Scrapy – 壳
Scrapy是一个组织良好的框架,用于大规模的网页抓取。使用选择器,如 XPath 或 CSS 表达式,可以无缝地抓取数据。它允许系统地抓取和抓取数据,并以不同的文件格式存储内容。 Scrapy 配备了一个外壳,具有不同的用途。在本文中,我们将了解 Scrapy Shell。
破壳
Scrapy 附带一个交互式 shell,它允许运行简单的命令,在不使用蜘蛛代码的情况下抓取数据,并允许测试编写的表达式。使用 XPath 或 CSS 表达式,可以通过传递所需网页的 URL 来查看抓取的数据。要安装 Scrapy,请在终端使用以下命令:
pip install Scrapy配置外壳
一旦我们安装了 Scrapy,使用 pip 命令,我们就可以在标准Python终端上,在任何 IDE 中通过编写命令来执行 shell:
scrapy shell
Scrapy shell,默认情况下,在 PyCharm IDE Terminal 中,安装 Scrapy 库后
或者,可以使用 IPython,一种命令外壳,用于多种编程语言。它是一个丰富的选项,提供优雅的媒体、shell 语法、彩色输出、历史信息和更多功能。如果一个人在 UNIX 操作系统上工作,这将是额外的好处。每个 Scrapy 项目都有一个 'scrapy.cfg' 文件,它是一个配置文件。我们可以在这里定义项目设置。一旦创建了一个scrapy项目,使用'startproject'命令,可以将shell值设置为'ipython'。使用“startproject”命令创建一个 Scrapy 项目,如下所示:
startproject Project_name
Scrapy 项目中的 scrapy.cfg 配置文件
Scrapy.cfg 文件存在于您创建的 Scrapy 项目中。要使用 ipython,请在 scrapy.cfg 中将 'shell' 值设置为 'ipython',如下所示:
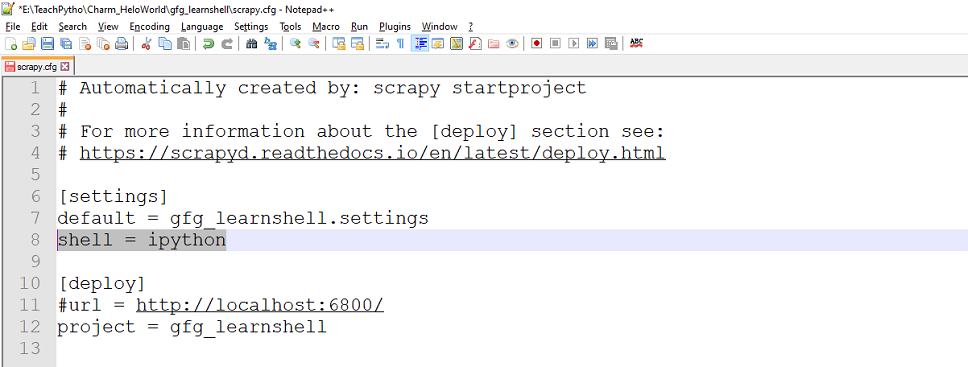
将 'shell' 的值设置为 'ipython' 以使用 IPython Shell
除了IPython,还可以为Python解释器配置'bpython'shell,这是另一种精致的接口解释器。

将 'shell' 的值设置为 'bpython' 以使用 BPython Shell
还可以将环境变量 SCRAPY_PYTHON_SHELL 设置为“ipython”或“bpython”。在本文中,我们使用标准Python终端来进一步研究 Shell。
启动外壳
要启动 shell,可以在终端使用以下命令:
scrapy shell执行命令后,我们可以看到详细信息如下图:
在终端执行命令“scrapy shell”
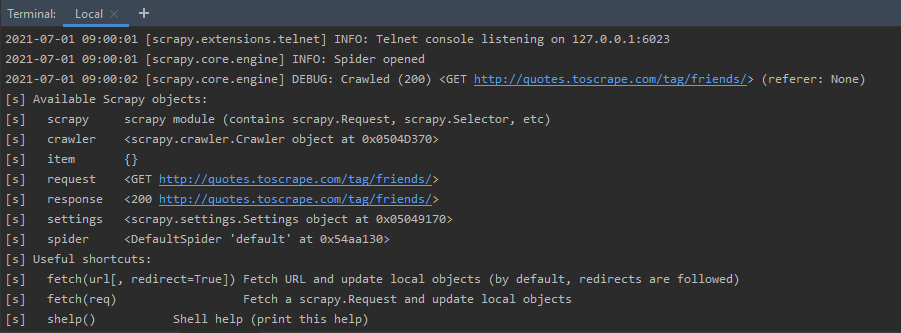
如果我们只是在终端执行命令“scrapy shell”,那么它会启动 Telnet 控制台,用于检查和控制正在运行的 Scrapy 进程。 Telnet 控制台默认启用,是内置的 Scrapy 扩展。它主要是一个普通的Python shell,在 Scrapy 进程中运行。默认情况下,它侦听端口 6023。它显示有关启用的中间件、扩展等的信息。它还显示可用的 Scrapy 对象及其详细信息。通常,我们通过传递网页的URL来启动一个shell,如下所示:
Syntax: scrapy shell
例子:
scrapy shell http://quotes.toscrape.com/tag/friends/
使用 URL 'http://quotes.toscrape.com/tag/friendship/' 启动 shell
shell 处于活动状态,从 URL 中获取的响应如下所示:
为 URL 打开 Spider 并获取响应
执行完上面的命令后,我们得到了关于Telnet控制台、Scrapy对象等的统计信息。主要是因为我们传递了一个URL,蜘蛛对象被打开,并显示响应代码。如果请求成功,则会在输出中看到 HTTP 200 代码。
Shell 上可用的快捷方式
一旦我们学会了启动 shell,我们就可以主要用它来测试抓取代码。在编写任何Python蜘蛛代码之前,应该使用 shell 测试网页以进行抓取。 Scrapy shell 有一些可用的快捷方式。一旦我们启动了 shell,它们就可用了。让我们一一介绍:
shelp(): shelp() 命令,显示 Scrapy 对象列表,以及有用的快捷方式。可以看到,请求对象表示发送到链接 http://quotes.toscrape.com/tag/friends/ 的 GET 请求。此外,响应对象包含一个 200 HTTP 代码,表示请求成功。除此之外,它还提到了 Crawler 和 Spider 对象的位置。

使用“帮助”快捷方式
fetch(URL): 'URL' 是网页的链接,我们需要抓取。获取快捷方式接受一个 URL,即要抓取的网页。它返回蜘蛛信息,以及响应是成功还是失败。在下面的示例中,我们有一个有效的 URL 和一个无效的 URL。根据请求的性质,提取会显示错误或成功代码。
fetch('http://quotes.toscrape.com/tag/friends/')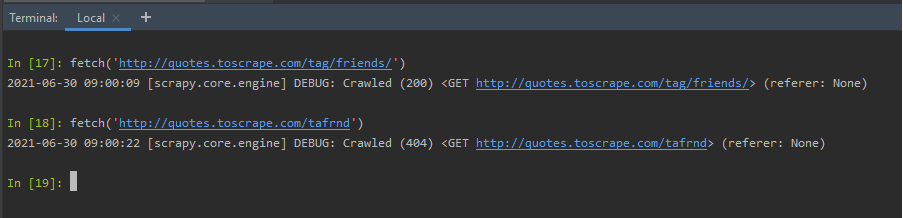
使用 fetch(URL) 快捷方式
fetch(request):我们可以创建一个请求对象,并将其传递给 fetch 方法。为此,创建一个scrapy 对象。请求类提及所需的 HTTP 方法、网页的 URL、标题(如果有)。我们想要抓取 URL 'http://quotes.toscrape.com/tag/friends/',因此,我们将请求对象准备为:
fetch(request_object)
使用 fetch(requestObject) 快捷方式
view(response):视图快捷方式,在默认浏览器中打开网页。网页是作为请求对象或 fetch 方法中的 URL 发送的网页。因此,当我们输入 view(response) 时,在上述 fetch(request) 之后,网页会在默认浏览器中打开。
view(response)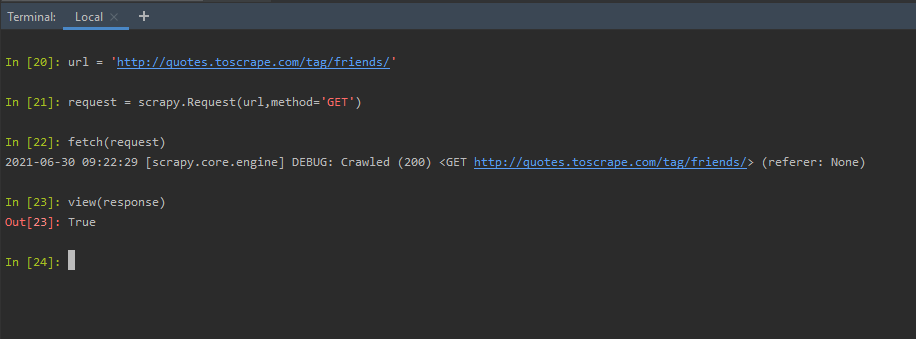
使用视图(响应)快捷方式
该网页是在本地计算机上创建的临时文件。在浏览器中可以看到如下:

用视图打开的网页(响应)
外壳上的 Scrapy 对象
使用 fetch 快捷方式后,通过 URL 或请求对象,我们可以检查可用的 Scrapy 对象。让我们看看可用的 Scrapy 对象——
Crawler:一旦执行了 fetch 方法,我们就可以了解当前的 Crawler 对象。 Crawler 对象提供对 Scrapy 核心组件的访问。爬虫对象通常用 Spider 和 Settings 对象实例化。爬虫在基于 URL 创建的蜘蛛对象的帮助下爬取网页。
crawler要求;在 fetch() 方法之后,我们获得了作为请求发送的 URL 的详细信息。它告诉我们,如果使用的请求方法是 GET 或 POST,或任何其他方法以及 URL。
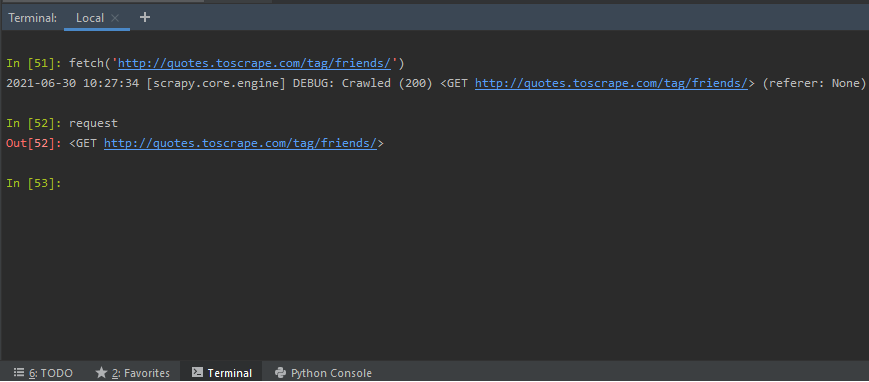
使用请求scrapy对象
响应:执行 fetch() 后,我们可以检查收到的响应的详细信息。可以使用响应对象测试抓取代码,用于蜘蛛代码。抓取代码是使用选择器编写的,带有 XPath 或 CSS 表达式。
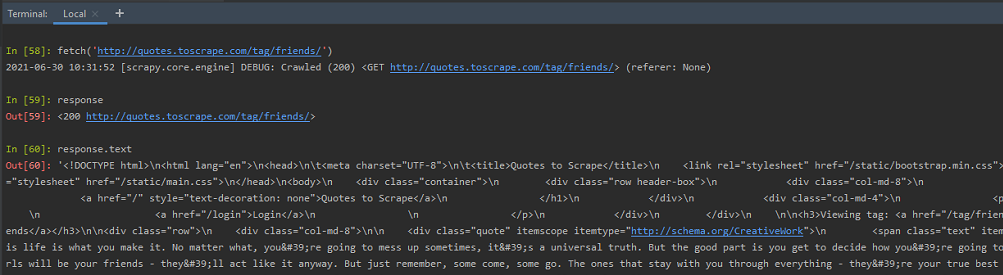
使用 Response 抓取对象
如上所示,我们可以通过在 shell 中编写 response.text 来获取整个页面的 HTML 代码。让我们看看如何使用响应对象和 XPath 或 CSS 表达式来测试抓取代码。 Scrapy 允许使用选择器,从网页中抓取所需的某些信息。这些选择器导航到 HTML 标签,并从中检索数据。
设置: Scrapy 设置对象允许我们自定义 Scrapy 组件的众多行为,例如 Scrapy 核心、扩展、蜘蛛等等。我们可以选择设置与 FTP 密码、HTTPCACHE、FEED 导出、TELNETCONSOLE 等相关的值。
Setting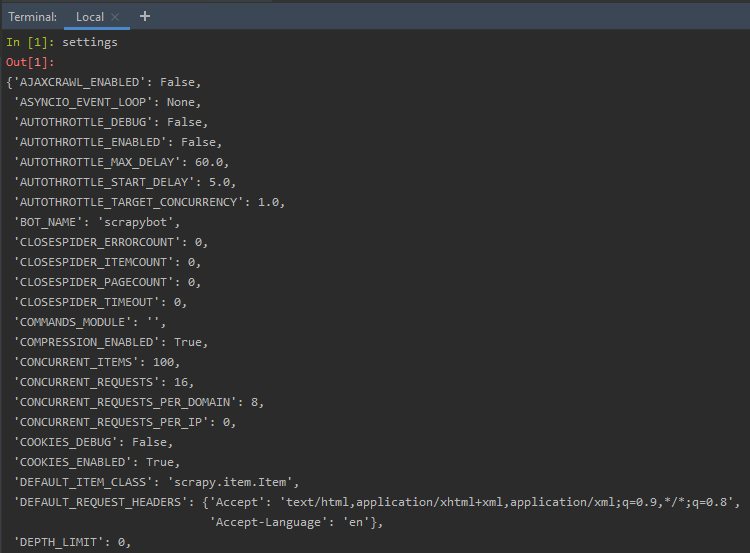
使用设置 Scrapy 对象
从 Scrapy Spider 中调用 Shell
有时,需要分析创建的蜘蛛代码中的响应对象。这可以通过创建一个蜘蛛来完成,并从代码中引用 Shell 模块。要了解相同的内容,请按照以下步骤操作:
第 1 步:创建一个 Scrapy Spider 项目——可以在终端使用“startproject”创建 Spider 项目,如
scrapy startproject gfg_learnshell此命令将创建一个名为“gfg_learnshell”的 Scrapy 项目或文件夹,其中包含所有必需的 Scrapy 配置文件。它还创建了一个 Spider 文件夹,所有与蜘蛛相关的代码都可以在其中写入。 'startproject' 如下所示:
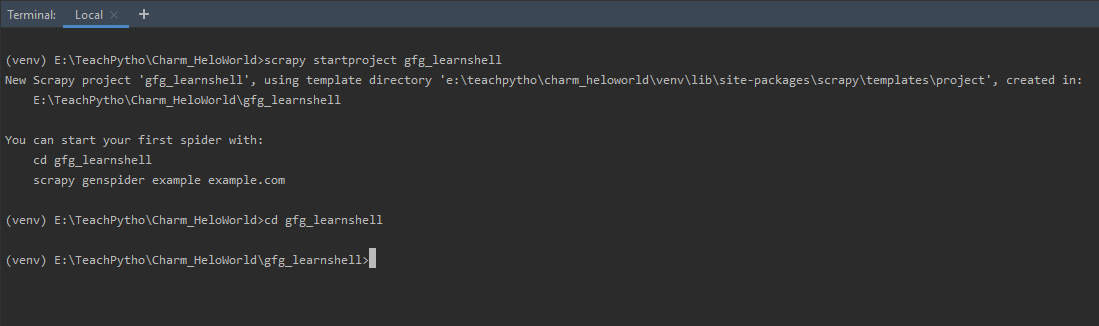
使用 startproject 命令创建一个 Scrapy 项目
第2步:创建一个Spider Python文件,然后将目录更改为新创建的文件夹“gfg_learnshell”。使用“genspider”命令创建一个包含 URL 的 Spider Python文件,将其删除:
scrapy genspider spider_name url_to_be_scraped在本例中,我们将抓取网页“http://quotes.toscrape.com/tag/friends/”。因此,我们将在终端执行命令:
scrapy genspider learnshell quotes.toscrape.com/tag/friends上面的命令将在蜘蛛文件夹中创建一个名为“learnshell.py”的Python文件。这是我们的spider,这里写了抓取代码。默认情况下,蜘蛛代码如下所示:
Python3
# Import the required Scrapy library
import scrapy
# The Spider class created
class LearnshellSpider(scrapy.Spider):
# Name of spider mentioned in 'genspider'
# command
name = 'learnshell'
# The domain to be scraped
allowed_domains = ['quotes.toscrape.com/tag/friends/']
# The allowed URLs to be scraped
start_urls = ['http://quotes.toscrape.com/tag/friends/']
# The default callback parse method
def parse(self, response):
passPython3
# Import the required libraries
import scrapy
# The Spider code
class LearnshellSpider(scrapy.Spider):
# Name of the spider
name = 'learnshell'
# The domain allowed for scraping
allowed_domains = ['quotes.toscrape.com/tag/friends']
# The URL(s) to be scraped
start_urls = ['http://quotes.toscrape.com/tag/friends/']
# Default callback method called when a spider crawls
def parse(self, response):
if "quotes" in response.url:
# Invoke the Scrapy Shell and inspect the response
from scrapy.shell import inspect_response
# Inspect the response
inspect_response(response, self)
# Execute rest of the code after
# inspecting the response at shell and exit()
# XPath selector for fetching the author names
quotes = response.xpath('//*[@class="author"]/text()').extract()
# The spider crawls and prints the authors
# present on the URL
yield{'Authors': quotes}我们将从代码中调用 Scrapy Shell,并检查响应。现在,蜘蛛代码如下所示:
蟒蛇3
# Import the required libraries
import scrapy
# The Spider code
class LearnshellSpider(scrapy.Spider):
# Name of the spider
name = 'learnshell'
# The domain allowed for scraping
allowed_domains = ['quotes.toscrape.com/tag/friends']
# The URL(s) to be scraped
start_urls = ['http://quotes.toscrape.com/tag/friends/']
# Default callback method called when a spider crawls
def parse(self, response):
if "quotes" in response.url:
# Invoke the Scrapy Shell and inspect the response
from scrapy.shell import inspect_response
# Inspect the response
inspect_response(response, self)
# Execute rest of the code after
# inspecting the response at shell and exit()
# XPath selector for fetching the author names
quotes = response.xpath('//*[@class="author"]/text()').extract()
# The spider crawls and prints the authors
# present on the URL
yield{'Authors': quotes}
解释:
- 当我们运行“genspider”命令时,会分配蜘蛛名称、允许的域和 URL。
- 默认的 parse 方法是一个回调方法,在蜘蛛爬行时调用。它返回一个响应对象。
- 我们通过使用 scrapy.shell 模块调用 Scrapy shell。它有一个 'inspect_response' 方法,允许我们检查 shell 中的任何 Selector 表达式。因此,当我们使用“crawl”语法运行爬虫代码时,它会在两次执行之间打开 shell 窗口,并允许我们检查任何响应。爬网语法是“scrapy crawl spider_name”。
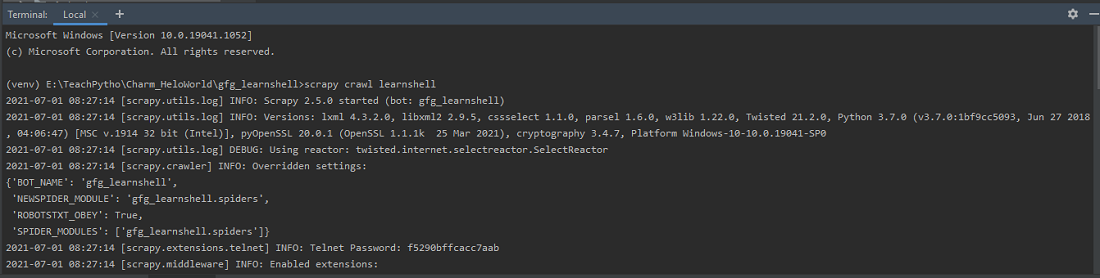
使用 'crawl' 命令运行蜘蛛
第 3 步:因此,在执行之间,如果我们在 shell 中键入任何语法,例如,通过使用以下命令检查响应正文的长度:
len(response.text)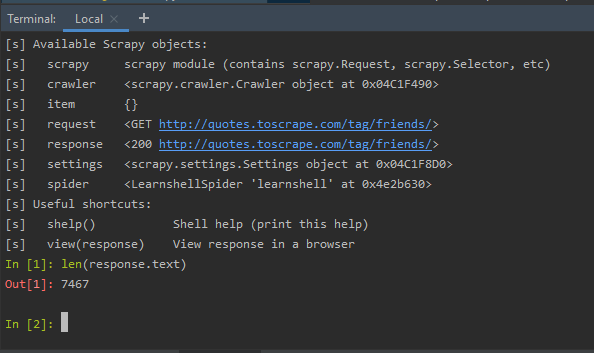
检查蜘蛛代码执行之间的响应对象
上述检查是可以的,因为我们在Spider Python代码中使用了inspect_response方法。一旦我们输入exit(),我们就会退出shell,剩下的蜘蛛代码执行就完成了。如下图——
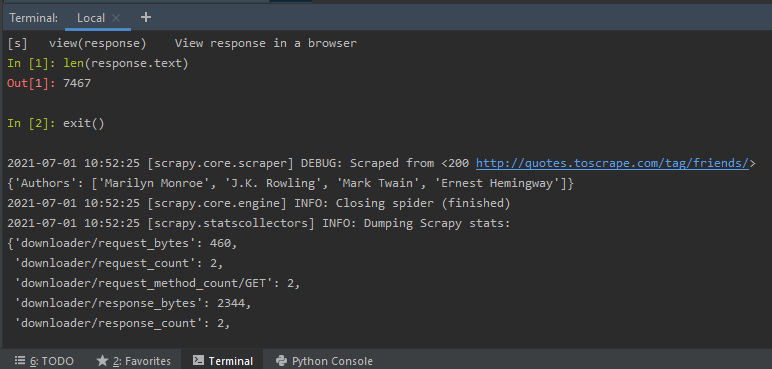
在 exit() 之后,蜘蛛代码的其余部分被执行和抓取
在 exit() 之后,将执行其余的Python代码,并根据代码中编写的选择器抓取作者的姓名。