使用Python从任何网站刮取表格
抓取是每个人从任何网站获取数据的一项非常重要的技能。如果我们使用标准的 Beautiful Soup 解析器,那么抓取和解析表格可能是非常乏味的工作。因此,在这里我们将描述一个库,借助它可以轻松地从任何网站上抓取任何表格。使用这种方法,您甚至不必检查网站的元素,您只需提供网站的 URL。就是这样,工作将在几秒钟内完成。
安装
你可以使用 pip 来安装这个库:
pip install html-table-parser-python3入门
第 1 步:导入任务所需的必要库
# Library for opening url and creating
# requests
import urllib.request
# pretty-print python data structures
from pprint import pprint
# for parsing all the tables present
# on the website
from html_table_parser.parser import HTMLTableParser
# for converting the parsed data in a
# pandas dataframe
import pandas as pd第 2 步:定义获取网站内容的函数
# Opens a website and read its
# binary contents (HTTP Response Body)
def url_get_contents(url):
# Opens a website and read its
# binary contents (HTTP Response Body)
#making request to the website
req = urllib.request.Request(url=url)
f = urllib.request.urlopen(req)
#reading contents of the website
return f.read()现在,我们的函数已经准备好了,所以我们必须指定我们需要从中解析表格的网站的 url。
注意:这里我们以moneycontrol.com网站为例,因为它有很多表格,可以让你更好地理解。你可以在这里查看网站。
第 3 步:解析表
# defining the html contents of a URL.
xhtml = url_get_contents('Link').decode('utf-8')
# Defining the HTMLTableParser object
p = HTMLTableParser()
# feeding the html contents in the
# HTMLTableParser object
p.feed(xhtml)
# Now finally obtaining the data of
# the table required
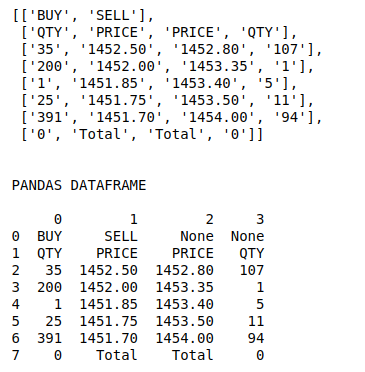
pprint(p.tables[1])表的每一行都存储在一个数组中。这可以很容易地转换为 pandas 数据框,并可用于执行任何分析。
完整代码:
Python3
# Library for opening url and creating
# requests
import urllib.request
# pretty-print python data structures
from pprint import pprint
# for parsing all the tables present
# on the website
from html_table_parser.parser import HTMLTableParser
# for converting the parsed data in a
# pandas dataframe
import pandas as pd
# Opens a website and read its
# binary contents (HTTP Response Body)
def url_get_contents(url):
# Opens a website and read its
# binary contents (HTTP Response Body)
#making request to the website
req = urllib.request.Request(url=url)
f = urllib.request.urlopen(req)
#reading contents of the website
return f.read()
# defining the html contents of a URL.
xhtml = url_get_contents('https://www.moneycontrol.com/india\
/stockpricequote/refineries/relianceindustries/RI').decode('utf-8')
# Defining the HTMLTableParser object
p = HTMLTableParser()
# feeding the html contents in the
# HTMLTableParser object
p.feed(xhtml)
# Now finally obtaining the data of
# the table required
pprint(p.tables[1])
# converting the parsed data to
# dataframe
print("\n\nPANDAS DATAFRAME\n")
print(pd.DataFrame(p.tables[1]))输出: