📌 相关文章
- 猪和Hive的区别(1)
- 猪和Hive的区别
- 猪和Hive的区别
- Hive – 删除表(1)
- Hive – 删除表
- Hive-创建表(1)
- Hive-创建表
- Hive-安装(1)
- Hive-安装
- 什么是Hive
- 什么是Hive(1)
- Hive更改表
- Hive更改表(1)
- 如何在Hive创建表?(1)
- 如何在Hive创建表?
- Hive教程
- Hive教程(1)
- Hive-简介(1)
- Hive-简介
- 猪和Hive之间的区别
- 猪和Hive之间的区别(1)
- 讨论Hive(1)
- 讨论Hive
- HIVE概述(1)
- HIVE概述
- Hive数据类型
- Hive-数据类型(1)
- Hive数据类型(1)
- Hive-数据类型
📜 Hive中的存储桶
📅 最后修改于: 2020-12-03 03:50:35 🧑 作者: Mango
蜂巢中的桶
Hive中的存储桶是一种数据组织技术。它类似于Hive中的分区功能,具有将功能强大的功能将大型数据集划分为更易于管理的部分(称为存储桶)的功能。因此,当分区的实现变得困难时,我们可以在Hive中使用存储桶。但是,我们也可以在存储分区中进一步划分分区。
蜂巢中的桶装工作

- 存储的概念基于哈希技术。
- 在此,计算当前列值和所需桶数的模块(假设F(x)%3)。
- 现在,基于结果值,数据将存储到相应的存储桶中。
在Hive中进行存储桶的示例
- 首先,选择我们要在其中创建表的数据库。
hive> use showbucket;

- 创建一个虚拟表来存储数据。
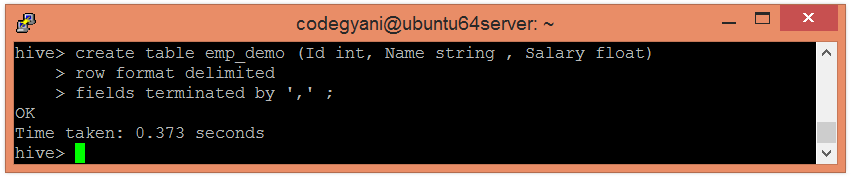
hive> create table emp_demo (Id int, Name string , Salary float)
row format delimited
fields terminated by ',' ;
- 现在,将数据加载到表中。
hive> load data local inpath '/home/codegyani/hive/emp_details' into table emp_demo;

- 使用以下命令启用存储桶:-
hive> set hive.enforce.bucketing = true;
- 使用以下命令创建存储表:-
hive> create table emp_bucket(Id int, Name string , Salary float)
clustered by (Id) into 3 buckets
row format delimited
fields terminated by ',' ;

- 现在,将虚拟表的数据插入存储桶的表中。
hive> insert overwrite table emp_bucket select * from emp_demo;



- 在这里,我们可以看到数据分为三个存储桶。

- 让我们检索存储桶0的数据。

根据哈希函数:
6%3 = 0
3%3 = 0
因此,这些列存储在存储区0中。
- 让我们检索存储桶1的数据。

根据哈希函数:
7%3 = 1
4%3 = 1
1%3 = 1
因此,这些列存储在存储区1中。
- 让我们检索存储桶2的数据。

根据哈希函数:
8%3 = 2
5%3 = 2
2%3 = 2
因此,这些列存储在存储区2中。