- PostgreSQL-WITH子句(1)
- PostgreSQL-WITH子句
- PostgreSQL Where子句
- PostgreSQL Where子句(1)
- PostgreSQL – WHERE 子句
- PostgreSQL – WHERE 子句(1)
- PostgreSQL-WHERE子句(1)
- PostgreSQL-WHERE子句
- Python PostgreSQL-Where子句(1)
- Python PostgreSQL – Where 子句
- Python PostgreSQL-Where子句(1)
- Python PostgreSQL-Where子句
- Python PostgreSQL-Where子句
- Python PostgreSQL – Where 子句(1)
- PostgreSQL – FETCH 子句
- PostgreSQL Fetch子句
- PostgreSQL – FETCH 子句(1)
- PostgreSQL-LIKE子句
- PostgreSQL – LIMIT 子句(1)
- PostgreSQL LIMIT子句
- PostgreSQL LIMIT子句(1)
- PostgreSQL-LIMIT子句(1)
- PostgreSQL – LIMIT 子句
- PostgreSQL-LIMIT子句
- PostgreSQL – HAVING 子句
- PostgreSQL-HAVING子句(1)
- PostgreSQL-HAVING子句
- PostgreSQL – HAVING 子句(1)
- PostgreSQL – GROUP BY 子句(1)
📅 最后修改于: 2020-11-30 08:45:47 🧑 作者: Mango
PostgreSQL Have子句
在本节中,我们将了解PostgreSQL中HAVING子句的工作方式。
Haveing子句用于指定组或集合的搜索条件。并且它经常与GROUP BY子句一起使用,以根据详细条件过滤组或聚合。
PostgreSQL Have子句的语法
PostgreSQL HAVING子句的基本语法如下:
SELECT column1, aggregate_function (column2)
FROM table1, table2
WHERE [ conditions ]
GROUP BY column1, column2
HAVING [ conditions ]
ORDER BY column1, column2
在以上语法中,我们使用了以下参数:
| Parameters | Description |
|---|---|
| GROUP BY clause | It is used to return rows grouped by column1. |
| Having clause | It is used to define a condition which filter the sets. |
注意:在PostgreSQL中,我们可以添加SELECT命令的其他子句,例如LIMIT,JOIN和FETCH。随后,HAVING子句在SELECT子句之前起作用。
在PostgreSQL中,HAVING子句的格式如下:

我们不能在HAVING子句中使用列别名,因为在评估HAVING子句时,无法访问SELECT子句中定义的列别名。
Have和where子句之间的区别
让我们看看HAVING子句和WHERE子句之间的区别:
| Having clause | Where clause |
|---|---|
| The HAVING clause allows us to filter groups of rows as per the defined condition. | The WHERE clause permits us to filter rows according to a defined condition. |
| The HAVING clause is useful to groups of rows. | The WHERE clause is applied to rows only. |
PostgreSQL HAVING子句的示例
让我们看一些在PostgreSQL中具有having子句的例子。因此,在这里我们将使用在PostgreSQL教程的较早主题中创建的employee表。

使用PostgreSQL HAVING子句的SUM()函数示例
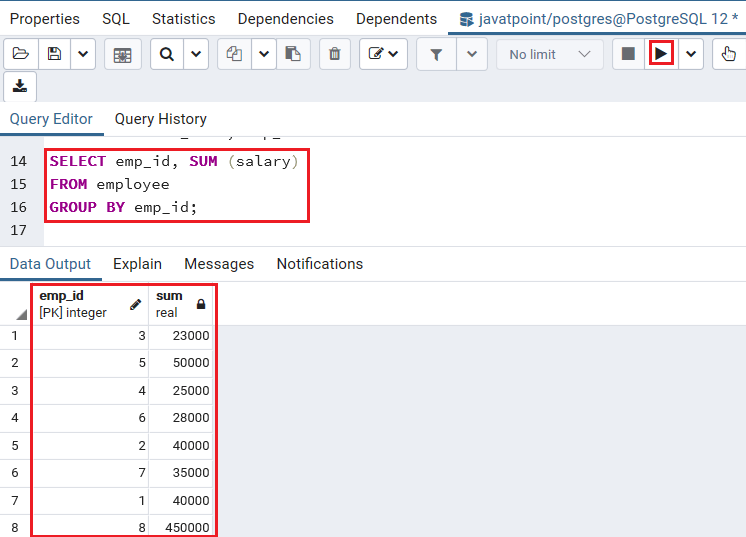
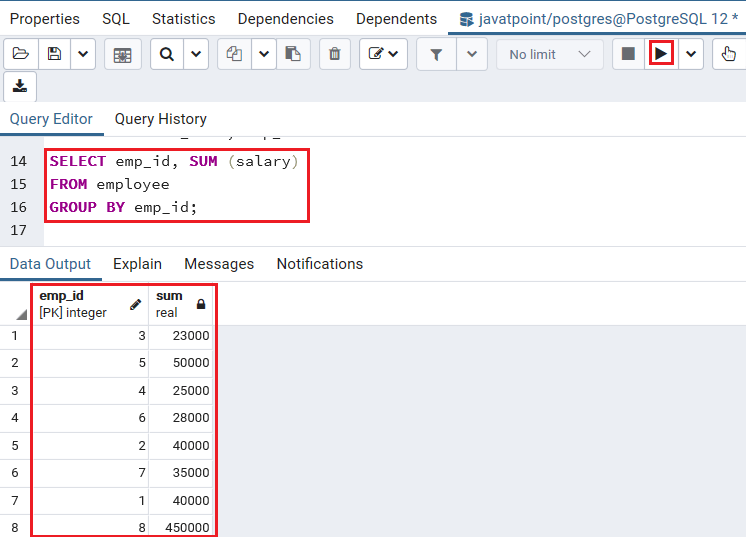
在下面的示例中,我们将GROUP BY子句与SUM()函数,以标识每个员工的总薪水:
SELECT emp_id, SUM (salary)
FROM employee
GROUP BY emp_id;
输出量
在下面的示例中,我们将GROUP BY子句与SUM()函数,以标识每个员工的总薪水:
SELECT emp_id, SUM (salary)
FROM employee
GROUP BY emp_id;
输出量
执行完上述命令后,我们将获得以下输出,该输出显示每个雇员基于emp_id的薪金总和。
之后,我们将在上面的命令中添加HAVING子句,以选择薪水超过25000的那些雇员:
SELECT emp_id, first_name, SUM (salary)
FROM employee
GROUP BY first_name, emp_id
HAVING SUM (salary) > 25000
order by first_name DESC;
输出量
执行上述命令后,我们将得到以下结果,其中显示薪水超过25000的那些雇员:
使用PostgreSQL HAVING子句的COUNT()函数示例
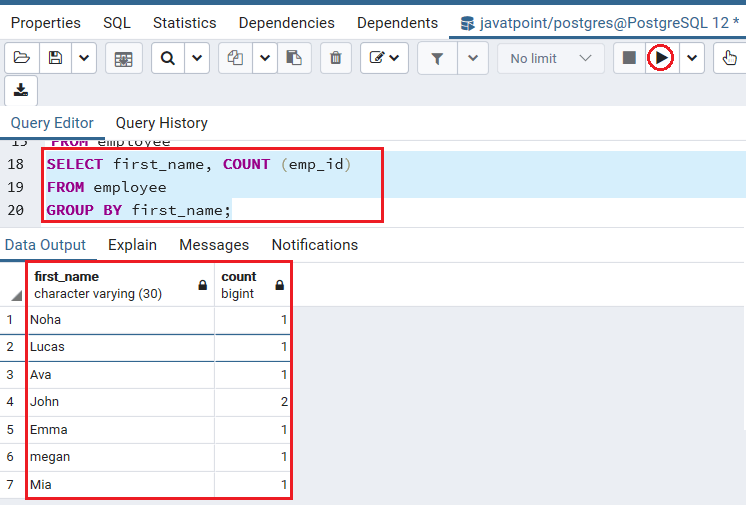
以下命令用于在GROUP BY子句的帮助下确定员工人数:
SELECT first_name, COUNT (emp_id)
FROM employee
GROUP BY first_name;
输出量
一旦执行了以上命令,我们将获得以下输出;显示员工人数:
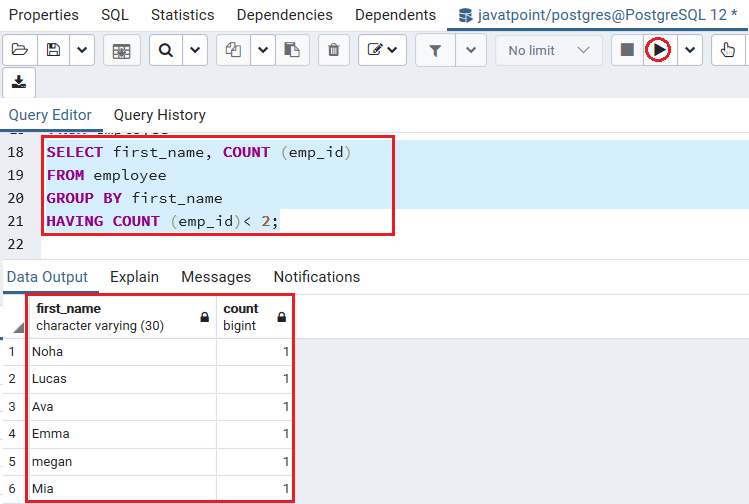
之后,我们将在上面的命令中添加HAVING子句,以选择雇员少于两个的first_name:
SELECT first_name, COUNT (emp_id)
FROM employee
GROUP BY first_name
HAVING COUNT (emp_id)< 2;
输出量
执行完上述命令后,我们将得到以下结果: