- 猪和Hive的区别(1)
- 猪和Hive的区别
- 猪和Hive的区别
- Hive – 删除表(1)
- Hive – 删除表
- Hive-创建表
- Hive-创建表(1)
- Hive-安装
- Hive-安装(1)
- 什么是Hive
- 什么是Hive(1)
- Hive更改表(1)
- Hive更改表
- 如何在Hive创建表?
- 如何在Hive创建表?(1)
- Hive中的存储桶(1)
- Hive中的存储桶
- Hive教程
- Hive教程(1)
- 猪和Hive之间的区别(1)
- 猪和Hive之间的区别
- 讨论Hive(1)
- 讨论Hive
- HIVE概述
- HIVE概述(1)
- Hive数据类型
- Hive-数据类型
- Hive-数据类型(1)
- Hive数据类型(1)
📅 最后修改于: 2020-11-30 04:49:29 🧑 作者: Mango
术语“大数据”用于大型数据集的集合,这些数据集包括庞大的数据量,高速度以及各种数据,这些数据每天都在增加。使用传统的数据管理系统,很难处理大数据。因此,Apache Software Foundation引入了一个名为Hadoop的框架来解决大数据管理和处理难题。
Hadoop的
Hadoop是一个开放源代码框架,用于在分布式环境中存储和处理大数据。它包含两个模块,一个是MapReduce,另一个是Hadoop分布式文件系统(HDFS)。
-
MapReduce:这是一个并行编程模型,用于在大型商品硬件集群上处理大量结构化,半结构化和非结构化数据。
-
HDFS: Hadoop分布式文件系统是Hadoop框架的一部分,用于存储和处理数据集。它提供了可在商用硬件上运行的容错文件系统。
Hadoop生态系统包含用于帮助Hadoop模块的不同子项目(工具),例如Sqoop,Pig和Hive。
-
Sqoop:用于在HDFS和RDBMS之间导入和导出数据。
-
Pig:它是一种过程语言平台,用于为MapReduce操作开发脚本。
-
蜂巢:这是一个用于开发SQL类型脚本以执行MapReduce操作的平台。
注意:有多种执行MapReduce操作的方法:
- 使用Java MapReduce程序的传统方法用于结构化,半结构化和非结构化数据。
- MapReduce的脚本方法使用Pig来处理结构化和半结构化数据。
- MapReduce的Hive查询语言(HiveQL或HQL),以使用Hive处理结构化数据。
什么是蜂巢
Hive是一个数据仓库基础架构工具,用于处理Hadoop中的结构化数据。它驻留在Hadoop之上以汇总大数据,并使查询和分析变得容易。
Hive最初是由Facebook开发的,后来Apache软件基金会开始使用它,并以Apache Hive的名义将其作为开源进一步开发。它由不同的公司使用。例如,Amazon在Amazon Elastic MapReduce中使用它。
蜂巢不是
- 关系数据库
- 在线事务处理(OLTP)的设计
- 实时查询和行级更新的语言
蜂巢的特征
- 它将模式存储在数据库中,并将处理后的数据存储到HDFS中。
- 它是为OLAP设计的。
- 它提供了用于查询的SQL类型语言,称为HiveQL或HQL。
- 它是熟悉的,快速的,可伸缩的和可扩展的。
蜂巢的体系结构
以下组件图描述了Hive的体系结构:

该组件图包含不同的单元。下表描述了每个单元:
| Unit Name | Operation |
|---|---|
| User Interface | Hive is a data warehouse infrastructure software that can create interaction between user and HDFS. The user interfaces that Hive supports are Hive Web UI, Hive command line, and Hive HD Insight (In Windows server). |
| Meta Store | Hive chooses respective database servers to store the schema or Metadata of tables, databases, columns in a table, their data types, and HDFS mapping. |
| HiveQL Process Engine | HiveQL is similar to SQL for querying on schema info on the Metastore. It is one of the replacements of traditional approach for MapReduce program. Instead of writing MapReduce program in Java, we can write a query for MapReduce job and process it. |
| Execution Engine | The conjunction part of HiveQL process Engine and MapReduce is Hive Execution Engine. Execution engine processes the query and generates results as same as MapReduce results. It uses the flavor of MapReduce. |
| HDFS or HBASE | Hadoop distributed file system or HBASE are the data storage techniques to store data into file system. |
蜂巢的工作
下图描述了Hive和Hadoop之间的工作流程。
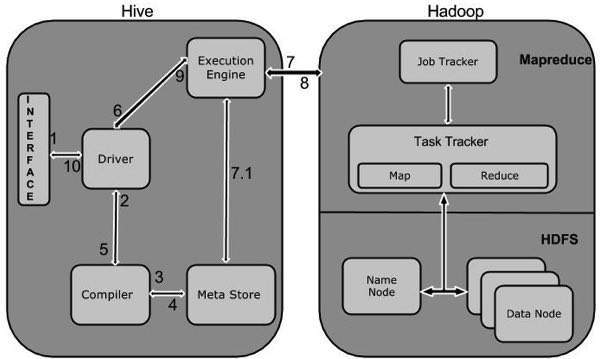
下表定义了Hive与Hadoop框架的交互方式:
| Step No. | Operation |
|---|---|
| 1 | Execute Query
The Hive interface such as Command Line or Web UI sends query to Driver (any database driver such as JDBC, ODBC, etc.) to execute. |
| 2 | Get Plan
The driver takes the help of query compiler that parses the query to check the syntax and query plan or the requirement of query. |
| 3 | Get Metadata
The compiler sends metadata request to Metastore (any database). |
| 4 | Send Metadata
Metastore sends metadata as a response to the compiler. |
| 5 | Send Plan
The compiler checks the requirement and resends the plan to the driver. Up to here, the parsing and compiling of a query is complete. |
| 6 | Execute Plan
The driver sends the execute plan to the execution engine. |
| 7 | Execute Job
Internally, the process of execution job is a MapReduce job. The execution engine sends the job to JobTracker, which is in Name node and it assigns this job to TaskTracker, which is in Data node. Here, the query executes MapReduce job. |
| 7.1 | Metadata Ops
Meanwhile in execution, the execution engine can execute metadata operations with Metastore. |
| 8 | Fetch Result
The execution engine receives the results from Data nodes. |
| 9 | Send Results
The execution engine sends those resultant values to the driver. |
| 10 | Send Results
The driver sends the results to Hive Interfaces. |