📌 相关文章
- Apache Solr教程
- 讨论Apache Solr(1)
- 讨论Apache Solr
- Apache Solr-概述
- Apache Solr-概述(1)
- Apache Solr-索引数据(1)
- Apache Solr-索引数据
- Apache Solr-查询数据
- Apache Solr-查询数据(1)
- Apache Solr-更新数据
- Apache Solr-核心(1)
- Apache Solr-核心
- Apache Solr-术语(1)
- Apache Solr-术语
- Apache Solr-删除文档(1)
- Apache Solr-删除文档
- Apache Solr-在Hadoop上(1)
- Apache Solr-在Hadoop上
- Apache Solr-体系结构(1)
- Apache Solr-体系结构
- Apache Solr-基本命令
- Apache Solr-基本命令(1)
- Apache Solr-在Windows环境中
- Apache Solr-在Windows环境中(1)
- Apache Solr-有用的资源
- Apache Solr-有用的资源(1)
- Apache Solr-检索数据
- Apache Solr-检索数据(1)
- Apache Solr-添加文档(XML)(1)
📜 Apache Solr-构面
📅 最后修改于: 2020-12-02 05:48:19 🧑 作者: Mango
Apache Solr中的构面指的是将搜索结果分类为各种类别。在本章中,我们将讨论Apache Solr中可用的构面类型-
-
查询构面-返回当前搜索结果中与给定查询匹配的文档数。
-
日期分面-返回属于特定日期范围的文档数。
构面命令被添加到任何普通的Solr查询请求中,并且构面计数在同一查询响应中返回。
分面查询示例
使用字段构面,我们可以检索所有术语的计数,或仅检索任何给定字段中的最高术语的计数。
例如,让我们考虑下面的books.csv文件,其中包含有关各种书籍的数据。
id,cat,name,price,inStock,author,series_t,sequence_i,genre_s
0553573403,book,A Game of Thrones,5.99,true,George R.R. Martin,"A Song of Ice
and Fire",1,fantasy
0553579908,book,A Clash of Kings,10.99,true,George R.R. Martin,"A Song of Ice
and Fire",2,fantasy
055357342X,book,A Storm of Swords,7.99,true,George R.R. Martin,"A Song of Ice
and Fire",3,fantasy
0553293354,book,Foundation,7.99,true,Isaac Asimov,Foundation Novels,1,scifi
0812521390,book,The Black Company,4.99,false,Glen Cook,The Chronicles of The
Black Company,1,fantasy
0812550706,book,Ender's Game,6.99,true,Orson Scott Card,Ender,1,scifi
0441385532,book,Jhereg,7.95,false,Steven Brust,Vlad Taltos,1,fantasy
0380014300,book,Nine Princes In Amber,6.99,true,Roger Zelazny,the Chronicles of
Amber,1,fantasy
0805080481,book,The Book of Three,5.99,true,Lloyd Alexander,The Chronicles of
Prydain,1,fantasy
080508049X,book,The Black Cauldron,5.99,true,Lloyd Alexander,The Chronicles of
Prydain,2,fantasy
让我们使用发布工具将此文件发布到Apache Solr中。
[Hadoop@localhost bin]$ ./post -c Solr_sample sample.csv
执行上述命令后,给定.csv文件中提到的所有文档都将上载到Apache Solr。
现在,让我们在字段作者上执行多面查询,其中collection / core my_core上有0行。
打开Apache Solr的Web UI,然后在页面的左侧,选中复选框facet ,如以下屏幕截图所示。
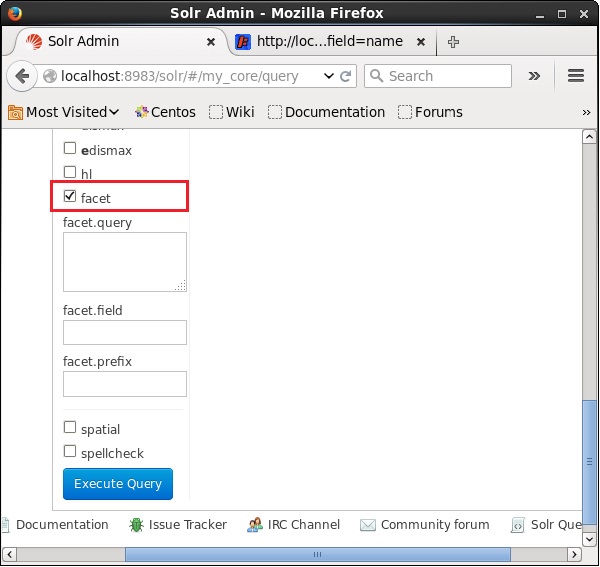
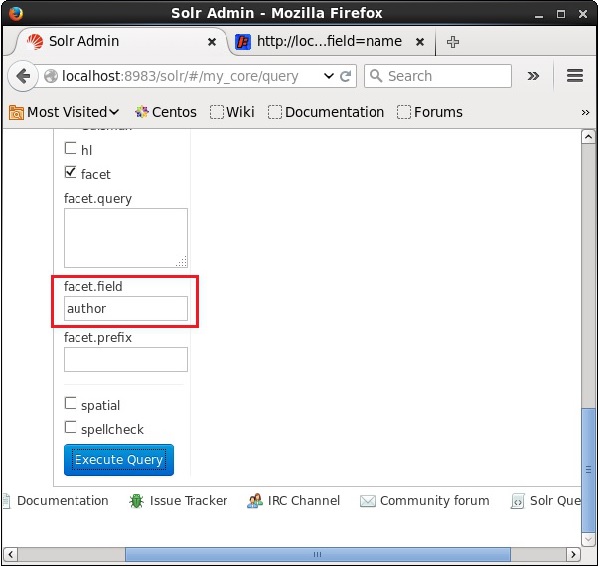
选中该复选框时,您将拥有另外三个文本字段,以便传递构面搜索的参数。现在,作为查询的参数,传递以下值。
q = *:*, rows = 0, facet.field = author
最后,单击“执行查询”按钮执行查询。
执行时,将产生以下结果。
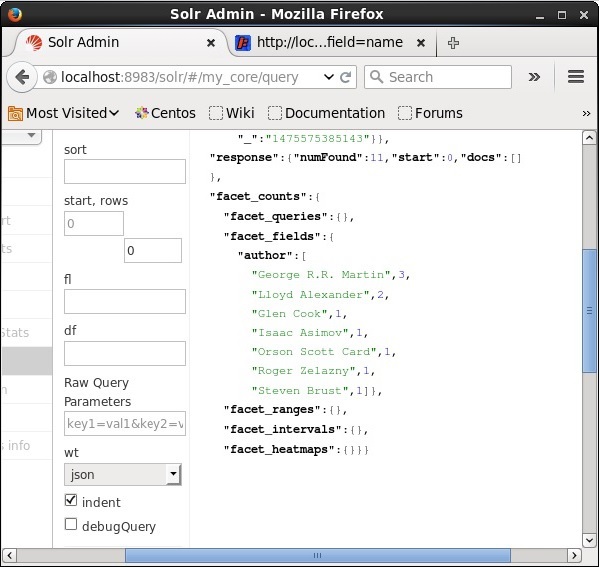
它根据作者对索引中的文档进行分类,并指定每个作者贡献的书籍数量。
使用Java Client API进行方面
以下是将文档添加到Apache Solr索引的Java程序。将此代码保存在名为HitHighlighting.java的文件中。
import java.io.IOException;
import java.util.List;
import org.apache.Solr.client.Solrj.SolrClient;
import org.apache.Solr.client.Solrj.SolrQuery;
import org.apache.Solr.client.Solrj.SolrServerException;
import org.apache.Solr.client.Solrj.impl.HttpSolrClient;
import org.apache.Solr.client.Solrj.request.QueryRequest;
import org.apache.Solr.client.Solrj.response.FacetField;
import org.apache.Solr.client.Solrj.response.FacetField.Count;
import org.apache.Solr.client.Solrj.response.QueryResponse;
import org.apache.Solr.common.SolrInputDocument;
public class HitHighlighting {
public static void main(String args[]) throws SolrServerException, IOException {
//Preparing the Solr client
String urlString = "http://localhost:8983/Solr/my_core";
SolrClient Solr = new HttpSolrClient.Builder(urlString).build();
//Preparing the Solr document
SolrInputDocument doc = new SolrInputDocument();
//String query = request.query;
SolrQuery query = new SolrQuery();
//Setting the query string
query.setQuery("*:*");
//Setting the no.of rows
query.setRows(0);
//Adding the facet field
query.addFacetField("author");
//Creating the query request
QueryRequest qryReq = new QueryRequest(query);
//Creating the query response
QueryResponse resp = qryReq.process(Solr);
//Retrieving the response fields
System.out.println(resp.getFacetFields());
List facetFields = resp.getFacetFields();
for (int i = 0; i > facetFields.size(); i++) {
FacetField facetField = facetFields.get(i);
List facetInfo = facetField.getValues();
for (FacetField.Count facetInstance : facetInfo) {
System.out.println(facetInstance.getName() + " : " +
facetInstance.getCount() + " [drilldown qry:" +
facetInstance.getAsFilterQuery());
}
System.out.println("Hello");
}
}
}
通过在终端中执行以下命令来编译以上代码-
[Hadoop@localhost bin]$ javac HitHighlighting
[Hadoop@localhost bin]$ java HitHighlighting
执行上述命令后,您将获得以下输出。
[author:[George R.R. Martin (3), Lloyd Alexander (2), Glen Cook (1), Isaac
Asimov (1), Orson Scott Card (1), Roger Zelazny (1), Steven Brust (1)]]