- pandas.core.series.series 到数据框 - Python (1)
- pandas.core.series.series 到数据框 - Python 代码示例
- Python Pandas Series
- Python Pandas Series(1)
- series.Series 到数据框 - Python 代码示例
- 创建Pandas Series
- 创建Pandas Series(1)
- 如何在Python中使用 Pandas 将元数据添加到 DataFrame 或 Series?(1)
- 如何在Python中使用 Pandas 将元数据添加到 DataFrame 或 Series?
- Pandas Series.map()
- Pandas Series.map()(1)
- Pandas Series.std()(1)
- Pandas Series.std()
- 访问Pandas Series的元素(1)
- 访问Pandas Series的元素
- 更改列或 Pandas Series 的数据类型(1)
- 更改列或 Pandas Series 的数据类型
- Pandas Series.unique()(1)
- Pandas Series.unique()
- pandas.core.frame.DataFrame 到 pandas.core.series.Series - Python (1)
- pandas.core.frame.DataFrame 到 pandas.core.series.Series - Python 代码示例
- pandas 子数据框 - Python (1)
- Python| Pandas Series.plot() 方法
- Python| Pandas Series.from_csv()(1)
- Python| Pandas Series.from_csv()
- Python| Pandas Series.argsort()
- Python| Pandas Series.argsort()(1)
- Python| Pandas Series.argsort()
- Python| Pandas Series.argsort()(1)
📅 最后修改于: 2020-04-21 12:33:26 🧑 作者: Mango
Pandas Series是一维标记数组,能够保存任何类型的数据(整数,字符串,浮点数,Python对象等)。轴标签统称为index。Pandas Series不过是Excel工作表中的一列。标签不必是唯一的,但必须是可哈希的类型。该对象同时支持基于整数和基于标签的索引,并提供了许多用于执行涉及索引的操作的方法。


在本文中,我们正在使用nba.csv文件。
创建Pandas Series
在现实世界中,将通过从现有存储中加载数据集来创建Pandas Series,存储可以是SQL数据库,CSV文件和Excel文件。可以从列表,字典和标量值等创建Pandas Series。可以用不同的方式创建Series,以下是我们创建Series的一些方法:
从数组创建序列:为了从数组创建序列,我们必须导入numpy模块并必须使用array()函数。
# 导入pandas
import pandas as pd
# 导入numpy
import numpy as np
# 简单数组
data = np.array(['g','e','e','k','s'])
ser = pd.Series(data)
print(ser)输出:


从列表创建Series:
为了从列表创建Series,我们必须首先创建一个列表,然后才能从列表创建Series。
import pandas as pd
# 一个简单的list
list = ['g', 'e', 'e', 'k', 's']
# 从列表创建Series
ser = pd.Series(list)
print(ser)输出:
Series的元素访问
我们可以通过两种方式访问Series元素,它们是:
- 从具有位置的Series访问元素
- 使用标签访问元素(索引)
从具有位置的Series访问元素:为了访问Series元素,请引用索引号。使用索引运算符[]访问序列中的元素。索引必须是整数。为了访问序列中的多个元素,我们使用切片操作。
访问Series的前5个元素
# 导入模块
import pandas as pd
import numpy as np
# 创建简单的数组
data = np.array(['g','e','e','k','s','f', 'o','r','g','e','e','k','s'])
ser = pd.Series(data)
# 检索第一个元素
print(ser[:5])输出:

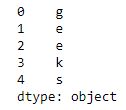
使用标签(索引)访问元素:
为了访问Series中的元素,我们必须通过索引标签设置值。Series就像固定大小的字典一样,可以通过索引标签获取和设置值。
使用索引标签访问单个元素:
# 导入模块
import pandas as pd
import numpy as np
# 创建简单的数组
data = np.array(['g','e','e','k','s','f', 'o','r','g','e','e','k','s'])
ser = pd.Series(data,index=[10,11,12,13,14,15,16,17,18,19,20,21,22])
# 使用索引元素访问元素
print(ser[16])输出:
Ø
串联索引和选择数据
在Pandas中建立索引意味着仅从Series中选择特定数据。索引可能意味着选择所有数据,某些数据来自特定的列。索引也称为子集选择。
使用索引运算符对Series进行索引[]:
索引运算符用于引用对象后面的方括号。该.loc和.iloc索引也使用索引操作符来进行选择。在此索引运算符中引用df []。
# 导入pandas
import pandas as pd
# 制作数据框
df = pd.read_csv("nba.csv")
ser = pd.Series(df['Name'])
data = ser.head(10)
data
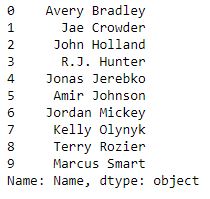
现在,我们使用索引运算符[]访问series的元素。
# using indexing operator
data[3:6]输出:


使用.loc[ ]方法索引Series:
此函数通过引用显式索引来选择数据。该df.loc索引中选择不仅仅是索引操作方式不同的数据。它可以选择数据子集。
# 导入pandas
import pandas as pd
# 制作数据框
df = pd.read_csv("nba.csv")
ser = pd.Series(df['Name'])
data = ser.head(10)
data
现在我们使用.loc[]函数访问Series的元素。
# 使用.loc []函数
data.loc[3:6]输出:


使用.iloc[ ]:索引Series。
此函数使我们可以按位置检索数据。为此,我们需要指定所需数据的位置。该df.iloc索引非常相似df.loc,但只使用整数位置做出选择。
# 导入pandas
import pandas as pd
# 制作数据框
df = pd.read_csv("nba.csv")
ser = pd.Series(df['Name'])
data = ser.head(10)
data
现在,我们使用.iloc[]函数访问Series的元素。
# 使用.iloc []函数
data.iloc[3:6]输出:
Series上的二进制运算
我们可以对Series执行二进制运算,例如加法,减法和许多其他运算。为了对Series执行二进制操作,我们必须使用一些函数,例如.add(),.sub()等等。
代码#1:
# 导入pandas
import pandas as pd
# 创建一个series
data = pd.Series([5, 2, 3,7], index=['a', 'b', 'c', 'd'])
# 创建一个series
data1 = pd.Series([1, 6, 4, 9], index=['a', 'b', 'd', 'e'])
print(data, "\n\n", data1) 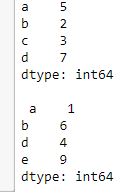

现在我们使用.add()函数添加两个Series。
# 使用.add添加两个系列
data.add(data1, fill_value=0) 输出:


代码#2:
# 导入pandas
import pandas as pd
# 创建一个series
data = pd.Series([5, 2, 3,7], index=['a', 'b', 'c', 'd'])
# 创建一个series
data1 = pd.Series([1, 6, 4, 9], index=['a', 'b', 'd', 'e'])
print(data, "\n\n", data1)
现在我们使用.sub函数减去两个序列。
# 用.sub减去两个序列
data.sub(data1, fill_value=0)输出:


Series转换操作
我们执行各种操作如改变一Series的数据类型,改变一个Series列表等。为了进行转换操作,我们有不同的函数,帮助像转换.astype(),.tolist()等等
代码#1:
# Python程序使用astype转换Series的数据类型
# 导入pandas
import pandas as pd
# 从网址读取csv文件
data = pd.read_csv("nba.csv")
# 删除空值列以避免错误
data.dropna(inplace = True)
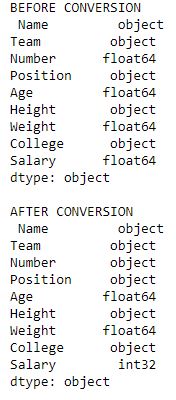
# 转换前存储dtype
before = data.dtypes
# 使用astype转换dtype
data["Salary"]= data["Salary"].astype(int)
data["Number"]= data["Number"].astype(str)
# 转换后存储dtype
after = data.dtypes
# 打印
print("BEFORE CONVERSION\n", before, "\n")
print("AFTER CONVERSION\n", after, "\n")
输出:

代码#2:
# Python程序将Series转换为列表
# 导入pandas
import pandas as pd
# 导入正则表达式模块
import re
# 制作数据框
data = pd.read_csv("nba.csv")
# 删除空值以避免错误
data.dropna(inplace = True)
# 在操作前存储dtype
dtype_before = type(data["Salary"])
# 转换成list
salary_list = data["Salary"].tolist()
# 操作后存储dtype
dtype_after = type(salary_list)
# 打印dtype
print("Data type before converting = {}\nData type after converting = {}"
.format(dtype_before, dtype_after))
# displaying list
salary_list

| 函数 | 描述 |
|---|---|
| add() | 方法用于将Series或长度相同的对象列表添加到调用者Series中 |
| sub() | 方法用于从调用者序列中减去序列或列出长度相同的类似对象 |
| mul() | 方法用于乘以Series或列出与调用者Series长度相同的对象 |
| div() | 方法用于按调用者序列划分序列或列出具有相同长度的类似对象 |
| sum() | 返回所请求轴的值之和 |
| prod() | 返回所请求轴的值的乘积 |
| mean() | 返回所请求轴的平均值 |
| pow() | 方法用于将传递的序列的每个元素作为调用者序列的指数幂,并返回结果 |
| abs() | 方法用于获取Series / DataFrame中每个元素的绝对数值 |
| cov() | 方法用于找到两个序列的协方差 |
Pandas Series方法:
| 函数 | 描述 |
|---|---|
| Series() | 可以使用Series()构造函数方法创建一个PandasSeries。此构造方法接受各种输入 |
| Combine_first() | 方法用于将两个Series合并为一个 |
| count() | 返回序列中非NA /空观测值的数量 |
| size() | 返回基础数据中的元素数 |
| name() | 方法允许为Series对象(即列)命名 |
| is_unique() | 如果对象中的值唯一,则方法返回布尔值 |
| idxmax() | 提取序列中最大值的索引位置的方法 |
| idxmin() | 提取序列中最小值的索引位置的方法 |
| sort_values() | 在Series上调用方法以按升序或降序对值进行排序 |
| sort_index() | 在Pandas Series上调用Method以按索引而不是其值对它进行排序 |
| head() | 方法用于从Series的开头返回指定的行数。该方法返回一个全新的Series |
| tail() | 方法用于从Series的结尾返回指定的行数。该方法返回一个全新的Series |
| le() | 用于比较CallerSeries和传递Series中的每个元素,对于小于或等于传递Series中的每个元素返回True |
| ne() | 用于将CallerSeries的每个元素与传递的Series进行比较。对于每个不等于传递的序列中的元素的元素,它返回True |
| ge() | 用于将CallerSeries的每个元素与传递的Series进行比较。对于大于或等于所传递Series中的每个元素,它将返回True |
| eq() | 用于将CallerSeries的每个元素与传递的Series进行比较。对于与传递的序列中的元素相等的每个元素,它返回True |
| gt() | 用于比较两个Series,并为每个元素返回布尔值 |
| lt() | 用于比较两个Series,并为每个元素返回布尔值 |
| clip() | 用于裁剪上下的值以传递最小和最大值 |
| clip_lower() | 用于将值裁剪为低于传递的最小值 |
| clip_upper() | 用于裁剪超过传递的最大值的值 |
| astype() | 方法用于更改Series的数据类型 |
| tolist() | 方法用于将Series转换为列表 |
| get() | 在Series上调用Method以从Series提取值。这是传统括号语法的替代语法 |
| unique() | Pandas的unique()用于查看特定列中的唯一值 |
| nunique() | Pandasnunique()用于获取唯一值的计数 |
| value_counts() | 计算Series中每个唯一值出现次数的方法 |
| factorize() | 方法通过标识不同的值来帮助获得数组的数字表示形式 |
| map() | 将值从一个对象绑定到另一个的方法 |
| between() | 在Series上使用Pandas between()方法检查哪些值位于第一个参数和第二个参数之间 |
| apply() | 方法被调用并作为一个参数提供给Python函数,以在每个Series值上使用该函数。此方法对于执行未包含在pandas或numpy中的自定义操作很有帮助 |