- PostgreSQL-锁(1)
- postgreSQL (1)
- PostgreSQL-锁
- 不同且不为空的 c# (1)
- PostgreSQL数组(1)
- PostgreSQL数组
- PostgreSQL-函数
- PostgreSQL函数(1)
- PostgreSQL – 右函数
- PostgreSQL-函数(1)
- PostgreSQL – 右函数(1)
- PostgreSQL函数
- postgreSQL 有 - SQL (1)
- postgresql 不在 - SQL (1)
- PostgreSQL – 删除(1)
- PostgreSQL删除(1)
- PostgreSQL删除
- PostgreSQL – 删除表(1)
- PostgreSQL删除表
- PostgreSQL – 删除列(1)
- 删除域 postgresql (1)
- PostgreSQL – 删除
- PostgreSQL删除表(1)
- PostgreSQL – 删除列
- PostgreSQL – 删除表
- PostgreSQL – 创建表
- PostgreSQL – 创建表(1)
- PostgreSQL创建表
- PostgreSQL-创建表(1)
📅 最后修改于: 2020-11-30 08:46:50 🧑 作者: Mango
PostgreSQL DISTINCT
在本节中,我们将了解PostgreSQL DISTINCT子句的工作原理,该子句用于删除表中匹配的行或数据,并仅获取唯一记录。
注意:DISTINCT子句仅与SELECT命令一起使用。 DISTINCT子句对SELECT命令的选择列表中的几列有用,并且对于每个重复组都保留一行。
PostgreSQL选择独特子句的语法
DISTINCT子句的基本语法如下:
语法1
在下面的语法中, column1中的值用于评估重复项。
如果我们描述各个列,则DISTINCT子句将根据这些列的值的分组来分析匹配的行或数据。
Select Distinct column1
FROM table_name;
语法2
如果column1和column2列的值都相似,那么要获取重复的值,我们可以使用以下语法:
SELECT DISTINCT column1, column2
FROM table_name;
语法3
PostgreSQL还提供了DISTINCT ON表达式来维护每组重复项的第一行。因此,对于这些情况,可以使用以下命令:
SELECT DISTINCT ON (column1) column_alias, column2
FROM table_name
ORDER BY column1, column2 ;
如果我们连续使用DISTINCT ON(表达式)执行ORDER BY子句以使结果可预期,则这是一项出色的练习。
注意:ORDER BY子句中最左边的表达式必须与DISTINCT ON表达式匹配。
PostgreSQL SELECT DISTINCT的示例
为了了解DISTINCT子句在PostgreSQL中的工作原理,我们将看到一些示例。
为此,我们将创建一个名为demo_dist的新表,并将某些值插入到特定表中。在本节中,我们仅在psql或pgAdmin中执行命令。
要查看PostgreSQL的Pgadmin4中的Select Distinct命令的示例,我们需要执行以下步骤:
步骤1
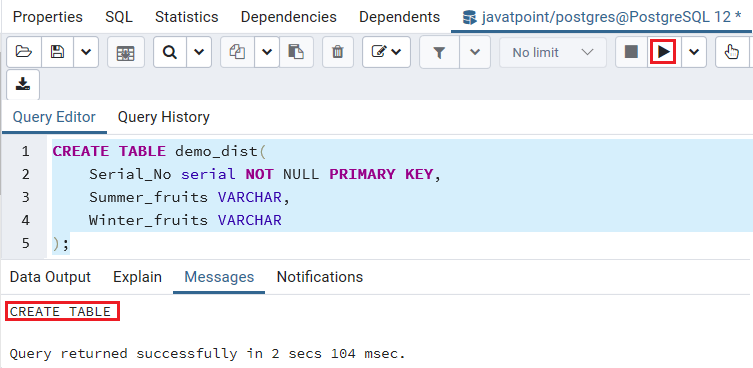
我们将在CREATE TABLE命令的帮助下创建一个表,如下面的命令所示,我们已经创建了Demo_dist表,该表由三列Serial_NO,Summer_fruits和Winter_fruits组成。
CREATE TABLE demo_dist(
Serial_No serial NOT NULL PRIMARY KEY,
Summer_fruits VARCHAR,
Winter_fruits VARCHAR
);
输出量
执行完上述命令后,我们将获得以下消息窗口; Demo_dist表已成功创建。
第2步
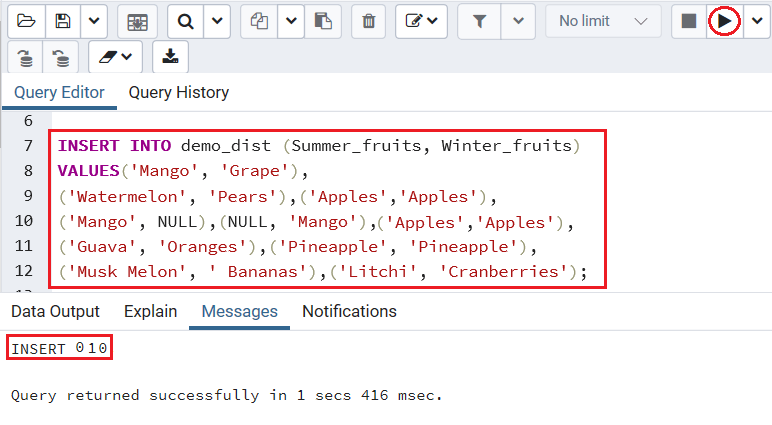
创建Demo_dist表之后,我们将在下面的INSERT命令的帮助下向其中插入一些值:
INSERT INTO demo_dist (Summer_fruits, Winter_fruits)
VALUES('Mango', 'Grape'),
('Watermelon', 'Pears'),('Apples','Apples'),
('Mango', NULL),(NULL, 'Mango'), ('Apples','Apples'),
('Guava', 'Oranges'),('Pineapple', 'Pineapple'),
('Musk Melon', ' Bananas'),('Litchi', 'Cranberries');
输出量
执行完上述命令后,我们将获得以下消息窗口;值已成功插入到Demo_dist表中。
第三步
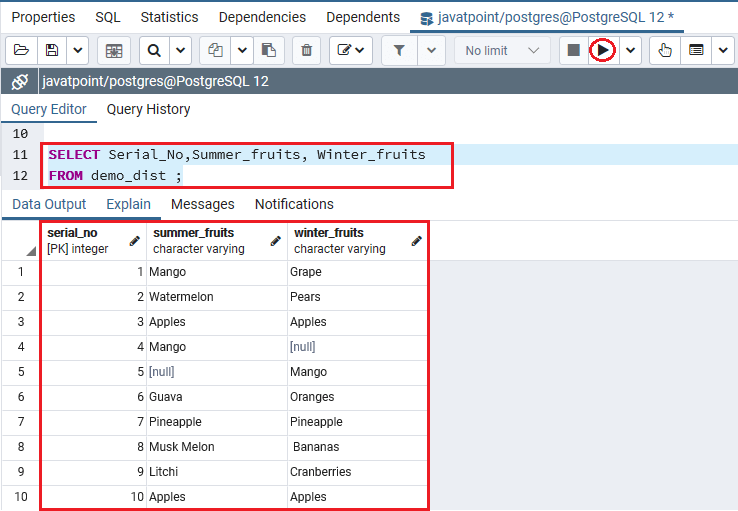
之后,我们将在下面的SELECT命令的帮助下从Demo_dist表中选择数据:
SELECT Serial_No,Summer_fruits, Winter_fruits
FROM demo_dist ;
输出量
一旦执行了以上命令,我们将获得以下输出:
PostgreSQL DISTINCT示例一栏
在下面的示例中,我们将从Demo_dist表的Summer_fruits列中选择唯一记录,并执行ORDER BY子句以按顺序获得结果。
SELECT DISTINCT Summer_fruits
FROM demo_dist
ORDER BY Summer_fruits ;
输出量
执行完上述命令后,我们将获得以下输出,其中以字母顺序获取summer _fruits列的列表。

使用PostgreSQL DISTINCT的多列示例
在下面的示例中,我们将在一个或多个列上使用DISTINCT子句,
要使用distinctary子句获取各个列的值,我们将使用Summer_fruits和Winter_fruits列,如以下命令所示:
SELECT DISTINCT Summer_fruits, Winter_fruits
FROM demo_dist
ORDER BY Summer_fruits, Winter_fruits;
输出量
实施上述命令后,我们将获得以下输出,其中以字母顺序获取summer _fruits列表和Winter_fruits列。
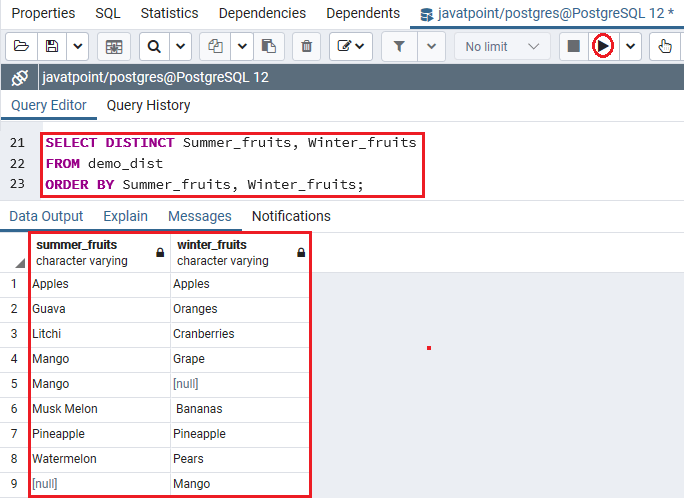
在上面的命令中,我们在SELECT DISTINCT子句中描述了Summer_fruits和Winter_fruits列;这就是为什么PostgreSQL将Summer_fruits和Winter_fruits列中的值都加入来分析行的唯一性的原因。
一旦执行了以上命令,它就会从Demo_dist表中返回Summer_fruits和Winter_fruits的唯一组合。
注意:Demo_dist表在Summer_fruits和Winter_fruits列中都有两行,其值均为Apples。当我们对两列使用DISTINCT时,从输出中删除了一行,因为它是重复的。
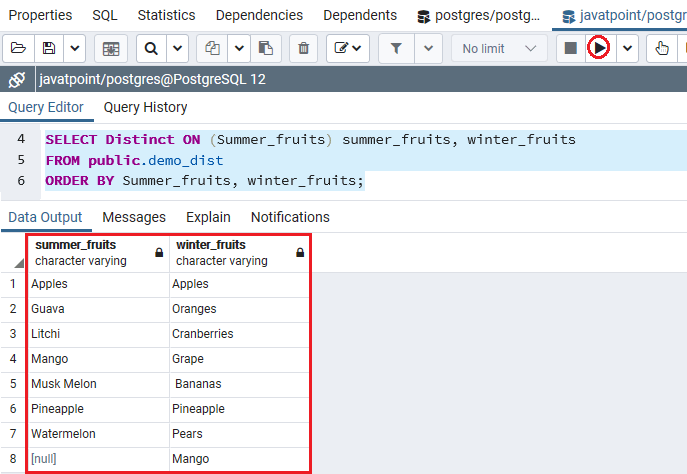
示例PostgreSQL DISTINCT ON
在下面的示例中,我们将按Summer_fruits和Winter_fruits对结果进行排序,并且对于每组重复值,它会将第一行保留在返回的输出中。
SELECT Distinct ON (Summer_fruits) summer_fruits, winter_fruits
FROM public.demo_dist
ORDER BY Summer_fruits, winter_fruits;
输出量
执行完上述命令后,我们将获得以下输出,该输出显示结果,其中Summer_fruits和winter_fruits这两个列均未显示相似的值。