📌 相关文章
- Caffe2-安装
- Caffe2-安装(1)
- Caffe2教程(1)
- Caffe2教程
- Caffe2-简介
- Caffe2-简介(1)
- 讨论Caffe2(1)
- 讨论Caffe2
- Caffe2-有用的资源
- Caffe2-有用的资源(1)
- Caffe2-创建自己的网络(1)
- Caffe2-创建自己的网络
- Caffe2-定义复杂网络
- Caffe2-定义复杂网络(1)
- 坞站概述
- R-概述
- C#-概述
- R-概述(1)
- F#-概述
- C++概述(1)
- C++概述
- F#-概述(1)
- Python 3-概述
- Python 3-概述(1)
- Python概述
- Python概述(1)
- JavaScript-概述
- JavaScript-概述(1)
- Java-概述(1)
📜 Caffe2-概述
📅 最后修改于: 2020-12-11 04:45:46 🧑 作者: Mango
现在,当您对深度学习有了一些了解时,让我们大致了解一下Caffe。
训练CNN
让我们学习训练CNN对图像进行分类的过程。该过程包括以下步骤-
-
数据准备-在此步骤中,我们对图像进行中心裁剪并调整其大小,以便用于训练和测试的所有图像都具有相同的大小。这通常是通过在图像数据上运行一个小的Python脚本来完成的。
-
模型定义-在这一步,我们定义一个CNN体系结构。配置存储在.pb(protobuf)文件中。下图显示了典型的CNN架构。
-
求解器定义-我们定义求解器配置文件。求解器进行模型优化。
-
模型训练-我们使用内置的Caffe实用程序来训练模型。培训可能会花费大量时间和CPU使用率。训练完成后,Caffe将模型存储在文件中,以后可用于测试数据和最终部署以进行预测。

Caffe2的新增功能
在Caffe2中,您会发现许多现成的预训练模型,并且还经常利用新模型和算法对社区的贡献。您创建的模型可以使用云中的GPU功能轻松扩展,也可以归因于其跨平台库在移动设备上的大量使用。
与Caffe相比,Caffe2所做的改进可总结如下-
- 移动部署
- 新硬件支持
- 支持大规模的分布式培训
- 量化计算
- 在Facebook上进行压力测试
预训练模型演示
伯克利视觉与学习中心(BVLC)站点提供了其预训练网络的演示。可以在https://caffe2.ai/docs/learn-more#null__caffe-neural-network-for-image-classification所述的链接上找到一种此类图像分类网络,并在下面的屏幕快照中进行了描述。
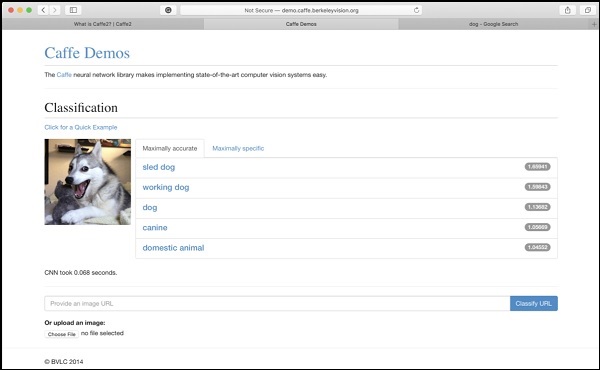
在屏幕截图中,对狗的图像进行了分类并以其预测准确性进行了标记。它还说,仅需0.068秒即可对图像进行分类。您可以通过指定图像网址或在屏幕底部提供的选项中上传图像本身来尝试自己选择的图像。