📌 相关文章
- Node.js 缓冲区(1)
- Node.js 缓冲区
- Node.js-缓冲区
- Node.js 中的缓冲区是什么?
- Node.js 中的缓冲区是什么?
- Node.js 中的缓冲区是什么?(1)
- Node.js 中的缓冲区是什么?(1)
- 缓冲区与流 (1)
- Node.js 缓冲区完整参考(1)
- Node.js 缓冲区完整参考
- Node.js NPM 数组缓冲区到字符串模块
- Node.js NPM 字符串到数组缓冲区模块(1)
- Node.js NPM 数组缓冲区到字符串模块(1)
- Node.js NPM 字符串到数组缓冲区模块
- Node.js 中的全局、进程和缓冲区(1)
- Node.js 中的全局、进程和缓冲区
- js 字符串到数组缓冲区 - Javascript (1)
- nodejs 数组缓冲区到缓冲区 - Javascript (1)
- js 字符串到数组缓冲区 - Javascript 代码示例
- nodejs 数组缓冲区到缓冲区 - Javascript 代码示例
- 缓冲区与流 - 任何代码示例
- Node.js 流(1)
- Node.js流
- Node.js-流
- Node.js-流(1)
- Node.js 流
- Node.js流(1)
- node js从url下载图像作为缓冲区 - Javascript代码示例
- 输入缓冲区 (1)
📜 Node.js缓冲区
📅 最后修改于: 2020-12-24 03:41:40 🧑 作者: Mango
Node.js缓冲区
Node.js提供Buffer类来存储类似于整数数组的原始数据,但对应于V8堆外部的原始内存分配。之所以使用Buffer类,是因为纯JavaScript不适用于二进制数据。因此,在处理TCP流或文件系统时,必须处理八位位组流。
缓冲区类是全局类。可以在应用程序中访问它,而无需导入缓冲模块。
Node.js创建缓冲区
有很多方法可以构造节点缓冲区。以下是三种最常用的方法:
- 创建未初始化的缓冲区:以下是创建10个八位字节的未初始化缓冲区的语法:
- var buf = new Buffer(10);
- 从数组创建缓冲区:以下是从给定数组创建缓冲区的语法:
- var buf = new Buffer([10,20,30,40,50]);
- 从字符串创建缓冲区:以下是从给定字符串和可选编码类型创建缓冲区的语法:
- var buf = new Buffer(“ Simplely Easy Learning”,“ utf-8”);
Node.js写入缓冲区
以下是写入节点缓冲区的方法:
句法:
buf.write(string[, offset][, length][, encoding])
参数说明:
字符串:它指定要写入缓冲区的字符串数据。
offset:指定要开始写入的缓冲区的索引。默认值为0。
length:指定要写入的字节数。默认为buffer.length
encoding:使用编码。 'utf8'是默认编码。
从写缓冲区返回值:
此方法用于返回写入的八位位组数。如果缓冲区不足以容纳整个字符串,则它将写入字符串的一部分。
让我们举个例子:
创建一个名为“ main.js”的JavaScript文件,其中包含以下代码:
文件:main.js
buf = new Buffer(256);
len = buf.write("Simply Easy Learning");
console.log("Octets written : "+ len);
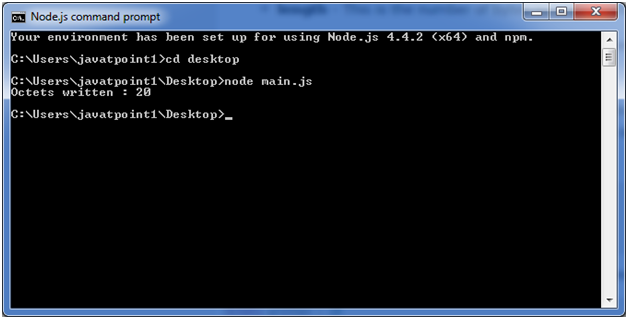
打开Node.js命令提示符并执行以下代码:
node main.js
输出:
Node.js从缓冲区读取
以下是从节点缓冲区读取数据的方法。
句法:
buf.toString([encoding][, start][, end])
参数说明:
encoding:指定要使用的编码。 'utf8'是默认编码
start:指定开始读取的起始索引,默认为0。
end:指定要结束读取的结束索引,默认为完整缓冲区。
返回从缓冲区读取的值:
此方法从使用指定字符集编码编码的缓冲区数据中解码并返回字符串。
让我们举个例子:
文件:main.js
buf = new Buffer(26);
for (var i = 0 ; i < 26 ; i++) {
buf[i] = i + 97;
}
console.log( buf.toString('ascii')); // outputs: abcdefghijklmnopqrstuvwxyz
console.log( buf.toString('ascii',0,5)); // outputs: abcde
console.log( buf.toString('utf8',0,5)); // outputs: abcde
console.log( buf.toString(undefined,0,5)); // encoding defaults to 'utf8', outputs abcde
打开Node.js命令提示符并执行以下代码:
node main.js
输出:
