- 社交媒体数据挖掘
- 社交媒体数据挖掘(1)
- 什么是社交媒体?
- 什么是社交媒体?(1)
- 正确使用社交媒体的 5 种方法(1)
- 正确使用社交媒体的 5 种方法
- 社交媒体的元标记 - Html (1)
- 社交媒体营销(1)
- 社交媒体营销
- 社交媒体的元标记 - Html 代码示例
- 数字营销-社交媒体
- 数字营销-社交媒体(1)
- 如何在HTML中添加社交媒体图标
- 如何在HTML中添加社交媒体图标(1)
- 社交 (1)
- 社交媒体 HTML 的缩略图 (1)
- 如何在 HTML 中包含社交媒体图标?(1)
- 如何在 HTML 中包含社交媒体图标?
- 内容营销-社交媒体
- 内容营销-社交媒体(1)
- 移动社交媒体营销
- 移动社交媒体营销(1)
- 社交媒体营销服务 (1)
- 数据挖掘(1)
- 数据挖掘
- 数据挖掘 | 2套(1)
- 数据挖掘
- 数据挖掘 | 2套
- Flutter – 社交媒体身份验证按钮
📅 最后修改于: 2020-12-21 09:51:35 🧑 作者: Mango
社交媒体数据挖掘方法
与社交网络分析相关的其他研究领域相比,将数据挖掘技术应用于社交媒体相对较新。当我们承认对社交媒体网络分析的研究可以追溯到1930年代。使用由工业界和学术界开发的数据挖掘技术的应用程序已经在商业上使用。例如,“社交媒体分析”组织向我们提供服务并跟踪社交媒体,以向客户提供有关如何通过社交媒体网络识别和讨论商品和服务的数据。该组织中的分析师已经应用了文本挖掘算法,并检测到博客的传播模型,从而创建了可以更好地理解数据如何在博客圈中移动的技术。
可以对社交媒体站点实施数据挖掘技术,以更好地理解信息,并将数据用于分析,研究和商业目的。代表性领域包括社区或群体检测,数据传播,受众传播,主题检测和跟踪,个人行为分析,群体行为分析以及组织的市场研究。
数据表示
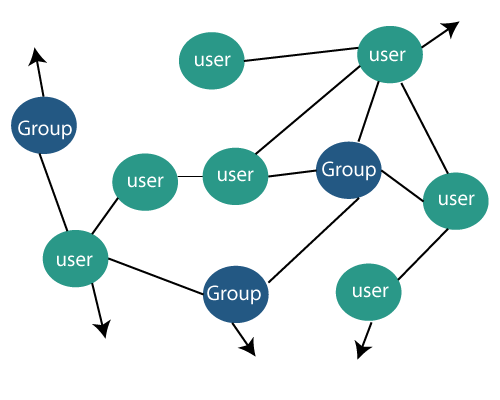
与其他社交媒体数据类似,使用图形表示来研究社交媒体数据集也是可以接受的。图包括一组包含顶点(节点)和边(链接)的图。用户通常显示为图中的节点。个人(节点)之间的关系或公司在图中显示为链接。
对于从社交网站提取的信息,人们与朋友,家人和商业伙伴进行交互时,图形描绘很常见。它有助于建立由朋友,家人或业务伙伴组成的社交网络。图结构是如何应用于博客,Wiki,意见挖掘和类似类型的在线社交媒体平台的,这一点还不太明显。
如果我们考虑博客,则一个图形表示以博客形式发布为节点,可以视为“博客网络”,而另一个图形描述以博客帖子为节点,可以视为“后网络”。当另一博客文章引用另一博客文章时,将在博客文章网络中创建边缘。用于表示博客网络的其他技术同时考虑了个人,关系,内容和时间,称为Internet在线分析处理(iOLAP)。可以从将作者描绘为节点的上下文中考虑Wiki,并且当作者为某个对象做出贡献时会创建边缘。
图形表示允许应用经典的数学图论,分析社交媒体平台和研究图数据的传统技术。用于描绘社交媒体平台的图表可能很大,可能会由于计算机内存的限制而给自动处理带来困难。在尝试处理庞大的社交媒体数据集时,处理速度将最大化,并且通常会超过处理速度。实施自动化程序以允许社交媒体数据挖掘的其他挑战包括识别和处理垃圾邮件,社交媒体的同一子类别中使用的各种格式以及不断更改内容和结构。
数据挖掘-一个过程
无论正在研究哪种类型的社交媒体,都必须考虑一些基本问题,以使最有意义的结果可行。每种类型的社交媒体和应用于社交媒体的每种数据挖掘目的都可能涉及独特的方法和算法,以从数据挖掘中获得好处。各种数据集和数据问题包括不同种类的工具。如果知道如何组织数据,则可以使用分类工具。如果我们了解数据的含义,但无法确定数据的趋势和模式,则使用群集工具可能是最好的方法。
问题本身可以得出最佳方法。在应用数据挖掘技术以及了解可用的各种数据挖掘工具之前,没有其他选择可以尽可能地了解数据。可能需要主题分析师来帮助更好地理解数据集。为了更好地理解可用于数据挖掘的各种工具,有大量的数据挖掘和机器学习文本以及可用于支持有关各种特定数据挖掘技术和算法的更准确信息的不同资源。
了解问题并选择适当的数据挖掘方法后,请考虑需要进行的任何预处理。还可能需要系统的过程来开发足够的数据集,以允许合理的处理时间。预处理应包括适当的隐私保护机制。尽管社交媒体平台包含大量可公开访问的数据,但是重要的是要确保个人权利,并确保社交媒体平台的版权。垃圾邮件的影响应与时间表示形式一起考虑。
除了预处理之外,还必须考虑时间的影响。根据查询和研究的结果,虽然时间段是特定领域的可考虑因素,但我们可能一次获得的结果会与另一个时间有所不同。例如,主题检测,影响传播和网络发展,时间对网络识别,群体行为和营销的影响不太明显。在一个时间点定义网络的内容在另一个时间点可能会显着不同。一段时间后,小组的行为和兴趣将发生变化,今天提供给个人或小组的东西明天可能不会流行。
将数据描绘为图形,任务从选定数量的节点(称为种子)开始。从种子的排列开始遍历图形,并使用来自种子节点的链接结构,收集数据,并对结构本身进行检查。利用链接结构从种子集中延伸并收集新信息称为对网络进行爬网。作为搜寻器执行的应用程序和算法应有效管理强大的社交媒体平台中存在的挑战,例如受限站点,格式更改和结构错误(无效链接)。搜寻器发现新数据时,会将新数据存储在存储库中以进行进一步分析。找到链接数据后,搜寻器将更新有关网络结构的数据。
一些社交媒体平台(例如Facebook,Twitter和Technorati)提供了应用程序程序员接口(API),这些API允许搜寻器应用程序直接与数据源进行交互。但是,这些平台通常依赖于API用户与平台之间的隶属关系来限制每天API交易的数量。对于某些平台,无需使用API即可收集数据(抓取)。鉴于可用的社交媒体平台数据量巨大,可能有必要限制搜寻器收集的数据量。搜寻器收集到数据后,可能需要进行一些后处理才能验证和清理数据。可以应用传统的社交媒体平台分析方法,例如,集中度测量和群体结构研究。在许多情况下,其他数据将与节点或链接相关,这将为更复杂的方法提供机会,以考虑可以通过文本和数据挖掘技术公开的更周到的语义。
现在,我们将重点放在两个特定的社交媒体平台数据上,以进一步表示数据挖掘技术如何应用于社交媒体网站。两个主要领域是社交媒体平台,博客功能强大,并且丰富的数据源在这两个领域都有体现。这两个领域为更广泛的科学网络和商业组织提供了潜在的价值。
社交媒体平台:示例
社交媒体平台(如Facebook或LinkedIn)由具有独特个人资料的关联用户组成。用户可以与他们的朋友和家人互动,并可以共享新闻,照片,故事,视频,喜欢的链接等。用户可以选择根据个人喜好自定义个人资料,但一些常用数据可能包含关系状态,生日,电子邮件地址和家乡。用户可以选择在个人资料中包含多少数据以及有权访问这些数据的人。通过社交媒体平台访问的数据量引起了安全问题,并且是一个相关的社会问题。
在此,该图说明了典型社交媒体平台的假设图结构图,箭头表示指向该图较大部分的链接。
在使用社交媒体平台数据时,确保个人身份很重要。最近的报告强调了保护隐私的必要性,因为已经证明,当使用高级数据分析策略时,即使匿名化此类数据仍然可以显示单个数据。安全设置还可能限制数据挖掘应用程序考虑社交媒体平台上的每个数据的能力。但是,可以使用一些令人发指的技术来接管安全设置。