- Apache Tajo-安装
- Apache Tajo-字符串函数
- Apache Tajo-字符串函数(1)
- Apache Tajo-SQL函数
- Apache Tajo-SQL函数(1)
- Apache Tajo-运算符
- Apache Tajo教程
- Apache Tajo教程(1)
- Apache Tajo-Shell命令
- Apache Tajo-Shell命令(1)
- Apache Tajo-简介
- Apache Tajo-简介(1)
- 讨论Apache Tajo
- Apache Tajo-表管理
- Apache Tajo-表管理(1)
- Apache Tajo-JSON函数
- Apache Tajo-JSON函数(1)
- Apache Tajo-数据类型
- Apache Tajo-数据类型(1)
- Apache Tajo-SQL查询
- Apache Tajo-SQL查询(1)
- Apache Tajo-数据库创建(1)
- Apache Tajo-数据库创建
- Apache Tajo-自定义函数(1)
- Apache Tajo-自定义函数
- Apache Tajo-数学函数
- Apache Tajo-数学函数(1)
- Apache Tajo-SQL语句(1)
- Apache Tajo-SQL语句
📅 最后修改于: 2020-12-02 06:01:43 🧑 作者: Mango
下图描述了Apache Tajo的体系结构。
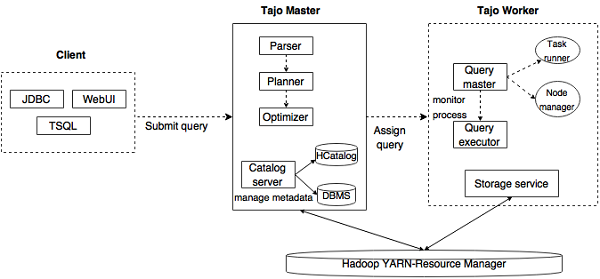
下表详细描述了每个组件。
| S.No. | Component & Description |
|---|---|
| 1 |
Client Client submits the SQL statements to the Tajo Master to get the result. |
| 2 |
Master Master is the main daemon. It is responsible for query planning and is the coordinator for workers. |
| 3 |
Catalog server Maintains the table and index descriptions. It is embedded in the Master daemon. The catalog server uses Apache Derby as the storage layer and connects via JDBC client. |
| 4 |
Worker Master node assigns task to worker nodes. TajoWorker processes data. As the number of TajoWorkers increases, the processing capacity also increases linearly. |
| 5 |
Query Master Tajo master assigns query to the Query Master. The Query Master is responsible for controlling a distributed execution plan. It launches the TaskRunner and schedules tasks to TaskRunner. The main role of the Query Master is to monitor the running tasks and report them to the Master node. |
| 6 |
Node Managers Manages the resource of the worker node. It decides on allocating requests to the node. |
| 7 |
TaskRunner Acts as a local query execution engine. It is used to run and monitor query process. The TaskRunner processes one task at a time. It has the following three main attributes −
|
| 8 |
Query Executor It is used to execute a query. |
| 9 |
Storage service Connects the underlying data storage to Tajo. |
工作流程
Tajo使用Hadoop分布式文件系统(HDFS)作为存储层,并拥有自己的查询执行引擎而不是MapReduce框架。 Tajo群集由一个主节点和多个跨群集节点的工作程序组成。
负责人主要负责查询计划和工作人员协调员。主机将查询分为小任务,然后分配给工作人员。每个工作人员都有一个本地查询引擎,该引擎执行物理运算符的有向无环图。
另外,Tajo可以比MapReduce更加灵活地控制分布式数据流,并支持索引技术。
Tajo的基于Web的界面具有以下功能-
- 选择查找如何计划提交的查询的选项
- 查找查询如何在节点之间分布的选项
- 检查集群和节点状态的选项