Python PySpark – Union 和 UnionAll
在本文中,我们将讨论Python中 PySpark 中的 Union 和 UnionAll。
PySpark 中的联合
PySpark union()函数用于组合两个或多个具有相同结构或模式的数据帧。如果数据框的架构彼此不同,此函数将返回错误。
句法:
dataFrame1.union(dataFrame2)
Here,
- dataFrame1 and dataFrame2 are the dataframes
示例 1:
在此示例中,我们组合了两个数据帧 data_frame1 和 data_frame2。请注意,两个数据框的架构是相同的。
Python3
# Python program to illustrate the
# working of union() function
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('GeeksforGeeks.com').getOrCreate()
# Creating a dataframe
data_frame1 = spark.createDataFrame(
[("Bhuwanesh", 82.98), ("Harshit", 80.31)],
["Student Name", "Overall Percentage"]
)
# Creating another dataframe
data_frame2 = spark.createDataFrame(
[("Naveen", 91.123), ("Piyush", 90.51)],
["Student Name", "Overall Percentage"]
)
# union()
answer = data_frame1.union(data_frame2)
# Print the result of the union()
answer.show()Python3
# Python program to illustrate the
# working of union() function
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('GeeksforGeeks.com').getOrCreate()
# Creating a data frame
data_frame1 = spark.createDataFrame(
[("Bhuwanesh", 82.98), ("Harshit", 80.31)],
["Student Name", "Overall Percentage"]
)
# Creating another data frame
data_frame2 = spark.createDataFrame(
[(91.123, "Naveen"), (90.51, "Piyush"), (87.67, "Hitesh")],
["Overall Percentage", "Student Name"]
)
# Union both the dataframes using union() function
answer = data_frame1.union(data_frame2)
# Print the union of both the dataframes
answer.show()Python3
# Python program to illustrate the
# working of unionAll() function
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('GeeksforGeeks.com').getOrCreate()
# Creating a dataframe
data_frame1 = spark.createDataFrame(
[("Bhuwanesh", 82.98), ("Harshit", 80.31)],
["Student Name", "Overall Percentage"]
)
# Creating another dataframe
data_frame2 = spark.createDataFrame(
[("Naveen", 91.123), ("Piyush", 90.51)],
["Student Name", "Overall Percentage"]
)
# Union both the dataframes using unionAll() function
answer = data_frame1.unionAll(data_frame2)
# Print the union of both the dataframes
answer.show()Python3
# Python program to illustrate the
# working of union() function
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('GeeksforGeeks.com').getOrCreate()
# Creating a data frame
data_frame1 = spark.createDataFrame(
[("Bhuwanesh", 82.98), ("Harshit", 80.31)],
["Student Name", "Overall Percentage"]
)
# Creating another data frame
data_frame2 = spark.createDataFrame(
[(91.123, "Naveen"), (90.51, "Piyush"), (87.67, "Hitesh")],
["Overall Percentage", "Student Name"]
)
# Union both the dataframes using unionAll() function
answer = data_frame1.unionAll(data_frame2)
# Print the union of both the dataframes
answer.show()输出:

示例 2:
在此示例中,我们组合了两个数据帧 data_frame1 和 data_frame2。请注意,两个数据框的架构是不同的。因此,输出不是所需的,因为 union()函数非常适合具有相同结构或模式的数据集。
Python3
# Python program to illustrate the
# working of union() function
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('GeeksforGeeks.com').getOrCreate()
# Creating a data frame
data_frame1 = spark.createDataFrame(
[("Bhuwanesh", 82.98), ("Harshit", 80.31)],
["Student Name", "Overall Percentage"]
)
# Creating another data frame
data_frame2 = spark.createDataFrame(
[(91.123, "Naveen"), (90.51, "Piyush"), (87.67, "Hitesh")],
["Overall Percentage", "Student Name"]
)
# Union both the dataframes using union() function
answer = data_frame1.union(data_frame2)
# Print the union of both the dataframes
answer.show()
输出:

PySpark 中的 UnionAll()
UnionAll()函数与 union()函数执行相同的任务,但此函数自 Spark “2.0.0” 版本以来已弃用。因此,建议使用 union()函数。
Syntax:
dataFrame1.unionAll(dataFrame2)
Here,
- dataFrame1 and dataFrame2 are the dataframes
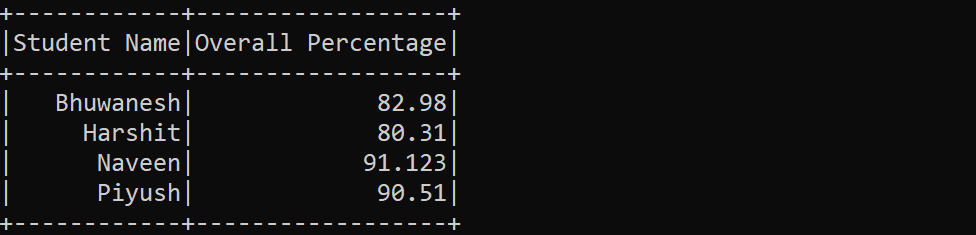
示例 1:
在此示例中,我们组合了两个数据帧 data_frame1 和 data_frame2。请注意,两个数据框的架构是相同的。
Python3
# Python program to illustrate the
# working of unionAll() function
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('GeeksforGeeks.com').getOrCreate()
# Creating a dataframe
data_frame1 = spark.createDataFrame(
[("Bhuwanesh", 82.98), ("Harshit", 80.31)],
["Student Name", "Overall Percentage"]
)
# Creating another dataframe
data_frame2 = spark.createDataFrame(
[("Naveen", 91.123), ("Piyush", 90.51)],
["Student Name", "Overall Percentage"]
)
# Union both the dataframes using unionAll() function
answer = data_frame1.unionAll(data_frame2)
# Print the union of both the dataframes
answer.show()
输出:
示例 2:
在此示例中,我们组合了两个数据帧 data_frame1 和 data_frame2。请注意,两个数据框的架构是不同的。因此,输出不是所需的,因为 unionAll()函数非常适合具有相同结构或模式的数据集。
Python3
# Python program to illustrate the
# working of union() function
import pyspark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('GeeksforGeeks.com').getOrCreate()
# Creating a data frame
data_frame1 = spark.createDataFrame(
[("Bhuwanesh", 82.98), ("Harshit", 80.31)],
["Student Name", "Overall Percentage"]
)
# Creating another data frame
data_frame2 = spark.createDataFrame(
[(91.123, "Naveen"), (90.51, "Piyush"), (87.67, "Hitesh")],
["Overall Percentage", "Student Name"]
)
# Union both the dataframes using unionAll() function
answer = data_frame1.unionAll(data_frame2)
# Print the union of both the dataframes
answer.show()
输出:
