多版本时间戳排序
在多版本时间戳排序技术中,对于系统中的每个事务,在事务开始执行之前分配一个唯一的时间戳。事务 T 的时间戳记为 TS(T)。对于每个数据项 X,一系列版本
对于数据项(X)的每个版本 X i ,系统维护以下三个字段:
- 版本的值。
- Read_TS (X i ):X i的读取时间戳是任何成功读取版本 X i的事务的最大时间戳。
- Write_TS(X i ):X i的写入时间戳是任何成功写入版本 X i的事务的最大时间戳。
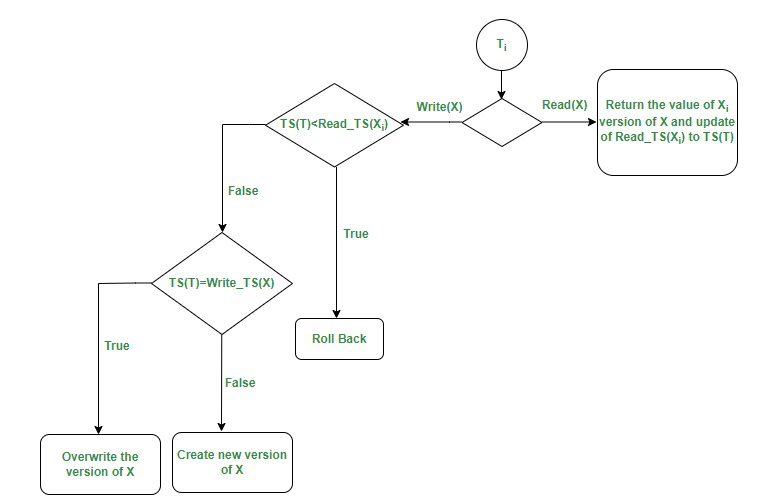
为确保可序列化,使用以下两条规则:
假设事务 T 对数据项 X 发出读取请求和写入请求。设 X i为 X 的所有版本中具有最大 Write_TS(X i ) 的版本,该版本也小于或等于 TS(T) .
- 规则一:假设事务 T 发出 Read(X) 请求,如果 Read_TS(X i )
- 规则 2:假设事务 T 发出 Write(X) 请求 TS(T) < Read_TS(X),则系统中止事务 T。另一方面,如果 TS(T) = Write_TS(X),则系统覆盖X的内容;如果 TS(T)>Write_TS(X) 它创建一个新版本的 X。
例子:
考虑以下时间表
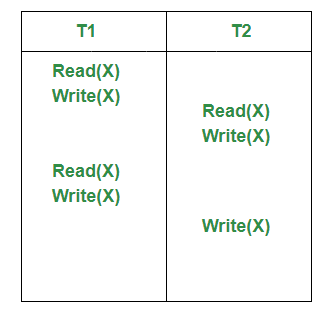
让事务 T1 和 T2 的时间戳分别为 5 和 10。这些事务对数据项 X 执行读写操作。
- 最初假设数据项X的状态是X 0并且Read_TS(X 0 )=Write_TS(X 0 )=0
- T1 执行 Read(X),因为 Read_TS(X 0 )
- T1 执行 Write(X),因为 Write_TS(X 0 )
- T2 执行 Read(X),因为 Read_TS(X 1 )
- T2 执行 Write(X),因为 Write_TS(X 1 )
- T1 执行 Read(X),在正常的时间戳排序中,这将中止 T1(以及随后的 T2),因为 T2 已经覆盖了 X。由于我们保留了以前的版本,我们读取 X 1而不是 X 2并且读取成功。
- T1 执行 Write(X),因为 TS(T1)
- 由于 T2 在 T1 中止时已读取 X 1 ,因此它级联到 T2 并且 T2 中止。
优点:
- 事务的读取请求永远不会失败,也永远不会等待。
- 它在读取请求比写入请求更频繁的数据库系统中找到了应用。
缺点:
- 读取数据项需要更新读取时间戳字段,从而导致两次潜在的磁盘访问,而不是一次。
- 事务之间的冲突是通过回滚解决的,而不是通过等待。这种替代方案可能很昂贵。
- 多版本时间戳排序方案不能确保可恢复性和级联性。