Pandas 内置数据可视化 |机器学习
数据可视化是以图形格式呈现数据。它通过以简单易懂的格式汇总和呈现大量数据,帮助人们理解数据的重要性,并有助于清晰有效地传达信息。
在本教程中,我们将了解 pandas 内置的数据可视化功能!它是由 matplotlib 构建的,但为了更容易使用,它被烘焙到 pandas 中!
让我们来看看!
安装
安装 pandas 最简单的方法是使用 pip:
pip install pandas
或者,从这里下载
本文通过绘制不同类型的图表演示了如何在 pandas 中使用内置数据可视化功能。
导入必要的库和数据文件 –
可以从此处下载本教程中使用的示例 csv 文件 df1 和 df2。
import numpy as np
import pandas as pd
# There are some fake data csv files
# you can read in as dataframes
df1 = pd.read_csv('df1', index_col = 0)
df2 = pd.read_csv('df2')
样式表 –
Matplotlib 具有样式表,可用于使绘图看起来更好一些。这些样式表包括plot_bmh 、 plot_fivethirtyeight 、 plot_ggplot等等。他们基本上创建了一组您的情节遵循的样式规则。我们建议使用它们,它们使您的所有情节都具有相同的外观和感觉更专业。如果希望公司的情节都具有相同的外观,我们甚至可以创建自己的情节(虽然创建起来有点乏味)。
以下是如何使用它们。
plt.style.use()之前的图如下所示:
df1['A'].hist()
输出 : 
调用样式:
现在,调用ggplot样式后的绘图如下所示:
import matplotlib.pyplot as plt
plt.style.use('ggplot')
df1['A'].hist()
输出 : 
调用bmh样式后的绘图如下所示:
plt.style.use('bmh')
df1['A'].hist()
输出 : 
调用dark_background样式后的绘图如下所示:
plt.style.use('dark_background')
df1['A'].hist()
输出 : 
调用fivethirtyeight样式后的绘图如下所示:
plt.style.use('fivethirtyeight')
df1['A'].hist()
输出 : 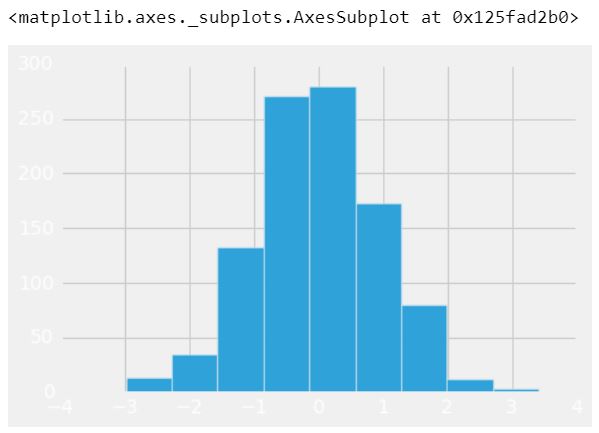
地块类型——
pandas 内置了几种绘图类型,其中大多数是统计绘图:
您也可以只调用df.plot(kind='hist')或将 kind 参数替换为上面列表中显示的任何关键术语(例如“box”、“barh”等)。让我们开始浏览它们吧!
1.) 面积
面积图或面积图以图形方式显示定量数据。它基于折线图。轴和线之间的区域通常用颜色、纹理和阴影来强调。通常将两个或多个数量与面积图进行比较。
df2.plot.area(alpha = 0.4)
输出 : 
2.) 条形图
条形图或条形图是一种图表或图形,它使用矩形条显示分类数据,矩形条的高度或长度与它们所代表的值成比例。条形图可以垂直或水平绘制。垂直条形图有时称为折线图。
df2.head()
输出 : 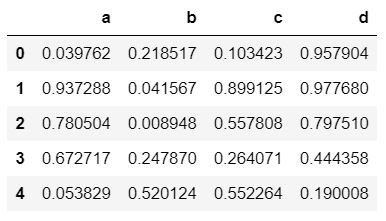
df2.plot.bar()
输出 : 
df2.plot.bar(stacked = True)
输出 : 
3.) 直方图
直方图是一种绘图,可让您发现并显示一组连续数据的基本频率分布(形状)。这允许检查数据的潜在分布(例如,正态分布)、异常值、偏度等。
df1['A'].plot.hist(bins = 50)
输出 : 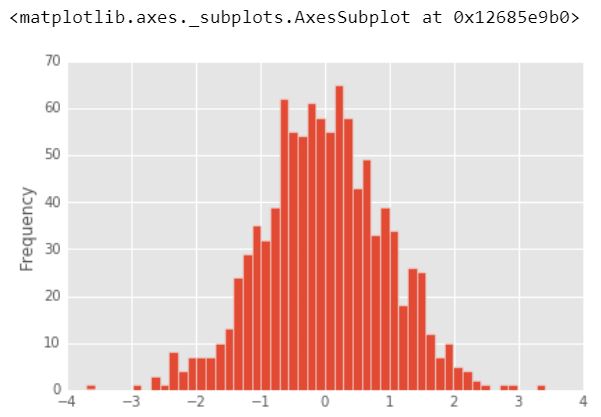
4.) 线图
折线图是显示沿数轴的数据频率的图形。当数据是时间序列时,最好使用折线图。这是一种快速、简单的数据组织方式。
df1.plot.line(x = df1.index, y ='B', figsize =(12, 3), lw = 1)
输出 : 
5.) 散点图
当您想要显示两个变量之间的关系时,可以使用散点图。散点图有时称为相关图,因为它们显示了两个变量如何相关。
df1.plot.scatter(x ='A', y ='B')
输出 : 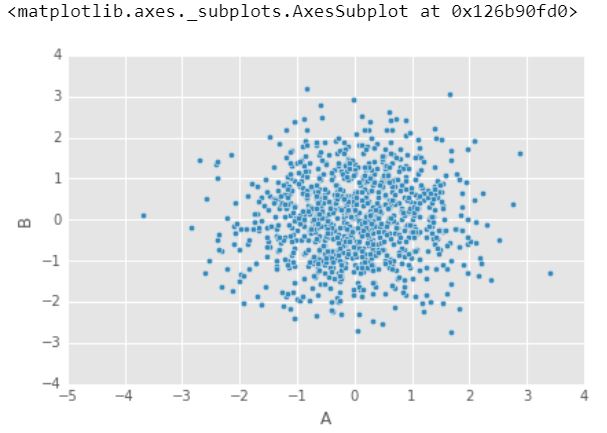
您可以使用 c 根据另一个列值着色 使用 cmap 指示要使用的颜色图。对于所有颜色图,请查看:http://matplotlib.org/users/colormaps.html
df1.plot.scatter(x ='A', y ='B', c ='C', cmap ='coolwarm')
输出 : 
或者使用 s 来指示基于另一列的大小。 s 参数需要是一个数组,而不仅仅是列名:
df1.plot.scatter(x ='A', y ='B', s = df1['C']*200)
输出 : 
6.) 箱线图
它是一个绘图,其中绘制了一个矩形来表示第二和第三个四分位数,通常在里面有一条垂直线来表示中值。下四分位数和上四分位数显示为矩形两侧的水平线。
箱线图是基于五个数字摘要(“最小值”、第一四分位数 (Q1)、中位数、第三四分位数 (Q3) 和“最大值”)显示数据分布的标准化方式。它可以告诉您异常值及其值是什么。它还可以告诉您数据是否对称、数据分组的紧密程度以及数据是否以及如何倾斜。
df2.plot.box() # Can also pass a by = argument for groupby
输出 : 
7.) 六角箱图
Hexagonal Binning 是另一种解决许多点开始重叠的问题的方法。六边形分箱绘制密度,而不是点。点被分箱成网格六边形,并使用六边形的颜色或面积显示分布(每个六边形的点数)。
对双变量数据有用,可替代散点图:
df = pd.DataFrame(np.random.randn(1000, 2), columns =['a', 'b'])
df.plot.hexbin(x ='a', y ='b', gridsize = 25, cmap ='Oranges')
输出 : 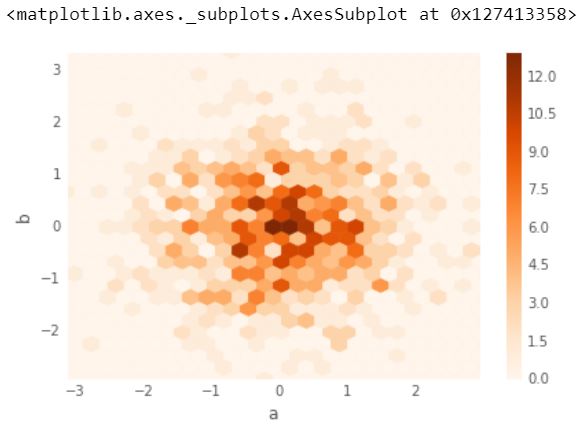
8.) 核密度估计图 (KDE)
KDE 是一种技术,可让您在给定一组数据的情况下创建平滑曲线。
如果您只想可视化某些数据的“形状”,这可能很有用,作为离散直方图的一种连续替换。它还可以用于生成看起来像是来自某个数据集的点——这种行为可以为简单的模拟提供动力,其中模拟对象是根据真实数据建模的。
df2['a'].plot.kde()
输出 : 
df2.plot.density()
输出 : 
就是这样!希望你能明白为什么这种绘图方法比完整的 matplotlib 更容易使用,它平衡了易用性和对图形的控制。许多绘图调用还接受其父 matplotlib plt 的附加参数。称呼。
在评论中写代码?请使用 ide.geeksforgeeks.org,生成链接并在此处分享链接。