如何修复:只能比较具有相同标签的系列对象
在本文中,我们将看到如何解决它:只能比较Python中标记相同的系列对象。
错误原因
只能比较标记相同的系列对象:它是Value Error ,当我们比较 2 个不同的 DataFrame (Pandas 2-D 数据结构)时发生。 如果我们比较具有不同标签或索引的 DataFrame,则可能会引发此错误。
如何重现错误
Python3
# import necessary packages
import pandas as pd
# create 2 dataframes with different indexes
hostelCandidates1 = pd.DataFrame({'Height in CMs': [150, 170, 160],
'Weight in KGs': [70, 55, 60]},
index=[1, 2, 3])
hostelCandidates2 = pd.DataFrame({'Height in CMs': [150, 170, 160],
'Weight in KGs': [70, 55, 60]},
index=['A', 'B', 'C'])
# displaying 2 dataframes
print(hostelCandidates1)
print(hostelCandidates2)
# compare 2 dataframes
hostelCandidates1 == hostelCandidates2Python3
# import necessary packages
import pandas as pd
# create 2 dataframes with different indexes
hostelCandidates1 = pd.DataFrame({'Height in CMs':
[150, 170, 160],
'Weight in KGs':
[70, 55, 60]},
index=[1, 2, 3])
hostelCandidates2 = pd.DataFrame({'Height in CMs':
[150, 170, 160],
'Weight in KGs':
[70, 55, 60]},
index=['A', 'B', 'C'])
# displaying 2 dataframes
print(hostelCandidates1)
print(hostelCandidates2)
# compare 2 dataframes
hostelCandidates1.equals(hostelCandidates2)Python3
# import necessary packages
import pandas as pd
# create 2 dataframes with different indexes
hostelCandidates1 = pd.DataFrame({'Height in CMs':
[150, 170, 160],
'Weight in KGs':
[70, 55, 60]},
index=[1, 2, 3])
hostelCandidates2 = pd.DataFrame({'Height in CMs':
[150, 170, 160],
'Weight in KGs':
[70, 55, 60]},
index=['A', 'B', 'C'])
# displaying 2 dataframes
print(hostelCandidates1)
print(hostelCandidates2)
# compare 2 dataframes
hostelCandidates1.reset_index(drop=True).equals(
hostelCandidates2.reset_index(drop=True))Python3
# import necessary packages
import pandas as pd
# create 2 dataframes with different indexes
hostelCandidates1 = pd.DataFrame({'Height in CMs':
[150, 170, 160],
'Weight in KGs':
[70, 55, 60]},
index=[1, 2, 3])
hostelCandidates2 = pd.DataFrame({'Height in CMs':
[150, 170, 160],
'Weight in KGs':
[70, 55, 60]},
index=['A', 'B', 'C'])
# displaying 2 dataframes
print(hostelCandidates1)
print(hostelCandidates2)
# compare 2 dataframes
hostelCandidates1.reset_index(
drop=True) == hostelCandidates2.reset_index(drop=True)输出:

尽管 2 个 DataFrame 中的数据相同,但它们的索引不同。因此,为了比较 2 个 DataFrame 的数据是否相同,我们需要遵循以下方法/解决方案
方法一:考虑指标
在这里,我们将数据与 DataFrame 之间的索引标签进行比较,以指定它们是否相同。因此,在比较时,不要使用“==”,而是使用 equals 方法。
Python3
# import necessary packages
import pandas as pd
# create 2 dataframes with different indexes
hostelCandidates1 = pd.DataFrame({'Height in CMs':
[150, 170, 160],
'Weight in KGs':
[70, 55, 60]},
index=[1, 2, 3])
hostelCandidates2 = pd.DataFrame({'Height in CMs':
[150, 170, 160],
'Weight in KGs':
[70, 55, 60]},
index=['A', 'B', 'C'])
# displaying 2 dataframes
print(hostelCandidates1)
print(hostelCandidates2)
# compare 2 dataframes
hostelCandidates1.equals(hostelCandidates2)
输出:

由于数据相同,但这两个数据帧的索引标签不同,因此它返回 false 而不是错误。
方法二:不考虑索引
要删除 DataFrame 的索引,请使用reset_index 方法。通过删除索引,可以轻松完成任务,以便解释器只需检查数据,而无需考虑索引值。
Syntax: dataframeName.reset_index(drop=True)
有两种数据比较方法:
- 整个数据框
- 逐行
示例 1:整个 DataFrame 比较
Python3
# import necessary packages
import pandas as pd
# create 2 dataframes with different indexes
hostelCandidates1 = pd.DataFrame({'Height in CMs':
[150, 170, 160],
'Weight in KGs':
[70, 55, 60]},
index=[1, 2, 3])
hostelCandidates2 = pd.DataFrame({'Height in CMs':
[150, 170, 160],
'Weight in KGs':
[70, 55, 60]},
index=['A', 'B', 'C'])
# displaying 2 dataframes
print(hostelCandidates1)
print(hostelCandidates2)
# compare 2 dataframes
hostelCandidates1.reset_index(drop=True).equals(
hostelCandidates2.reset_index(drop=True))
输出:
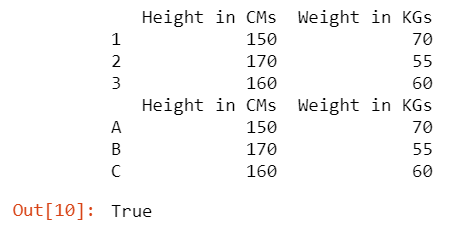
这里的数据是相同的,即使索引不同,我们通过消除索引标签来比较 DataFrame,因此它返回 true。
示例 2:逐行比较
Python3
# import necessary packages
import pandas as pd
# create 2 dataframes with different indexes
hostelCandidates1 = pd.DataFrame({'Height in CMs':
[150, 170, 160],
'Weight in KGs':
[70, 55, 60]},
index=[1, 2, 3])
hostelCandidates2 = pd.DataFrame({'Height in CMs':
[150, 170, 160],
'Weight in KGs':
[70, 55, 60]},
index=['A', 'B', 'C'])
# displaying 2 dataframes
print(hostelCandidates1)
print(hostelCandidates2)
# compare 2 dataframes
hostelCandidates1.reset_index(
drop=True) == hostelCandidates2.reset_index(drop=True)
输出:
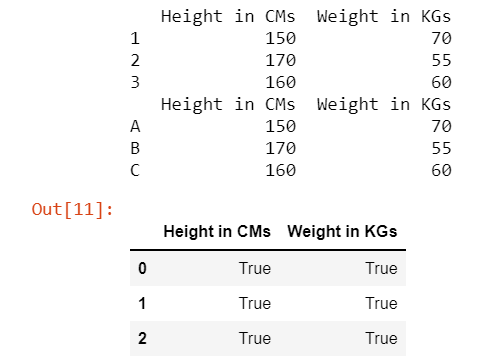
这种方法有助于我们识别 2 个 DataFrame 之间存在差异的地方,并且不比较其索引标签,因为它们的索引标签在比较时被删除。