控制犯罪率的尖叫检测和分析——项目理念
项目名称:使用机器学习和深度学习控制犯罪率的尖叫声检测和分析
犯罪是我们社会日益严重的社会问题。每天都有数以千计的犯罪发生,而且现在还有许多犯罪正在世界各地发生。犯罪有多种面貌,可以发生在任何面貌,如抢劫、谋杀、强奸、严重和简单的殴打、凶杀等。在许多情况下,在犯罪现场观察到没有警察,可能是因为他们没有一个正确的地址,或者有时没有人通知他们。因此,我们试图在我们的项目的帮助下解决这个问题,其中重点是按时侦查犯罪,并通过位置共享通过形式的警报消息帮助最近的警察局官员准时到达犯罪现场SMS (短消息服务)。
介绍
正如标题所暗示的,该项目将是一个桌面应用程序,它具有在后台工作的功能,并通过使用机器学习和深度学习概念,它将检测和分析实时环境中的人类尖叫声,如果发现该应用程序它周围有严重的东西,然后它会自动向最近的警察局发送带有用户位置的警报消息。不仅如此,该应用程序还能够从背景噪音中检测出清晰的人声。
目标:该项目的目标是利用先进技术来帮助某人挽救生命并控制犯罪率。
使用的工具和技术:
- 整个项目后端使用Python语言开发
- 本项目使用 Kivy 框架来设计应用程序的界面,既适用于桌面,也适用于 Android 应用程序。
- 机器学习的SVM(Support Vector Machine)用于尖叫声的检测和分类。
- 深度学习的多层感知器模型用于确认检测到的尖叫声。
所需技能:
- 核心和高级Python知识是强制性的
- 需要基本的 Kivy 框架知识
- 机器学习需要SVM(Support Vector Machine)基础知识
- 机器学习需要神经网络知识
- 必须熟悉pandas、NumPy、scikit-learn、TensorFlow、librosa等库。
执行
让我们来看看这个项目的实施分为以下不同的步骤:
第一步:界面设计
首先,开发项目的 UI 或用户界面。我们将使用 Kivy ( Python) 框架开发 UI,用户将使用该框架进行交互。我们来看看这个项目的 UI。
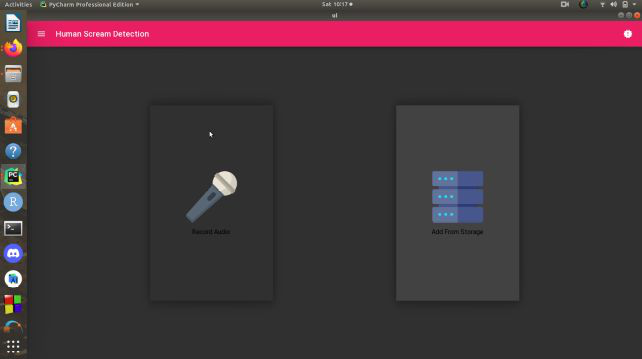
主屏幕
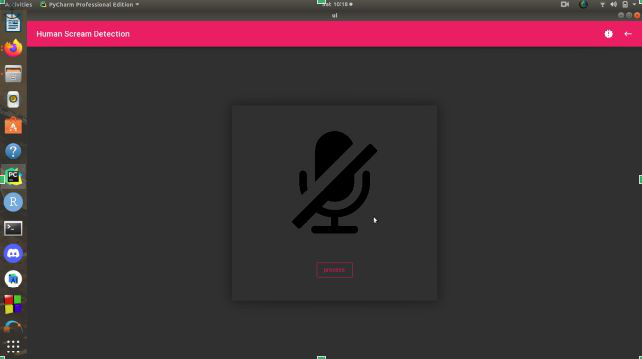
录音画面
步骤 2:准备用于人类尖叫检测的数据集
该项目的整个数据集分为两类,一类是正类,包括大约 2000 个人类尖叫来训练模型,另一类是负类,包括大约 3000 个不被视为尖叫的负面声音。
注意:该项目的数据集是从不同的网站收集的,例如 https://www.freesoundeffects.com/。
第 3 步:提取 MFCC
下一步是使用 Librosa 库从数据集中提取 MFCC,并将提取的 MFCC 保存在计算机上的CSV文件中。
注意: MFCCs 代表 Mel Frequency Cepstral Coefficients,是一种广泛用于自动语音和说话人识别的特征。
第 4 步:SVM 模型的训练和保存
接下来,我们将在上一步创建的那些 MFCC 上训练 SVM(支持向量机)模型,当整个训练完成后,我们将使用 TensorFlow 库保存它。下面给出了使用 SVM 分类器检测噪声、语音、喊叫和尖叫的图表。
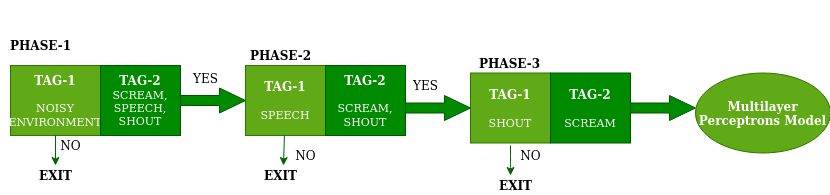
使用 SVM 分类器检测噪音、语音、喊叫和尖叫
第五步:MPN模型的训练和保存
现在,我们将在数据集中存在的声音上训练 MPN(多层感知器模型)以获得模型的良好准确性,当整个训练完成后,再次像我们之前所做的那样使用 TensorFlow 库保存它。 MPN的工作示意图如下。
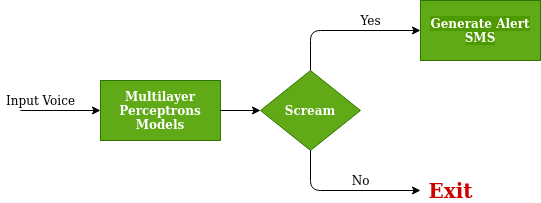
MPN的工作
步骤 6:生成警报消息的方法
现在,在成功训练并保存两个模型后,现在我们将继续测试这两个模型,根据两个模型提供的响应,我们将决定风险级别,并根据风险级别生成警报消息.
在这个项目中,会根据周围的情况生成两种警报消息,即高风险警报消息和中风险警报消息。
- 高危提示信息:当两个模型都检测到周围有人尖叫时,系统会生成高危提示信息。
- 中等风险提示信息:中等 当两个模型之一检测到周围有人尖叫时,系统会自动生成风险警报消息。
第 7 步:向最近的警察局发送短信
但是,该项目目前正在开发中,因此我们仅提供如何开发此功能的想法。对于此功能的开发,我们可以借助数据库,并可以在项目检测到任何紧急情况时向该号码发送短信。
工作图
为您提供了该项目的工作图,它解释了两种模型的内部工作,并将用于实施该项目。

两种模型(SVM 和 MPN)的组合内部工作
输出:
项目在现实生活中的应用
该项目是为了社会安全而提出的。该项目旨在帮助降低犯罪率,也旨在为警察的工作提供很多帮助。此外,该项目的成功还将鼓励开发人员构建对社会安全更有用的东西。
项目验收
该研究论文已在第五届发明系统与控制国际会议 [ICSC 2021]上发表,主题是通过三阶段监督学习和深度学习进行人类尖叫检测。
团队成员
- 亚什·马图尔
- 里亚·马图尔
Github 链接: https : //github.com/themockingjester/Human_Scream_Detection_using_ml_and_deep_learning