Scrapy – 设置
Scrapy 是一个用Python框架构建的开源工具。它为我们提供了一个强大而健壮的网络爬虫框架,可以在 XPath 支持的选择器的帮助下轻松地从在线页面中提取信息。
我们可以在 Scrapy 设置的帮助下定义 Scrapy 组件的行为。管道和设置文件对于scrapy非常重要。它是自动化任务的核心。这些规则有助于将数据插入数据库。当我们从基本模板开始时,这些文件是包含的。 Scrapy 设置允许您自定义所有 Scrapy 组件的行为,包括核心、扩展、管道和蜘蛛本身。
我们经常遇到需要定义多个crapper项目的情况,在这种情况下,我们可以在scrapy设置的帮助下定义哪个单独的项目。为此,应使用环境变量 SCRAPY_SETTINGS_MODULE,其值应采用Python路径语法。因此,在 Scrapy 设置的帮助下,可以指定选择当前活动的 Scrapy 项目的机制。
设置的基础结构提供了键值映射的全球命名空间,代码可以使用该命名空间从中提取配置值。这些设置通常通过不同的机制填充,如下所述。
使用这些命令启动scrapy 模板文件夹。
scrapy startproject 
这是scrapy项目的基本轮廓。
在本文中,我们将重点关注 settings.py 文件。
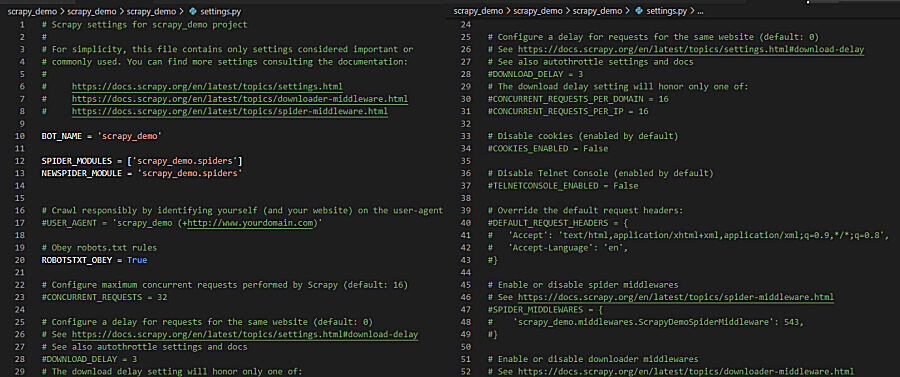
settings.py 文件看起来像这样。我们将此作为我们的默认设置。
最常用的设置及其说明如下:
重要的 Scrapy 设置
- BOT_NAME
它是项目的名称。机器人象征着我们在刮板的帮助下所做的自动化。它默认为“scrapybot”。同样如屏幕截图所示,当您启动项目时,它会自动与您的项目名称一起使用。
- 用户代理
User-Agent 帮助我们进行识别。它基本上告诉服务器和网络对等点“你是谁”。它有助于识别请求用户代理的应用程序、操作系统、供应商和/或版本。除非明确指定,否则在抓取时默认为“Scrapy/VERSION (+https://scrapy.org)”。
浏览器的常用格式:
User-Agent: / () () 例如:
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)'- ROBOTSTXT_OBEY
robots.txt 文件基本上告诉搜索引擎的爬虫可以从站点请求哪些页面。 ROBOTSTXT_OBEY 默认为“假”。它主要保持启用状态,因此我们的 scrapy 将尊重网站的 robots.txt 政策。
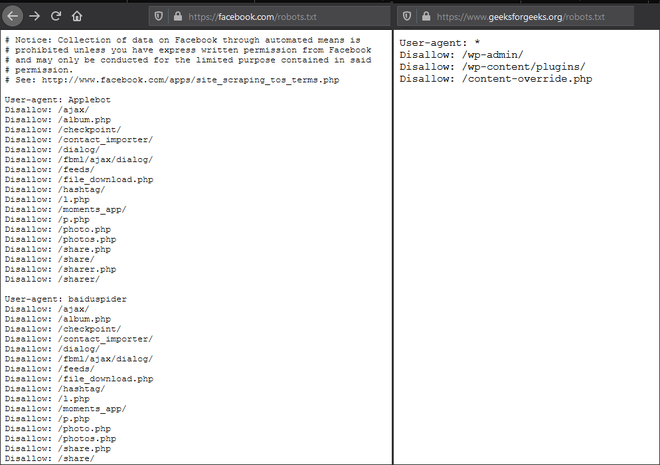
图像显示了文件robots.txt 的内容,这里写的策略由ROBOTSTXT_OBEY 设置管理。
- CONCURRENT_REQUESTS
它基本上是要求网站打开。它默认为 16。所以基本上它是爬虫将执行的最大请求数。
更多的请求会增加服务器的负载,因此将其保持为 16 或 32 是一个不错的值。
- CONCURRENT_ITEMS
这意味着在抓取数据时,scrapy 将在每个响应中并行处理的最大并发项目数是多少。它默认为 100,这也是一个很好的值。
custom_settings = {
'CONCURRENT_REQUESTS' = 30,
'CONCURRENT_ITEMS' = 80,
}- CONCURRENT_REQUESTS_PER_DOMAIN
这意味着在抓取数据时,可以为任何单个域值并发执行的最大现有请求数是多少。默认值为“8”。
- CONCURRENT_REQUESTS_PER_IP
这意味着在抓取数据时,可以为任何单个 IP 地址同时执行的最大现有请求数是多少。它默认为值“0”。
custom_settings = {
'CONCURRENT_REQUESTS_PER_DOMAIN' = 8,
'CONCURRENT_REQUESTS_PER_IP' = 2
}- DOWNLOAD_DELAY
这是下载者再次从网站下载页面之前的延迟时间。这再次用于限制托管网站的服务器上的负载。它默认为 0。
例如:
DOWNLOAD_DELAY = 0.25 # 250 ms of delay- DOWNLOAD_TIMEOUT
现在是超时时间。告诉scrapy 在下载器超时之前等待给定的时间。默认为 180。
- LOG_ENABLED
它用于启用或禁用刮板的日志记录。它默认为“真”。
- FTP_密码
用于设置 FTP 连接的密码。仅当请求元中没有“ftp_password”时才使用该值。它默认为“客人”。
- FTP_USER
用于设置 FTP 连接的用户名。仅当请求元中没有“ftp_user”时才使用该值。它默认为“匿名”。
- DEFAULT_ITEM_CLASS
此设置用于表示scrapy 中的项目,值以DEFAULT_ITEM_CLASS 指定的此类格式存储。默认格式由“scrapy.item.Item”给出。
- DEFAULT_REQUEST_HEADERS
给定的设置列出了 Scrapy 发出的 HTTP 请求所使用的默认标头。它填充在 DefaultHeadersMiddleware 中。
默认标头值由以下给出:
{
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}- REACTOR_THREADPOOL_MAXSIZE
反应器线程池也可以设置在scrapy中。它绑定了蜘蛛的反应器线程池的最大大小。其默认大小为 10。
例如,可以在代码中应用这些设置,如以下Python代码:
class exampleSpider(scrapy.Spider):
name = 'example'
custom_settings = {
'CONCURRENT_REQUESTS': 25,
'CONCURRENT_REQUESTS_PER_DOMAIN': 100,
'DOWNLOAD_DELAY': 0
}
f = open("example")
start_urls = [url.strip() for url in f.readlines()]
f.close()
def parse(self, response):
for itemin response.xpath("//div[@class=]"):
urlgem = item.xpath(".//div[@class=]/a/@href").extract() - AWS_ACCESS_KEY_ID
有了这个,你可以在你的scrapy中设置AWS ID,它用于访问亚马逊网络服务。它默认为“无”值。
- AWS_SECRET_ACCESS_KEY
有了这个,你可以在你的scrapy中设置AWS访问密钥(密码或ID凭证),它用于访问亚马逊网络服务。它默认为“无”值。
- DEPTH_LIMIT
蜘蛛爬取目标站点的限制深度。它默认为 0。
- DEPTH_PRIORITY
它进一步管理爬取目标站点的深度优先级。它也默认为 0。
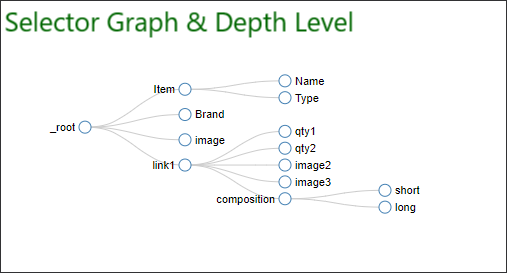
这是 Scrapy 中选择器图的基本布局。组件可以构建在这个 Selector Graph 中。每个组件负责从站点中报废单个项目。
- DEPTH_STATS
通过此设置,我们还可以在所爬取的级别的日志中收集深度统计信息。如果启用该设置,则每个深度的每个单独请求的值都将收集在统计信息中。它的默认值为“真”。
- DEPTH_STATS_VERBOSE
通过启用在每个详细深度的统计信息中收集的请求数,进一步改进 DEPTH_STATS。
默认情况下,它是“假”。
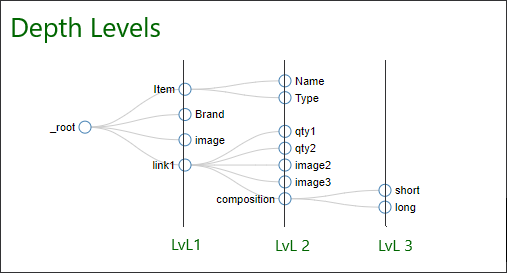
选择器级别可以扩展到由网站管理员构建的无限深度。通过各种深度设置,我们有责任限制爬虫中的选择器图。
- DNSCACHE_ENABLED
通过此设置,我们可以在内存缓存中启用 DNS。默认情况下,它是“真”。
- DNSCACHE_SIZE
通过此设置,我们可以定义 DNS 内存缓存的大小。其默认值为 10000。
- DNS_TIMEOUT
这是DNS处理scrapy查询的超时时间。默认为 60。
- 下载器
爬虫使用的实际下载器。默认格式由“scrapy.core.downloader.Downloader”给出。
- 下载器_中间件
字典保存下载中间件及其命令。它默认为空。
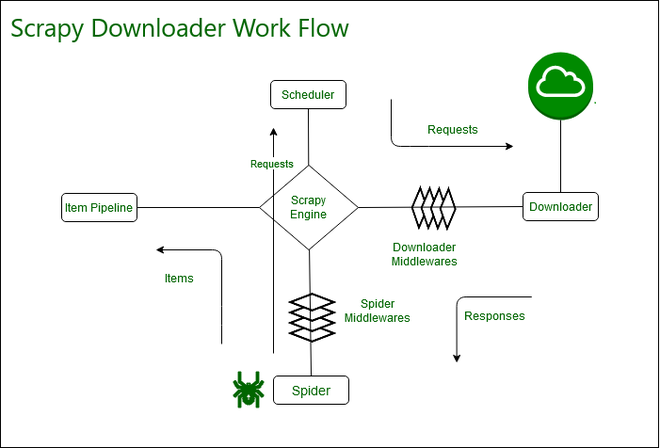
- EXTENSIONS_BASE
具有内置扩展值的字典。默认值:{ 'scrapy.extensions.corestats.CoreStats': 0, }
- FEED_TEMPDIR
这是一个目录,用于设置存储爬虫临时文件的自定义文件夹。
- ITEM_PIPELINES
我们可以将scrapy 字典定义为具有管道,这表示加入每个项目类的管道。它的默认值为 null。
- LOG_STDOUT
使用此设置,如果设置为 true,则所有并发进程输出都将出现在日志文件中。其默认值为 False。
设置值
建议将这些值手动放入 settings.py 文件中。不过,还有一个选项可以使用命令行修改这些值。
例如:
如果要生成scrapy 日志文件,请使用以下命令。
scrapy crawl myspider -s LOG_FILE=scrapy.log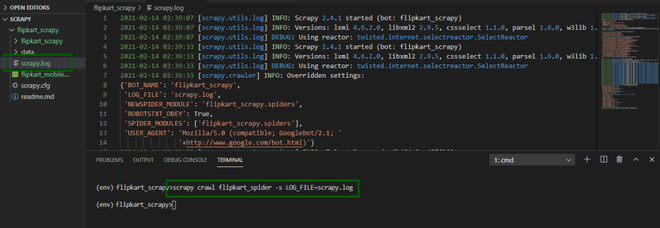
结论:这是scrapy最重要的文件。只有使用此文件,您才能自定义所有 Scrapy 组件的行为。