Python|使用 Pandas .iloc[] 提取行
Python是一种用于进行数据分析的出色语言,主要是因为以数据为中心的Python包的奇妙生态系统。 Pandas就是其中之一,它使导入和分析数据变得更加容易。
Pandas 提供了一种从数据框中检索行的独特方法。 Dataframe.iloc[]方法用于数据帧的索引标签不是数字系列 0、1、2、3….n 或用户不知道索引标签的情况。可以使用在数据框中不可见的虚构索引位置来提取行。
Syntax: pandas.DataFrame.iloc[]
Parameters:
Index Position: Index position of rows in integer or list of integer.
Return type: Data frame or Series depending on parameters
要下载代码中使用的 CSV,请单击此处。
示例 #1:提取单行并与 .loc[] 进行比较
在此示例中,相同的索引号行通过 .iloc[] 和 .loc[] 方法提取并进行比较。由于默认情况下索引列是数字,因此索引标签也将是整数。
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv")
# retrieving rows by loc method
row1 = data.loc[3]
# retrieving rows by iloc method
row2 = data.iloc[3]
# checking if values are equal
row1 == row2
输出:
如输出图像所示,两种方法返回的结果是相同的。 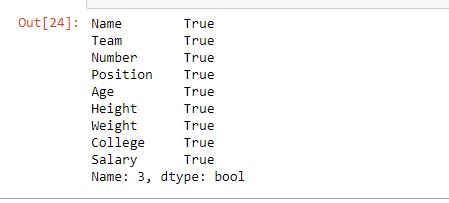
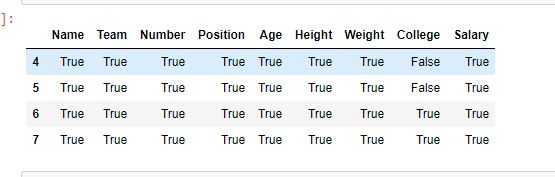
示例 #2:使用索引提取多行
在此示例中,首先通过传递一个列表来提取多行,然后通过传递整数来提取该范围之间的行。之后,比较两个值。
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv")
# retrieving rows by loc method
row1 = data.iloc[[4, 5, 6, 7]]
# retrieving rows by loc method
row2 = data.iloc[4:8]
# comparing values
row1 == row2
输出:
如输出图像所示,两种方法返回的结果是相同的。除了大学列中的值之外,所有值都是 True,因为这些值是 NaN 值。