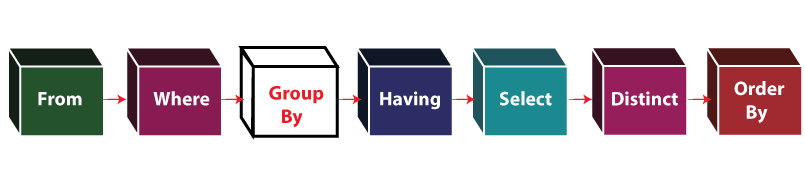
- PostgreSQL Group BY子句(1)
- PostgreSQL – GROUP BY 子句
- PostgreSQL-GROUP BY
- PostgreSQL-GROUP BY(1)
- T-SQL-GROUP BY子句(1)
- T-SQL-GROUP BY子句
- MySQL GROUP BY子句
- Oracle GROUP BY子句
- Oracle GROUP BY子句(1)
- SQLite-GROUP BY子句
- SQLite GROUP BY子句-2(1)
- SQLite GROUP BY子句-2
- SQLite-GROUP BY子句(1)
- 选择列表不在 group by 子句中 - SQL (1)
- mysql 表达式不在 group by 子句中 (1)
- 选择列表不在 group by 子句中 - SQL 代码示例
- SQL中order by和group by子句的区别
- SQL中order by和group by子句的区别(1)
- SQL中order by和group by子句的区别(1)
- SQL中order by和group by子句的区别
- SQL中order by和group by子句的区别
- Have 子句和 Group by 子句的区别(1)
- Have 子句和 Group by 子句的区别(1)
- Have 子句和 Group by 子句的区别
- Have 子句和 Group by 子句的区别
- GROUP BY (1)
- GROUP BY 子句;这是不兼容的 - SQL (1)
- 错误代码:1055.ORDER BY 子句的表达式#1 不在 GROUP BY 子句中,并且包含在功能上不依赖于 GROUP BY 子句中的列的非聚合列 \\;这与 sql_mode=only_full_group_by 不兼容 - SQL (1)
- 错误代码:1055.ORDER BY 子句的表达式#1 不在 GROUP BY 子句中,并且包含在功能上不依赖于 GROUP BY 子句中的列的非聚合列 \\;这与 sql_mode=only_full_group_by 不兼容 - SQL 代码示例
📅 最后修改于: 2020-11-30 08:44:48 🧑 作者: Mango
PostgreSQL分组依据
在本节中,我们将了解PostgreSQL中GROUP BY子句的工作方式。我们还看到了GROUP BY子句如何与SUM()函数,COUNT(),JOIN子句,多列以及没有聚合函数一起使用的示例。
PostgreSQL GROUP BY条件与SELECT命令一起使用,它也可以用于减少结果的冗余性。
PostgreSQL GROUP BY子句
最重要的是,此子句用于将行分成几组,其中GROUP BY条件收集多个记录中的数据,并按一列或多列设置结果。
每个组都可以应用聚合函数,例如COUNT()函数用于获取组中的项目数,而SUM()函数用于分析项目的总和。
PostgreSQL group by子句的语法
GROUP BY子句的基本语法如下:
SELECT column-list
FROM table_name
WHERE [conditions ]
GROUP BY column1, column2....columnN
ORDER BY column1, column2....columnN
以下是以上语法中使用的参数:
Columns-list:用于选择需要分组的列,可以是column1,column2,… columnN 。
我们还可以在GROUP BY子句中使用SELECT命令的附加条件。
在PostgreSQL中,GROUP BY子句的工作如下:
PostgreSQL GROUP BY子句的示例
为了更好地理解,我们将使用一个Employee表,该表是在PostgreSQL教程的前面部分中创建的。

- 不使用聚合函数的GROUP BY子句的示例
在这里,我们将使用GROUP BY子句而不应用聚合函数。因此,我们使用以下命令,该命令从employee表中获取记录,并通过emp_id将结果分组。
SELECT emp_id
FROM employee
GROUP BY emp_id;
输出量
执行上述命令后,我们将得到以下结果:
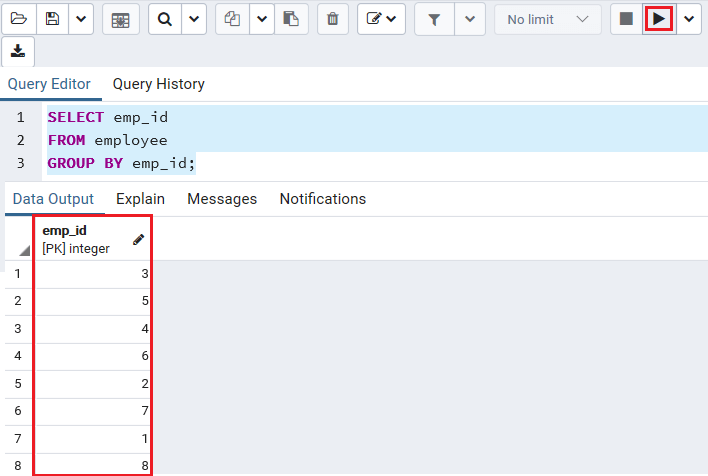
在上面的示例中, GROUP BY子句的工作方式与DISTINCT条件相似,这有助于我们从结果集中删除匹配的行。
- 使用PostgreSQL GROUP BY Clasue的SUM()函数示例
在这里,我们将聚集函数与GROUP BY条件一起使用。
例如,如果我们要获取employee表中的first_name为John的薪水总和。因此,我们在where子句中使用GROUP BY子句来获取John的薪水。
下面的命令用于在GROUP BY条件的帮助下获取John的薪水总和:
SELECT first_name, SUM(SALARY)
FROM employee
where first_name = 'John'
GROUP BY first_name ;
输出量
执行上述命令后,我们将得到以下结果:
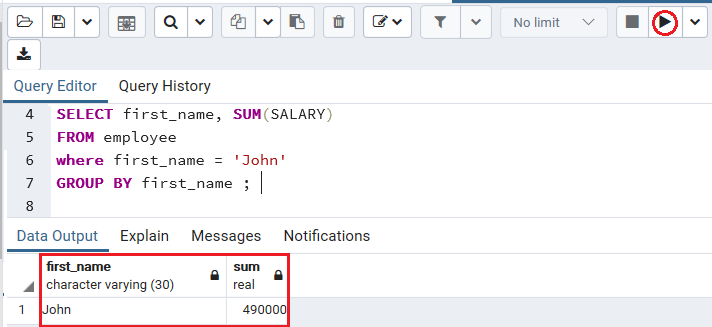
注意:在employee表中,first_name的冗余为john。使用此命令后,由于我们使用where子句,并合并了约翰薪水的总和,因此两个约翰的薪水被合并。
在下面的命令中,我们使用ORDER BY条件通过GROUP BY子句按升序显示所有员工的薪水:
SELECT first_name, SUM(SALARY)
FROM employee
GROUP BY first_name
ORDER BY SUM (salary) asc;
输出量
执行完以上命令后,我们将得到以下输出:

- 使用PostgreSQL GROUP BY子句的JOIN条件示例
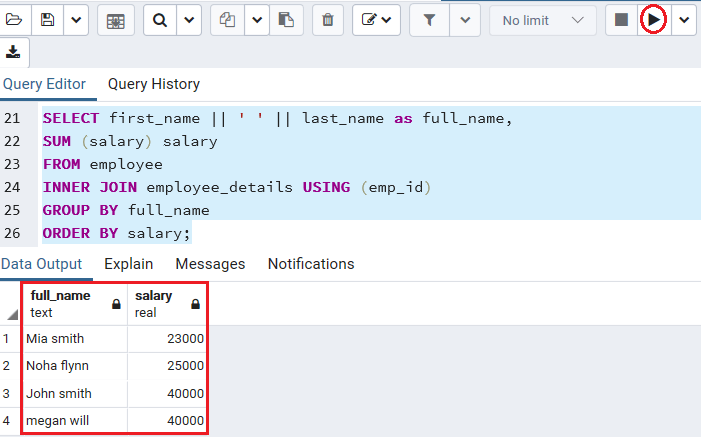
在下面的示例中,我们将GROUP BY子句与INNER JOIN子句一起使用,以获取每个雇员的薪水之和。
在以下命令中,我们将employee表与employee_details表连接在一起,并通过名称Concat(合并)employee。
SELECT first_name || ' ' || last_name as full_name,
SUM (salary) salary
FROM employee
INNER JOIN employee_details USING (emp_id)
GROUP BY full_name
ORDER BY salary;
输出量
执行完上述命令后,我们将得到以下结果:
- 使用PostgreSQL GROUP BY子句的Count()函数示例
在下面的示例中,我们使用COUNT()函数获取emp_id的数量。因此,我们选择first_name并从employee表中获取emp_id的计数。
SELECT first_name,
COUNT (emp_id)
FROM employee
GROUP BY first_name;
输出量
执行完上面的命令后,我们将得到以下结果,我们可以在first_name列中看到John的计数为2。

对于每个组,它使用COUNT()函数返回行数。 GROUP BY子句将雇员中的行分为几组,并按emp_id列中的值将它们分组。
- 使用PostgreSQL GROUP BY子句的多列示例
在这种情况下,我们将使用一列或多列并借助GROUP BY子句获取记录。
在下面的示例中,我们使用GROUP BY子句获取的多个列是emp_id和first_name ,该子句通过employee表中的行通过它们的值以及emp_id和first_name的每组分隔。