- Weka-安装
- Weka-安装(1)
- Weka教程(1)
- Weka教程
- Weka-简介
- Weka-简介(1)
- 讨论Weka(1)
- 讨论Weka
- Weka-加载数据(1)
- Weka-加载数据
- 如何在 Windows 上安装 Weka?
- 如何在 Windows 上安装 Weka?(1)
- 如何使用 Weka Java API?(1)
- 如何使用 Weka Java API?
- Weka-分类器(1)
- Weka-分类器
- Weka-有用的资源
- Weka-有用的资源(1)
- 如何在 MacOS 上安装 Weka?
- 如何在 MacOS 上安装 Weka?(1)
- Weka-文件格式
- Weka-文件格式(1)
- Weka-群集
- Weka-协会
- Weka-协会(1)
- Weka-群集(1)
- Weka-预处理数据
- Weka-预处理数据(1)
- Weka-启动资源管理器
📅 最后修改于: 2020-11-28 14:22:46 🧑 作者: Mango
当数据库包含大量属性时,将有几个属性在您当前正在寻找的分析中不重要。因此,从数据集中删除不需要的属性成为开发良好的机器学习模型的重要任务。
您可以目视检查整个数据集,并确定不相关的属性。对于包含大量属性的数据库(例如您在上一课中看到的超级市场案例)而言,这可能是一项艰巨的任务。幸运的是,WEKA提供了用于功能选择的自动化工具。
本章将在包含大量属性的数据库上演示此功能。
加载数据中
在WEKA资源管理器的“预处理”标签中,选择labour.arff文件以加载到系统中。加载数据时,您将看到以下屏幕-
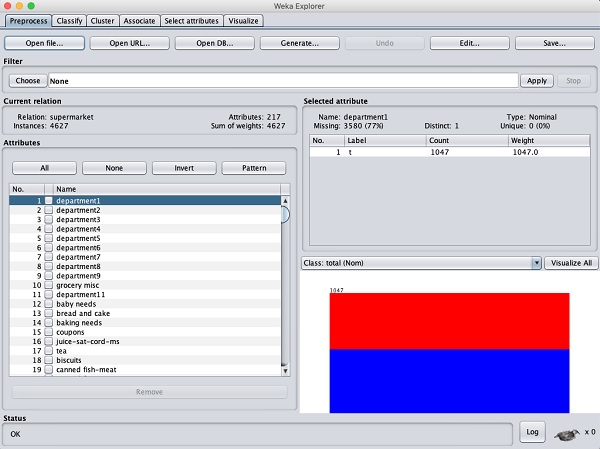
请注意,这里有17个属性。我们的任务是通过消除一些与我们的分析无关的属性来创建简化的数据集。
特征提取
单击选择属性选项卡。您将看到以下屏幕-
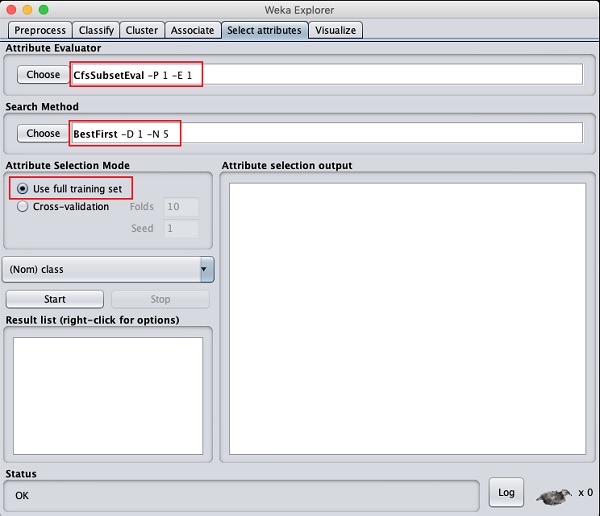
在Attribute Evaluator和Search Method下,您将找到几个选项。我们将在这里使用默认值。在“属性选择模式”中,使用完整的训练集选项。
单击开始按钮以处理数据集。您将看到以下输出-
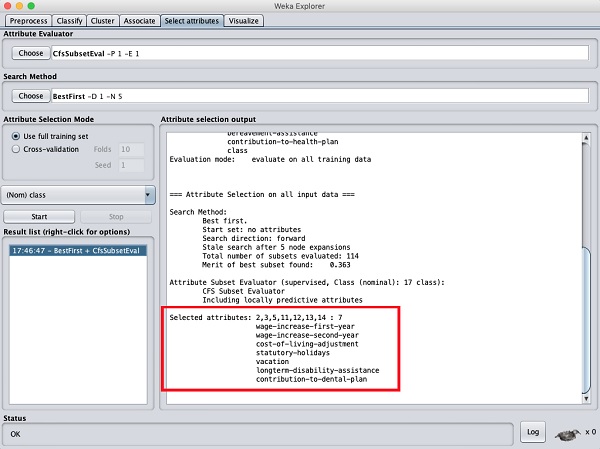
在结果窗口的底部,您将获得Selected属性的列表。要获得视觉效果,请在“结果”列表中右键单击结果。
输出显示在以下屏幕截图中-

单击任何正方形将为您提供用于进一步分析的数据图。典型的数据图如下所示-
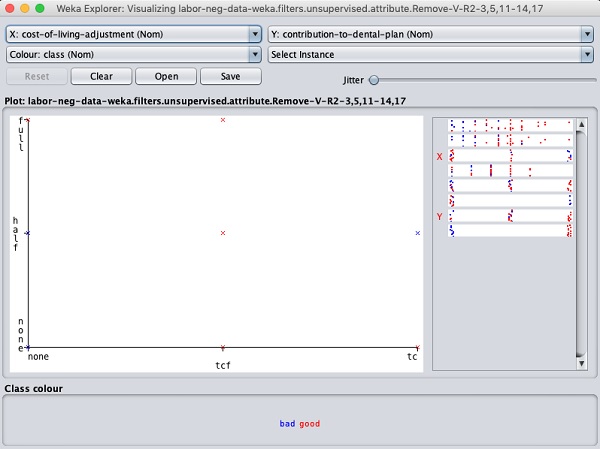
这与我们在前面几章中看到的相似。尝试各种可用选项来分析结果。
下一步是什么?
到目前为止,您已经看到了WEKA在快速开发机器学习模型中的强大功能。我们使用的是称为Explorer的图形工具,用于开发这些模型。 WEKA还提供了一个命令行界面,该界面比资源管理器中提供的功能更多。
单击G UI Chooser应用程序中的Simple CLI按钮可启动此命令行界面,如下面的屏幕快照所示-
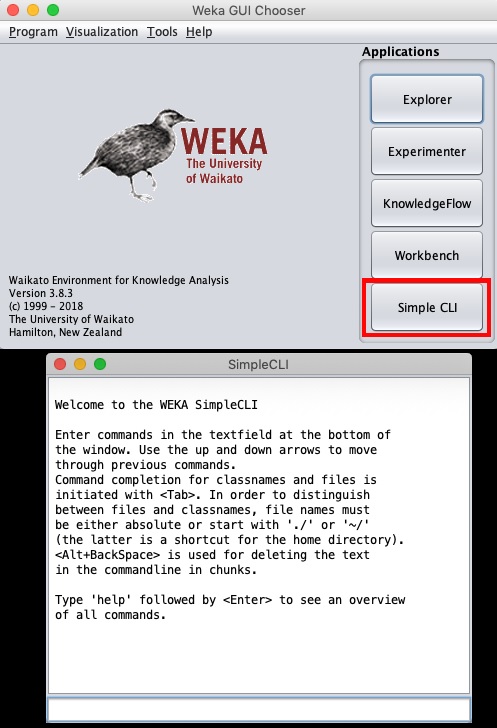
在底部的输入框中键入命令。您将能够完成到目前为止在资源管理器中所做的所有工作,还有更多其他功能。有关更多详细信息,请参阅WEKA文档(https://www.cs.waikato.ac.nz/ml/weka/documentation.html)。
最后,WEKA是用Java开发的,并提供了与其API的接口。因此,如果您是Java开发人员并且热衷于在自己的Java项目中包含WEKA ML实现,则可以轻松实现。
结论
WEKA是用于开发机器学习模型的强大工具。它提供了几种最广泛使用的ML算法的实现。在将这些算法应用于数据集之前,还可以对数据进行预处理。支持的算法类型分为“分类”,“群集”,“关联”和“选择”属性。可以通过美观而强大的视觉表示来可视化处理各个阶段的结果。这使数据科学家可以更轻松地在其数据集上快速应用各种机器学习技术,比较结果并为最终使用创建最佳模型。