法是使用方法。我们将我们中的任何列传递给DataFrame该方法,它将成为新的索引。因此,我们既可以自己创建索引,也可以简单地将一列指定为索引。
请注意,该方法不会更改原始方法,DataFrame而是返回DataFrame带有新索引的新方法,因此,DataFrame如果要保留更改,必须将返回值分配给变量,或将inplace标志设置为True:
import pandas as pd
listPepper = [
{'Scoville' : 50, 'Name' : 'Bell pepper', 'Feeling' : 'Not even spicy'},
{'Scoville' : 5000, 'Name' : 'Espelette pepper', 'Feeling' : 'Uncomfortable'},
{'Scoville' : 500000, 'Name' : 'Chocolate habanero', 'Feeling' : 'Practically ate pepper spray'},
]
dataFrame1 = pd.DataFrame(listPepper)
dataFrame2 = dataFrame1.set_index('Scoville')
dataFrame2输出:

这同样适用:
dataFrame1 = pd.DataFrame(listPepper)
dataFrame1.set_index('Scoville', inplace=True)
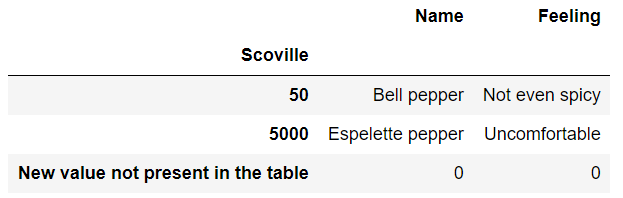
dataFrame1 现在我们有了一个非默认索引,我们可以使用一组新的值,使用reindex(),Pandas将自动NaN为每个与现有行不匹配的索引填充值:
new_index = [50, 5000, 'New value not present in the data frame']
dataFrame1.reindex(new_index)输出:

您可以通过设置可选参数来控制Pandas使用哪些值来填写缺失值fill_value:
dataFrame1.reindex(new_index, fill_value=0)输出:
由于我们为设置了新索引DataFrame,因此loc[]现在可以使用该索引:
dataFrame1.loc[5000]
# dataFrame1.iloc[5000] outputs the same in this case结果是:
Name Espelette pepper
Feeling Uncomfortable
Name: 5000, dtype: object操纵行
如果您愿意使用,则添加和删除行将变得很简单loc[]。如果设置的行不存在,则会创建该行:
dataFrame1.loc[50] = [10000, 'Serrano pepper', 'I regret this']
dataFrame1输出:

并且,如果要删除行,则可以指定该行在drop()函数中的索引。它带有一个可选参数axis。的axis接受0/ index或1/ columns。依赖于此,该drop()函数将删除被调用的行或被调用的列。
不指定为一个值axis参数将删除默认相应的列,如axis为0默认为:
dataFrame1.drop(1, inplace=True)
# Same as dataFrame1.drop(1, axis=0)输出:

您还可以重命名表中已经存在的行。该rename()函数接受您希望进行的更改的词典:
dataFrame1.rename({0:"First", 1:"Second"}, inplace=True)输出:

请注意,drop()并且rename()还接受可选参数- inplace。将此设置为True(False默认情况下)将告诉Pandas更改原始DataFrame而不是返回新的。如果未设置,则必须将结果打包DataFrame到一个新的文件中以保留更改。
您应该知道的另一种有用的方法是该drop_duplicates()函数从中删除所有重复的行DataFrame。让我们通过添加两个重复的行来演示这一点:
dataFrame1.loc[3] = [60.000, "Bird's eye chili", "4th stage of grief"]
dataFrame1.loc[4] = [60.000, "Bird's eye chili", "4th stage of grief"]
dataFrame1这给了我们输出:

现在我们可以致电drop_duplicates():
dataFrame1.drop_duplicates(inplace=True)
dataFrame1并且重复的行将被删除:

操作列
可以通过与添加行类似的方式添加新列:
dataFrame1['Color'] = ['Green', 'Bright Red', 'Brown']
dataFrame1输出:

同样类似于行,可以通过调用drop()函数来删除列,唯一的区别是必须将可选参数设置为axis,1以便Pandas知道要删除列而不是行:
dataFrame1.drop('Feeling', axis=1, inplace=True)输出:

在重命名列时,rename()需要特别告知该函数,我们的意思是通过将可选参数设置为columns“更改字典”的值来更改列:
dataFrame1.rename(columns={"Feeling":"Measure of Pain"}, inplace=True)输出:

此外,同样与删除/重命名行,您可以设置可选的参数inplace来True,如果你想在原来的DataFrame,而不是修改的函数返回一个新的DataFrame。
结论
在本文中,我们讨论了Pandas DataFrame是什么,因为它们是Pandas框架中用于存储数据的关键类。
我们已经学习了如何DataFrame使用列表和字典手动创建手册,然后再从文件中读取数据。
然后,我们在DataFrame-中使用loc[]和操作数据iloc[],找到了数据,创建了新的行和列,重命名了现有的行和列,然后将其删除。