📌 相关文章
- Apache Spark RDD共享变量(1)
- Apache Spark RDD共享变量(1)
- Apache Spark RDD
- Apache Spark RDD
- Apache Spark-RDD
- Apache Spark RDD(1)
- Apache Spark RDD操作
- Apache Spark RDD操作(1)
- Apache Spark RDD操作(1)
- Apache Spark RDD操作
- Spark¢RDD
- Spark¢RDD(1)
- Apache Spark RDD持久性(1)
- Apache Spark RDD持久性
- Apache Spark RDD持久性(1)
- Apache Spark RDD持久性
- Apache Spark安装
- Apache Spark安装(1)
- Apache Spark-安装(1)
- Apache Spark安装
- Apache Spark-安装
- Apache Spark组件(1)
- Apache Spark组件
- Apache Spark 的组件
- Apache Spark组件
- Apache Spark组件(1)
- Apache Spark 的组件(1)
- Apache Spark教程
- Apache Spark教程
📜 Apache Spark RDD共享变量
📅 最后修改于: 2020-12-27 02:39:09 🧑 作者: Mango
RDD共享变量
在Spark中,当任何函数传递给转换操作时,它将在远程集群节点上执行。它对函数中使用的所有变量的不同副本函数。这些变量将复制到每台计算机,并且远程计算机上的变量的任何更新都不会还原到驱动程序。
广播变量
广播变量支持在每台计算机上缓存的只读变量,而不是提供带有任务的副本。 Spark使用广播算法来分发广播变量,以降低通信成本。
火花动作的执行经过多个阶段,由分布式“随机播放”操作分隔。 Spark自动广播每个阶段中任务所需的通用数据。在运行每个任务之前,以这种方式广播的数据以序列化形式缓存并反序列化。
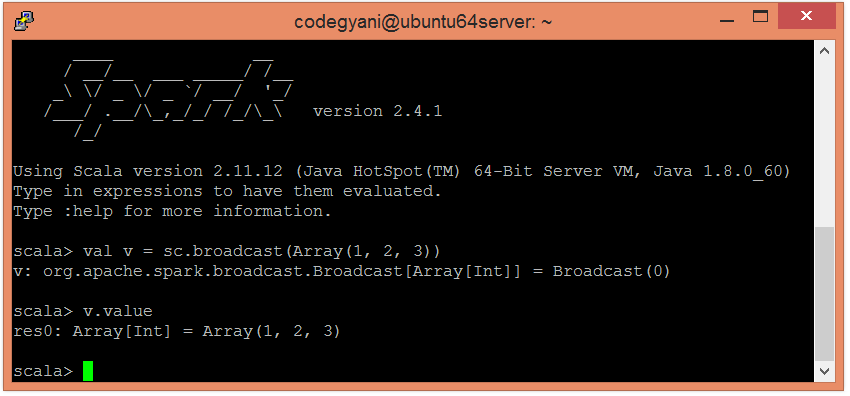
要创建广播变量(假设为v),请调用SparkContext.broadcast(v)。让我们看一个例子。
scala> val v = sc.broadcast(Array(1, 2, 3))
scala> v.value
累加器
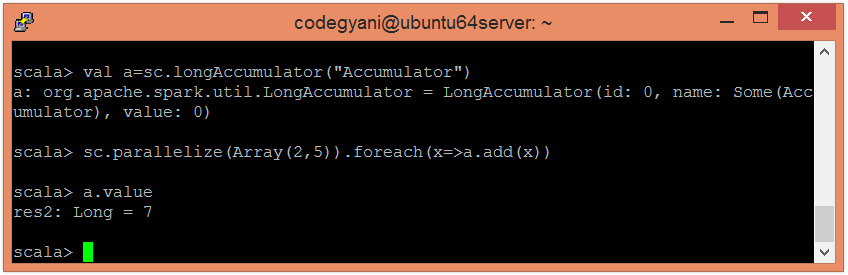
累加器是用于执行关联和交换操作的变量,例如计数器或总和。 Spark为数字类型的累加器提供支持。但是,我们可以添加对新类型的支持。
要创建数字累加器,请调用SparkContext.longAccumulator()或SparkContext.doubleAccumulator()来累加Long或Double类型的值。
scala> val a=sc.longAccumulator("Accumulator")
scala> sc.parallelize(Array(2,5)).foreach(x=>a.add(x))
scala> a.value