- Hadoop – HDFS(Hadoop 分布式文件系统)(1)
- Hadoop – HDFS(Hadoop 分布式文件系统)
- 分布式文件系统
- 分布式文件系统(1)
- Hadoop分布式文件系统(HDFS)简介(1)
- Hadoop分布式文件系统(HDFS)简介
- Talend-安装
- Talend-安装(1)
- Talend-元数据
- Talend-元数据(1)
- Talend教程
- Talend教程(1)
- 讨论-Talend
- 讨论-Talend(1)
- 分布式文件系统中的文件缓存(1)
- 分布式文件系统中的文件缓存
- Hadoop-流
- Hadoop-流(1)
- hadoop 流 (1)
- Talend 面试经历 |设置 1
- Talend 面试经历 |设置 1(1)
- Talend-Hive
- Talend-Hive(1)
- 什么是DFS(分布式文件系统)?
- Talend-工作设计(1)
- Talend-工作设计
- Hadoop 1 和 Hadoop 2 之间的区别
- Hadoop 1 和 Hadoop 2 之间的区别
- Hadoop 1 和 Hadoop 2 之间的区别(1)
📅 最后修改于: 2020-11-29 08:51:22 🧑 作者: Mango
在本章中,让我们详细了解Talend如何与Hadoop分布式文件系统一起使用。
设置和先决条件
在继续使用HDFS进入Talend之前,我们应了解为此目的应满足的设置和先决条件。
在这里,我们在虚拟机上运行Cloudera quickstart 5.10 VM。此VM中必须使用仅主机网络。
仅限主机的网络IP:192.168.56.101
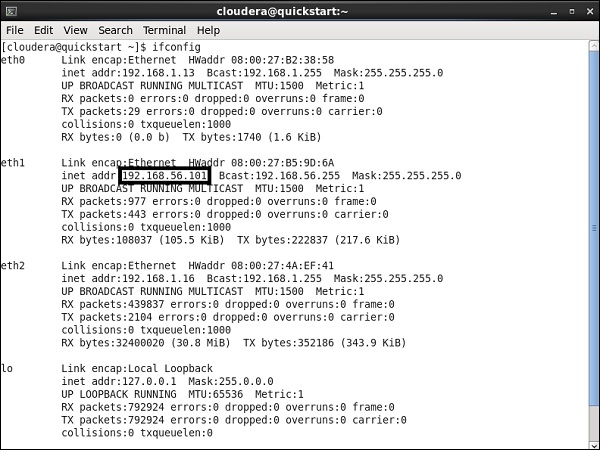
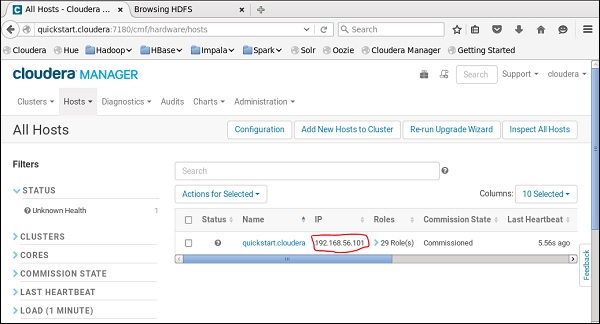
您还必须在cloudera Manager上运行相同的主机。
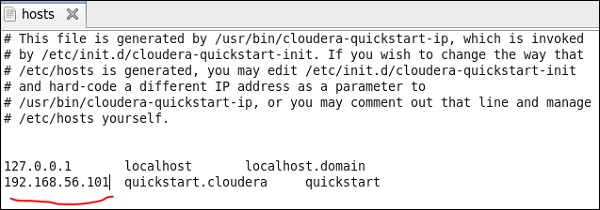
现在,在Windows系统上,转到c:\ Windows \ System32 \ Drivers \ etc \ hosts并使用记事本编辑此文件,如下所示。
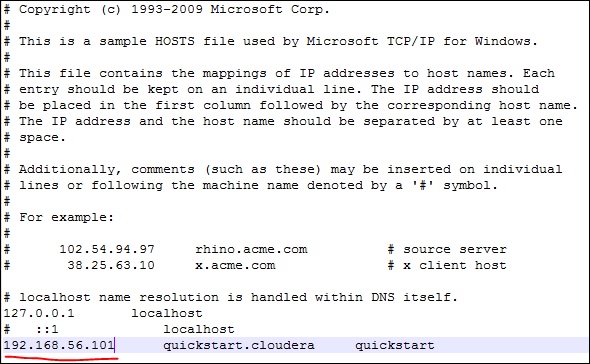
同样,在您的cloudera quickstart VM上,如下所示编辑/ etc / hosts文件。
sudo gedit /etc/hosts
设置Hadoop连接
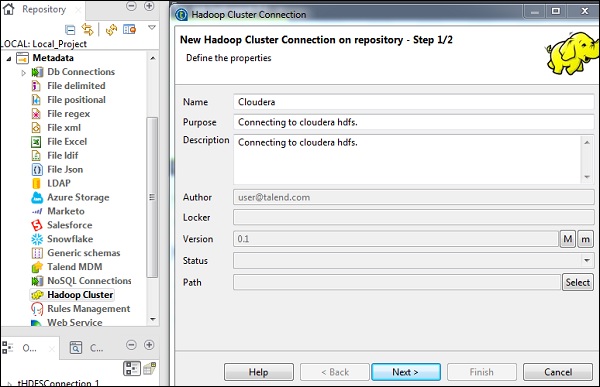
在存储库面板中,转到“元数据”。右键单击“ Hadoop集群”并创建一个新集群。提供此Hadoop群集连接的名称,目的和描述。
点击下一步。
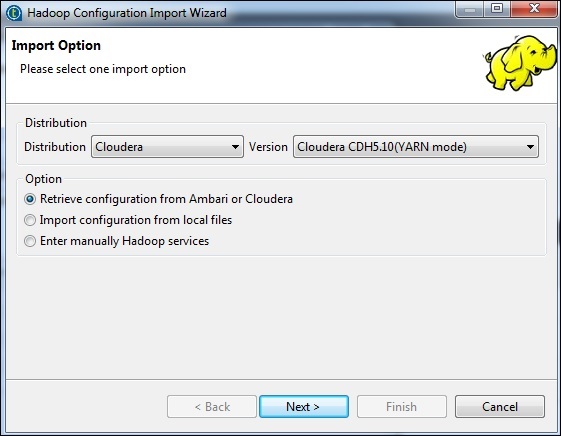
选择发行版作为cloudera并选择您正在使用的版本。选择检索配置选项,然后单击下一步。
输入管理者凭据(带有端口,用户名,密码的URI),如下所示,然后单击“连接”。如果详细信息正确,您将在发现的群集下获得Cloudera QuickStart。
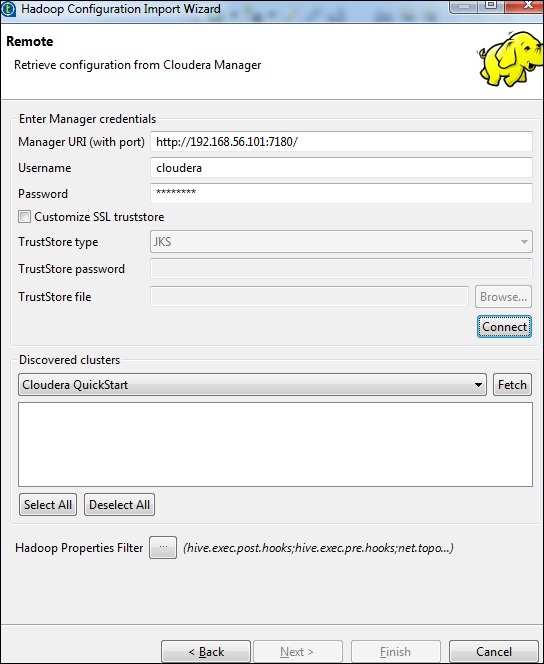
单击获取。这将获取HDFS,YARN,HBASE,HIVE的所有连接和配置。
选择全部,然后单击完成。
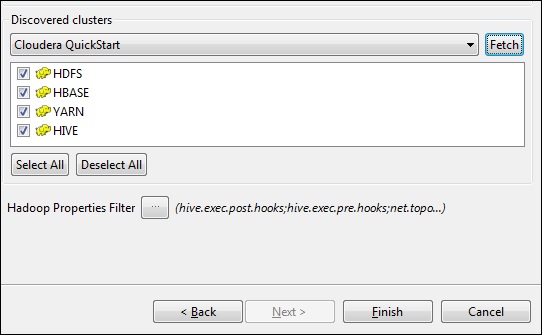
请注意,所有连接参数将被自动填充。在用户名中提及cloudera,然后单击“完成”。
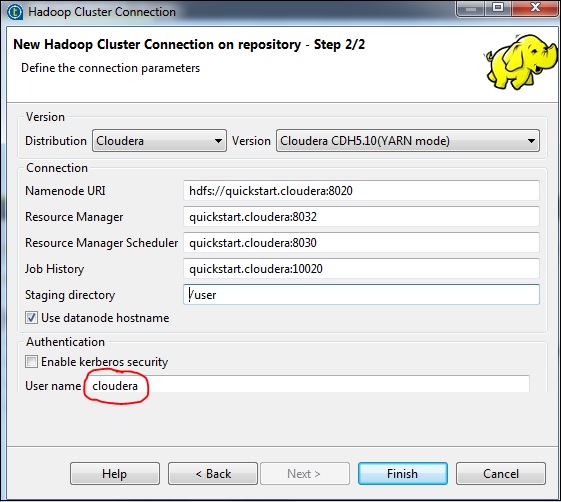
这样,您已成功连接到Hadoop集群。

连接到HDFS
在这项工作中,我们将列出HDFS上存在的所有目录和文件。
首先,我们将创建一个作业,然后向其中添加HDFS组件。右键单击作业设计,然后创建一个新作业– hadoopjob。
现在从面板中添加2个组件– tHDFSConnection和tHDFSList。右键单击tHDFSConnection,然后使用“ OnSubJobOk”触发器连接这两个组件。
现在,配置两个talend hdfs组件。

在tHDFSConnection中,选择“存储库”作为“属性类型”,然后选择您之前创建的Hadoop cloudera集群。它将自动填写此组件所需的所有必要详细信息。

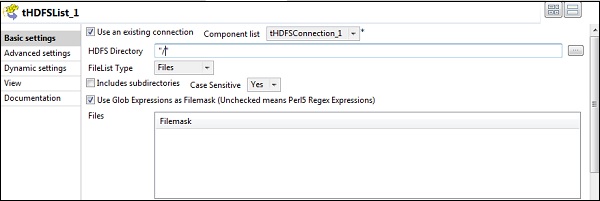
在tHDFSList中,选择“使用现有连接”,然后在组件列表中选择您配置的tHDFSConnection。
在“ HDFS目录”中提供HDFS的主路径,然后单击右侧的“浏览”按钮。
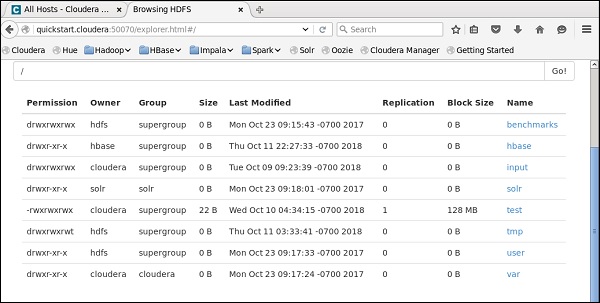
如果使用上述配置正确建立了连接,则会看到如下所示的窗口。它将列出HDFS主页上存在的所有目录和文件。
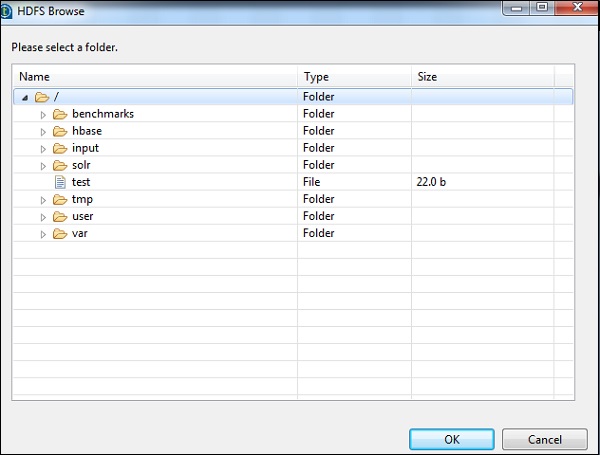
您可以通过在cloudera上检查HDFS来验证这一点。
从HDFS读取文件
在本节中,让我们了解如何在Talend中从HDFS读取文件。您可以为此目的创建一个新作业,但是这里我们使用现有的作业。
将3个组件– tHDFSConnection,tHDFSInput和tLogRow从面板拖放到设计器窗口。
右键单击tHDFSConnection,然后使用“ OnSubJobOk”触发器连接tHDFSInput组件。
右键单击tHDFSInput并将主链接拖动到tLogRow。
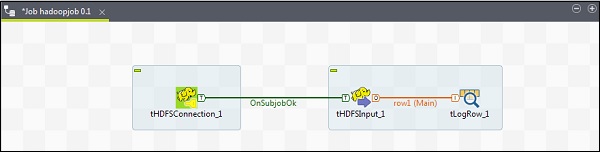
请注意,tHDFSConnection将具有与之前相似的配置。在tHDFSInput中,选择“使用现有连接”,然后从组件列表中选择tHDFSConnection。
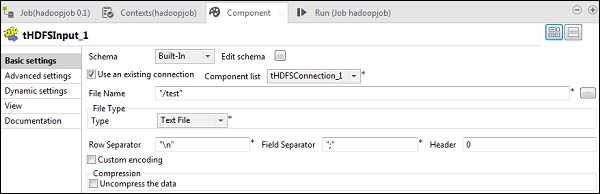
在“文件名”中,提供要读取的文件的HDFS路径。在这里,我们正在阅读一个简单的文本文件,因此我们的文件类型为文本文件。同样,根据您的输入,如下所述填充行分隔符,字段分隔符和标题详细信息。最后,单击“编辑架构”按钮。
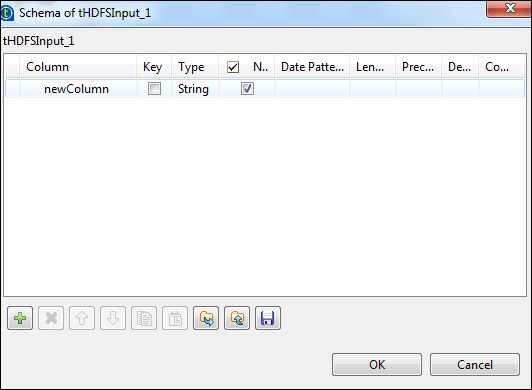
由于我们的文件只有纯文本,因此我们只添加了String类型的一列。现在,单击“确定”。
注-当您的输入具有多个不同类型的列时,您需要在此处相应地提及架构。
在tLogRow组件中,单击“编辑模式中的同步列”。
选择您要打印输出的模式。
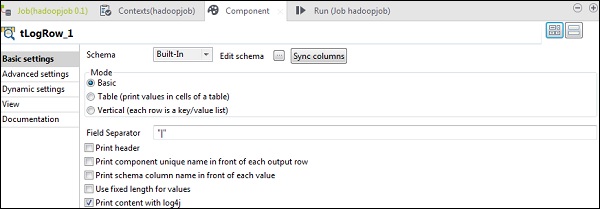
最后,单击“运行”以执行作业。
成功读取HDFS文件后,您将看到以下输出。
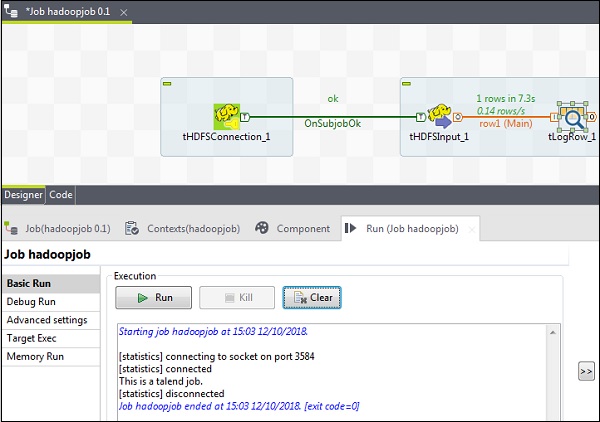
将文件写入HDFS
让我们看看如何在Talend中从HDFS写入文件。将三个组件– tHDFSConnection,tFileInputDelimited和tHDFSOutput从面板拖放到设计器窗口。
右键单击tHDFSConnection,然后使用“ OnSubJobOk”触发器连接tFileInputDelimited组件。
右键单击tFileInputDelimited并将主链接拖动到tHDFSOutput。
请注意,tHDFSConnection将具有与之前相似的配置。
现在,在tFileInputDelimited中,在File name / Stream选项中提供输入文件的路径。在这里,我们使用csv文件作为输入,因此字段分隔符为“,”。
根据您的输入文件选择页眉,页脚,限制。请注意,此处的标头为1,因为1行包含列名,而限制为3,因为我们仅将前3行写入HDFS。
现在,单击编辑架构。
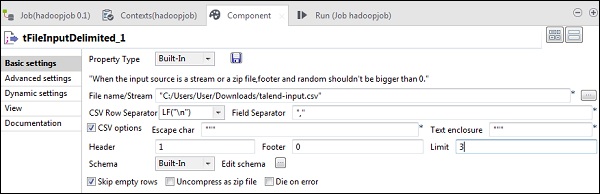
现在,根据我们的输入文件,定义架构。我们的输入文件有3列,如下所述。
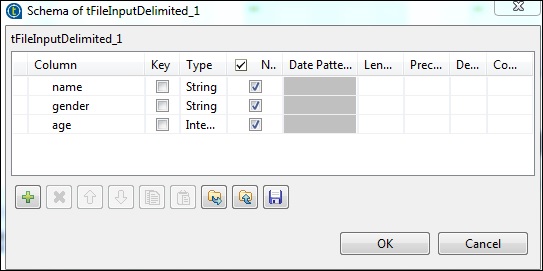
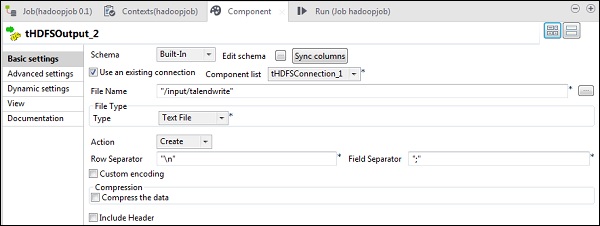
在tHDFSOutput组件中,单击“同步”列。然后,在“使用现有连接”中选择“ tHDFSConnection”。另外,在“文件名”中,提供要在其中写入文件的HDFS路径。
请注意,文件类型将为文本文件,操作将为“创建”,行分隔符为“ \ n”,字段分隔符为“;”。
最后,单击运行以执行您的作业。作业成功执行后,检查文件是否在HDFS上。
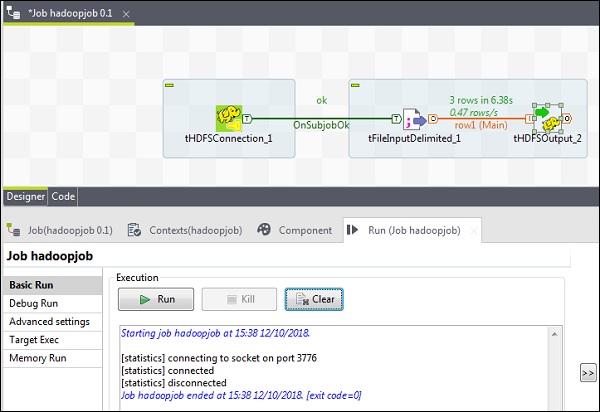
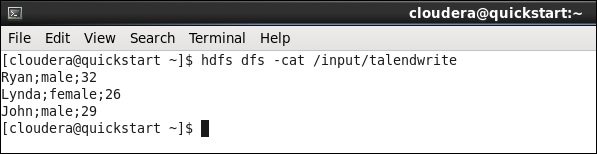
使用您在作业中提到的输出路径运行以下hdfs命令。
hdfs dfs -cat /input/talendwrite
如果您在HDFS上成功编写,将看到以下输出。