- Pandas 中的 join 和 merge 有什么区别?
- Pandas 中的 join 和 merge 有什么区别?(1)
- Pandas merge()(1)
- Pandas merge()
- 合并联接算法(1)
- 合并联接算法
- Python中的 pandas.concat()函数
- Python中的 pandas.concat()函数(1)
- 哈希联接和排序合并联接之间的区别
- 哈希联接和排序合并联接之间的区别(1)
- Hash Join 和 Sort Merge Join 的区别(1)
- Hash Join 和 Sort Merge Join 的区别
- Hash Join 和 Sort Merge Join 的区别
- 嵌套循环联接和排序合并联接之间的区别
- 嵌套循环联接和排序合并联接之间的区别(1)
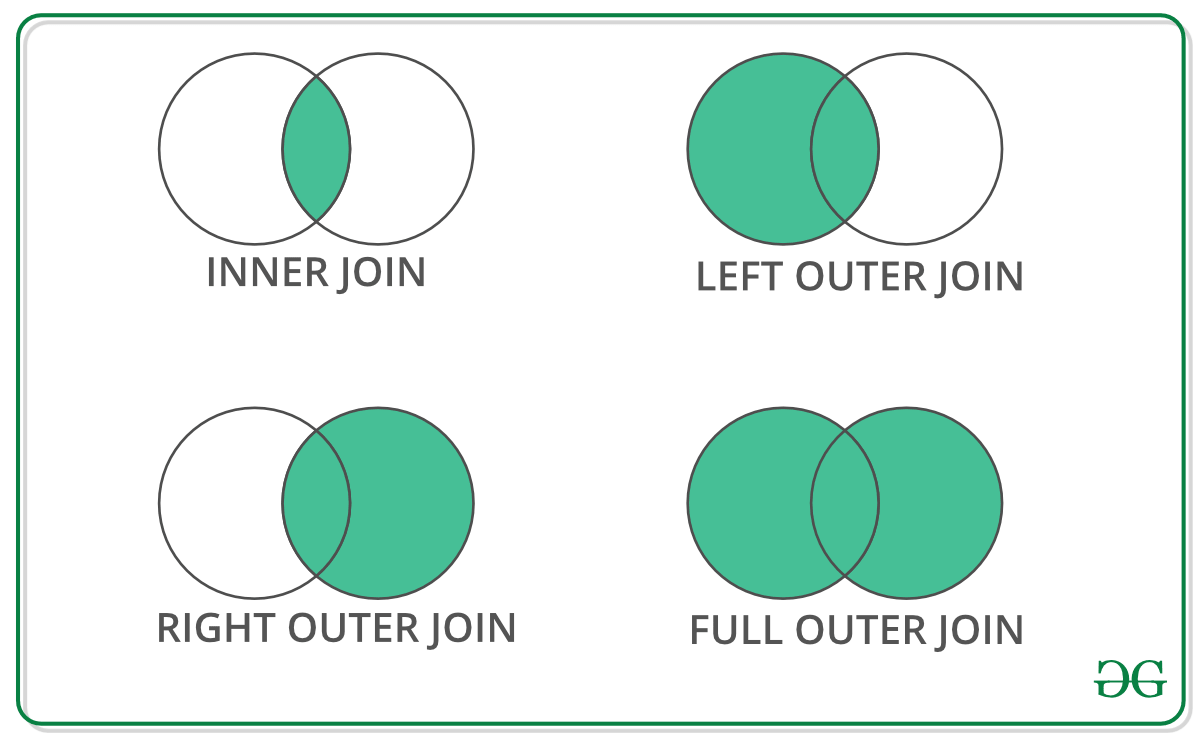
- SQL |联接(内联接、左联接、右联接和完全联接)(1)
- SQL |联接(内联接、左联接、右联接和完全联接)
- Pandas 数据concat
- Pandas 数据concat(1)
- pandas concat 在一个数据帧中合并两个数据帧 - Python (1)
- 在 Julia 中合并字典集合——merge() 和 merge!() 方法(1)
- 在 Julia 中合并字典集合——merge() 和 merge!() 方法
- pandas concat 在一个数据帧中合并两个数据帧 - Python 代码示例
- pandas merge df - Python (1)
- SQL |联接(内部联接,左侧联接,右侧联接和完全联接)(1)
- SQL |联接(内部联接,左侧联接,右侧联接和完全联接)
- 左联接和右联接之间的区别
- Python中的join
- Python中的join(1)
📅 最后修改于: 2020-04-21 12:11:20 🧑 作者: Mango
Pandas DataFrame是带有标签轴(行和列)的二维大小可变的,可能是异构的表格数据结构。数据框是二维数据结构,即,数据以表格形式在行和列中对齐。我们可以使用不同的方法来联接,合并和合并数据框。在Dataframe df.merge()中df.join(),和df.concat()方法有助于连接,合并和缩编不同的数据框。

串联concat DataFrame
为了连接数据框,我们使用concat()有助于连接数据框的函数。我们可以用许多不同的方式连接数据框,它们是:
- 连接DataFrame
.concat() - 通过设置轴上的逻辑来连接DataFrame
- 使用连接DataFrame
.append() - 通过忽略索引来连接DataFrame
- 将DataFrame与组密钥连接
- 与混合ndims串联
使用.concat()以下方式连接DataFrame :
为了连接一个数据帧,我们使用.concat(),此函数连接一个数据帧并返回一个新的数据帧。
# 导入pandas
import pandas as pd
# 定义包含员工数据的字典
data1 = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'],
'Age':[27, 24, 22, 32],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd']}
# 定义包含员工数据的字典
data2 = {'Name':['Abhi', 'Ayushi', 'Dhiraj', 'Hitesh'],
'Age':[17, 14, 12, 52],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'],
'Qualification':['Btech', 'B.A', 'Bcom', 'B.hons']}
# 将字典转换为DataFrame
df = pd.DataFrame(data1,index=[0, 1, 2, 3])
# 将字典转换为DataFrame
df1 = pd.DataFrame(data2, index=[4, 5, 6, 7])
print(df, "\n\n", df1)现在我们应用 .concat函数以连接两个数据帧
# 使用.concat()方法
frames = [df, df1]
res1 = pd.concat(frames)
res1输出:
如输出图像中所示,我们在级联后创建了一个数据框,从而创建了两个数据框。通过在轴上设置逻辑来连接数据框:
为了合并数据框,我们必须在轴上设置不同的逻辑。我们可以通过以下三种方式设置轴:
- 把它们全部结合起来
join='outer'。这是默认选项,因为它导致信息丢失为零。 - 以十字路口,
join='inner'。 - 使用传递给
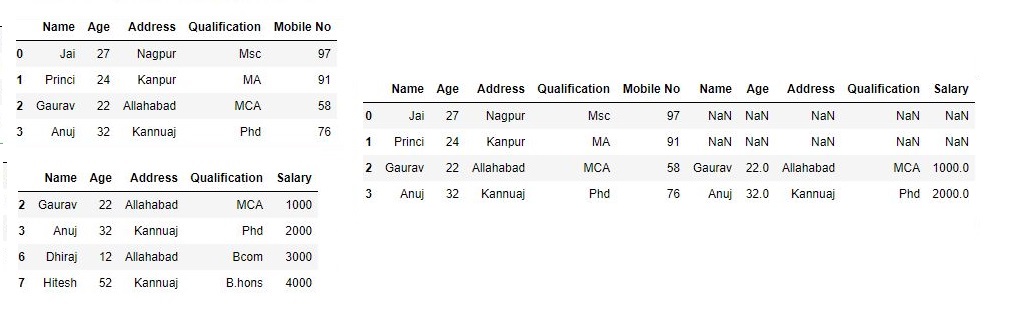
join_axes参数的特定索引# 导入pandas import pandas as pd # 定义包含员工数据的字典 data1 = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32], 'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification':['Msc', 'MA', 'MCA', 'Phd'], 'Mobile No': [97, 91, 58, 76]} # 定义包含员工数据的字典 data2 = {'Name':['Gaurav', 'Anuj', 'Dhiraj', 'Hitesh'], 'Age':[22, 32, 12, 52], 'Address':['Allahabad', 'Kannuaj', 'Allahabad', 'Kannuaj'], 'Qualification':['MCA', 'Phd', 'Bcom', 'B.hons'], 'Salary':[1000, 2000, 3000, 4000]} # 将字典转换为DataFrame df = pd.DataFrame(data1,index=[0, 1, 2, 3]) # 将字典转换为DataFrame df1 = pd.DataFrame(data2, index=[2, 3, 6, 7]) print(df, "\n\n", df1)现在我们设置
join = inner数据框相交的轴# 用轴应用concat # join = 'inner' res2 = pd.concat([df, df1], axis=1, join='inner') res2输出:
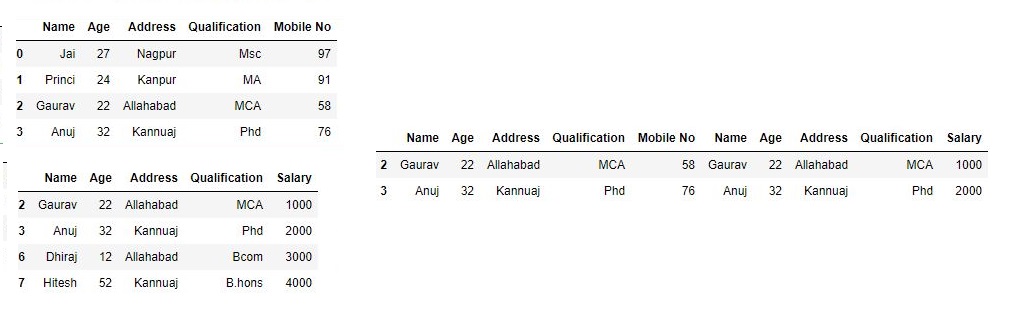
如输出图像所示,我们得到数据框的交集。

现在,我们设置数据框并集的轴join = outer。# 使用.concat进行数据帧的联合 res2 = pd.concat([df, df1], axis=1, sort=False) res2输出:
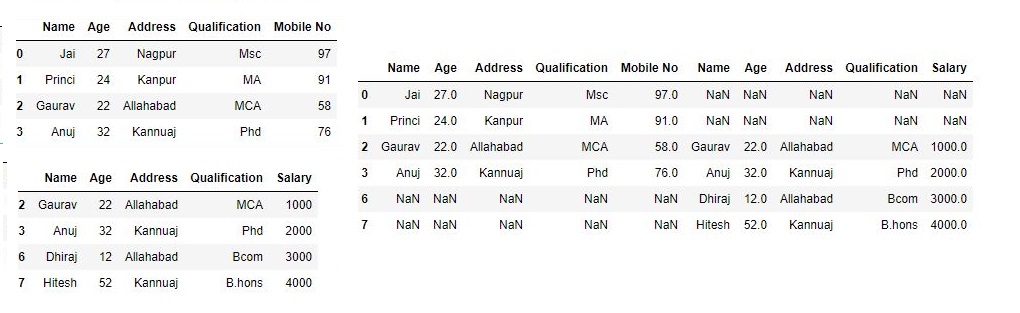
如输出图像所示,我们获得数据帧的并集

- 现在我们使用特定的索引,并将其传递给
join_axes参数# 使用join_axes res3 = pd.concat([df, df1], axis=1, join_axes=[df.index]) res3输出:

使用连接.append()
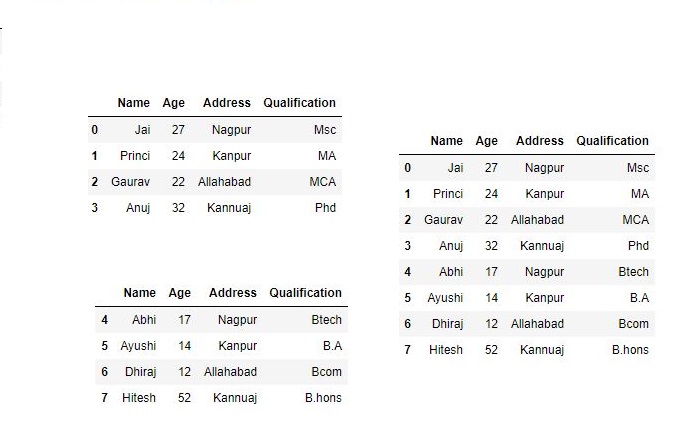
数据帧为了连接数据帧,我们使用.append()此函数沿axis = 0进行连接,即索引。此功能之前存在.concat。# 导入pandas import pandas as pd # 定义包含员工数据的字典 data1 = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32], 'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification':['Msc', 'MA', 'MCA', 'Phd']} # 定义包含员工数据的字典 data2 = {'Name':['Abhi', 'Ayushi', 'Dhiraj', 'Hitesh'], 'Age':[17, 14, 12, 52], 'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification':['Btech', 'B.A', 'Bcom', 'B.hons']} # 将字典转换为DataFrame df = pd.DataFrame(data1,index=[0, 1, 2, 3]) # 将字典转换为DataFrame df1 = pd.DataFrame(data2, index=[4, 5, 6, 7]) print(df, "\n\n", df1)现在我们应用
.append()函数以便连接到数据框# 使用append res = df.append(df1) res输出:

通过忽略索引来连接DataFrame:
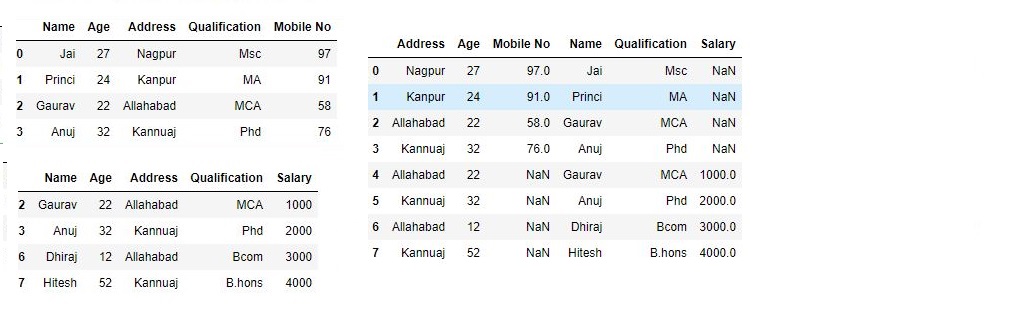
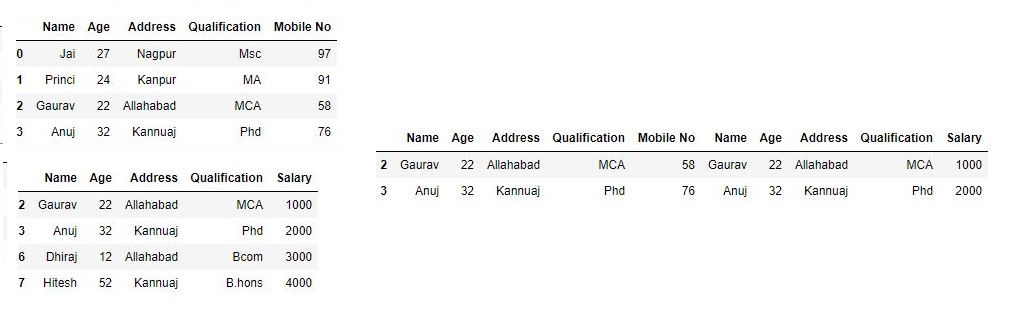
为了通过忽略索引来连接数据帧,我们忽略了没有有意义的索引,您可能希望附加它们并忽略它们可能具有重叠索引的事实。为此,我们使用它ignore_index作为参数:# 导入pandas import pandas as pd # 定义包含员工数据的字典 data1 = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32], 'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification':['Msc', 'MA', 'MCA', 'Phd'], 'Mobile No': [97, 91, 58, 76]} # 定义包含员工数据的字典 data2 = {'Name':['Gaurav', 'Anuj', 'Dhiraj', 'Hitesh'], 'Age':[22, 32, 12, 52], 'Address':['Allahabad', 'Kannuaj', 'Allahabad', 'Kannuaj'], 'Qualification':['MCA', 'Phd', 'Bcom', 'B.hons'], 'Salary':[1000, 2000, 3000, 4000]} # 将字典转换为DataFrame df = pd.DataFrame(data1,index=[0, 1, 2, 3]) # 将字典转换为DataFrame df1 = pd.DataFrame(data2, index=[2, 3, 6, 7]) print(df, "\n\n", df1)现在我们将应用
ignore_index为论证。# 使用ignore_index res = pd.concat([df, df1], ignore_index=True) res输出:

DataFrame与组键连接:
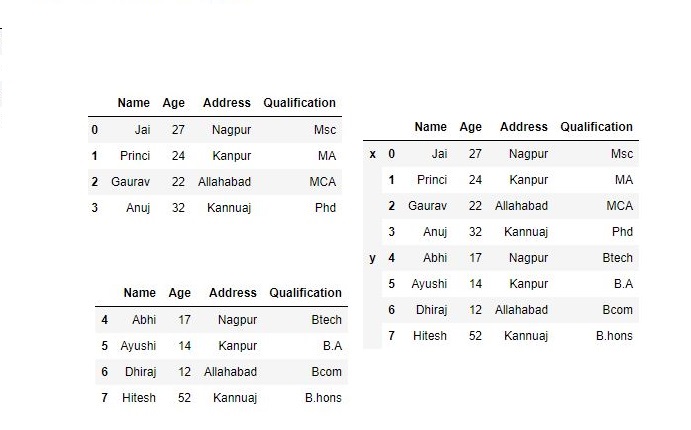
为了将数据框与组键连接,我们使用keys参数覆盖列名。Keys参数用于在基于现有Series创建新的DataFrame时覆盖列名称。# 导入pandas import pandas as pd # 定义包含员工数据的字典 data1 = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32], 'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification':['Msc', 'MA', 'MCA', 'Phd']} # 定义包含员工数据的字典 data2 = {'Name':['Abhi', 'Ayushi', 'Dhiraj', 'Hitesh'], 'Age':[17, 14, 12, 52], 'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification':['Btech', 'B.A', 'Bcom', 'B.hons']} # 将字典转换为DataFrame df = pd.DataFrame(data1,index=[0, 1, 2, 3]) # 将字典转换为DataFrame df1 = pd.DataFrame(data2, index=[4, 5, 6, 7]) print(df, "\n\n", df1)现在,我们使用键作为参数。
# 使用keys frames = [df, df1 ] res = pd.concat(frames, keys=['x', 'y']) res输出:

用混合的ndims串联:
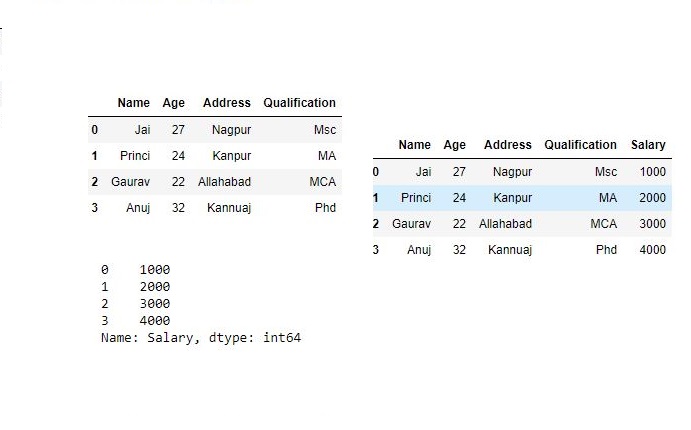
用户可以串联Series和DataFrame的混合。Series将以列名作为Series的名称转换为DataFrame。# 导入pandas import pandas as pd # 定义包含员工数据的字典 data1 = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32], 'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification':['Msc', 'MA', 'MCA', 'Phd']} # 将字典转换为DataFrame df = pd.DataFrame(data1,index=[0, 1, 2, 3]) # 创建一个Series s1 = pd.Series([1000, 2000, 3000, 4000], name='Salary') print(df, "\n\n", s1)现在我们将系列和数据框混合在一起
# 结合Series和数据框 res = pd.concat([df, s1], axis=1) res输出:

合并DataFrame
pandas可以选择高性能的内存合并和连接。当我们需要组合非常大的DataFrame时,联接joins是快速执行这些操作的有力方法。一次只能在两个DataFrame上进行联接,分别表示为左表和右表。关键是将两个DataFrame连接在一起的公共列。最好使用在整个列中具有唯一值的键,以避免行值的意外复制。pandas提供了一个单一的merge()函数,作为DataFrame对象之间所有标准数据库联接操作的入口点。有四种处理联接的基本方法(内部,左侧,右侧和外部),具体取决于哪些行必须保留其数据。

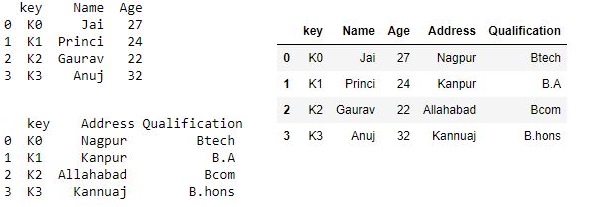
代码1:使用一个唯一的组合键合并一个数据框# 导入pandas import pandas as pd # 定义包含员工数据的字典 data1 = {'key': ['K0', 'K1', 'K2', 'K3'], 'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32],} # 定义包含员工数据的字典 data2 = {'key': ['K0', 'K1', 'K2', 'K3'], 'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification':['Btech', 'B.A', 'Bcom', 'B.hons']} # 将字典转换为DataFrame df = pd.DataFrame(data1) # 将字典转换为DataFrame df1 = pd.DataFrame(data2) print(df, "\n\n", df1)现在我们使用
.merge()一种独特的组合键# 使用.merge()函数 res = pd.merge(df, df1, on='key') res输出:

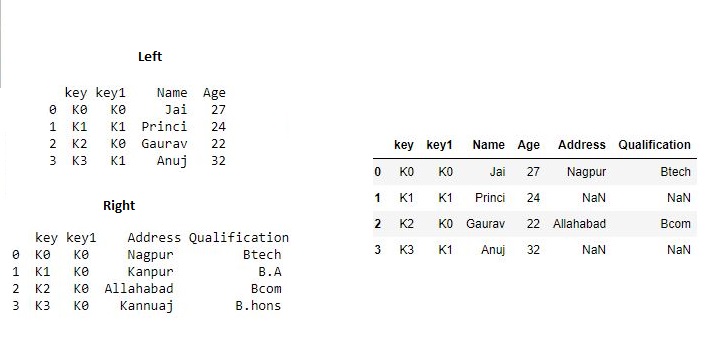
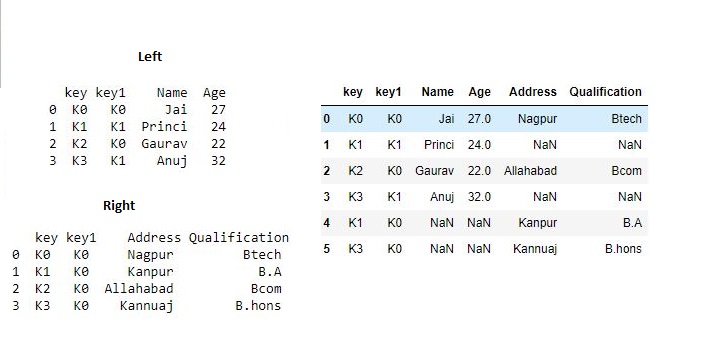
代码2:使用多个联接键合并数据帧。# 导入pandas import pandas as pd # 定义包含员工数据的字典 data1 = {'key': ['K0', 'K1', 'K2', 'K3'], 'key1': ['K0', 'K1', 'K0', 'K1'], 'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32],} # 定义包含员工数据的字典 data2 = {'key': ['K0', 'K1', 'K2', 'K3'], 'key1': ['K0', 'K0', 'K0', 'K0'], 'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification':['Btech', 'B.A', 'Bcom', 'B.hons']} # 将字典转换为DataFrame df = pd.DataFrame(data1) # 将字典转换为DataFrame df1 = pd.DataFrame(data2) print(df, "\n\n", df1)现在我们使用多个键合并数据框
# 使用多个键合并数据框 res1 = pd.merge(df, df1, on=['key', 'key1']) res1输出:


如何使用合并数据帧:
我们使用How参数进行合并,以指定如何确定要在结果表中包含哪些键。如果左侧或右侧表中均未出现组合键,则联接表中的值为NA。以下是选项及其SQL等效名称的方式的摘要:合并方式 合并名称 描述 left 左外连接 仅使用左框中的键 right 右外连接 仅从右框使用键 outer 全外连接 使用两个框架中的键并集 inner 内部联接 使用两个帧的键交集 # 导入pandas import pandas as pd # 定义包含员工数据的字典 data1 = {'key': ['K0', 'K1', 'K2', 'K3'], 'key1': ['K0', 'K1', 'K0', 'K1'], 'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32],} # 定义包含员工数据的字典 data2 = {'key': ['K0', 'K1', 'K2', 'K3'], 'key1': ['K0', 'K0', 'K0', 'K0'], 'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'], 'Qualification':['Btech', 'B.A', 'Bcom', 'B.hons']} # 将字典转换为DataFrame df = pd.DataFrame(data1) # 将字典转换为DataFrame df1 = pd.DataFrame(data2) print(df, "\n\n", df1)现在我们设置
how = 'left'为仅使用左框架中的键。# 使用左框中的关键点 res = pd.merge(df, df1, how='left', on=['key', 'key1']) res输出:

现在我们进行设置how = 'right'以仅使用右框架中的键。# 使用右框架中的键 res1 = pd.merge(df, df1, how='right', on=['key', 'key1']) res1输出:
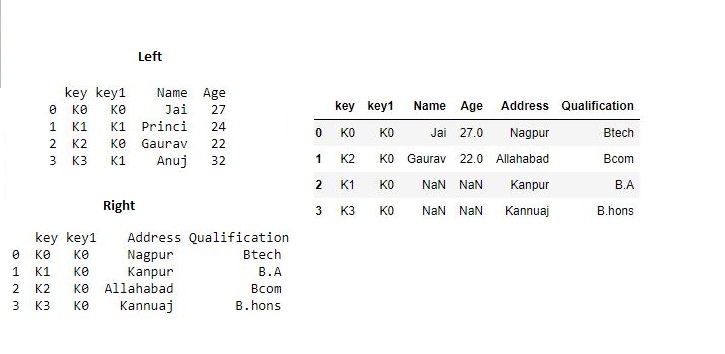

现在我们进行设置how = 'outer'以便从数据帧中获取键的并集。# 得到keys的联合 res2 = pd.merge(df, df1, how='outer', on=['key', 'key1']) res2输出:

现在我们进行设置how = 'inner'以便从数据帧中获取关键点的交集。# 得到keys的交集 res3 = pd.merge(df, df1, how='inner', on=['key', 'key1']) res3输出:


Join DataFrame
为了连接数据框,我们使用
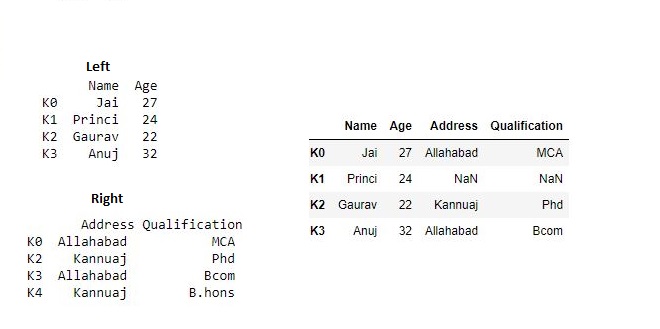
.join()函数。该函数用于将两个可能具有不同索引的数据框的列组合为单个结果数据框。# 导入pandas import pandas as pd # 定义包含员工数据的字典 data1 = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32]} # 定义包含员工数据的字典 data2 = {'Address':['Allahabad', 'Kannuaj', 'Allahabad', 'Kannuaj'], 'Qualification':['MCA', 'Phd', 'Bcom', 'B.hons']} # 将字典转换为DataFrame df = pd.DataFrame(data1,index=['K0', 'K1', 'K2', 'K3']) # 将字典转换为DataFrame df1 = pd.DataFrame(data2, index=['K0', 'K2', 'K3', 'K4']) print(df, "\n\n", df1)现在我们使用
.join()方法来加入数据框# joining dataframe res = df.join(df1) res输出:

现在我们how = 'outer'为了获得联合而使用# getting union res1 = df.join(df1, how='outer') res1输出:

使用on参数来join
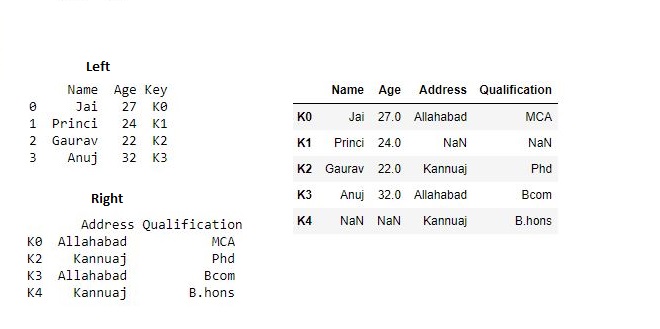
为了on在参数中使用来join数据框。join()采用一个可选的on参数,该参数可以是一列或多个列名,它指定传递的DataFrame将在该列上对齐。# 导入pandas import pandas as pd # 定义包含员工数据的字典 data1 = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32], 'Key':['K0', 'K1', 'K2', 'K3']} # 定义包含员工数据的字典 data2 = {'Address':['Allahabad', 'Kannuaj', 'Allahabad', 'Kannuaj'], 'Qualification':['MCA', 'Phd', 'Bcom', 'B.hons']} # 将字典转换为DataFrame df = pd.DataFrame(data1) # 将字典转换为DataFrame df1 = pd.DataFrame(data2, index=['K0', 'K2', 'K3', 'K4']) print(df, "\n\n", df1)现在我们使用
.join“ on”参数# 在连接中使用on参数 res2 = df.join(df1, on='Key') res2输出:
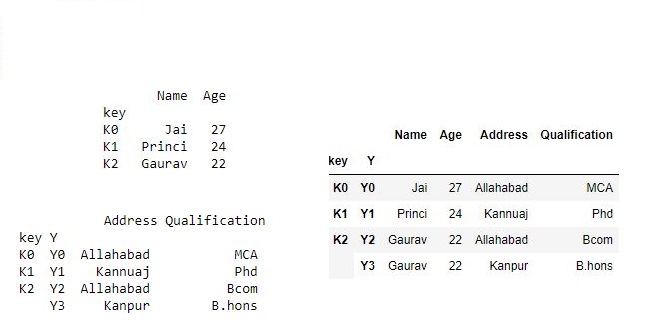
将单索引数据帧与多索引数据帧连接

为了将单索引数据帧与多索引数据帧连接,将在单索引帧的索引名称上与多索引数据集的名称相匹配索引。# 导入pandas import pandas as pd # 定义包含员工数据的字典 data1 = {'Name':['Jai', 'Princi', 'Gaurav'], 'Age':[27, 24, 22]} # 定义包含员工数据的字典 data2 = {'Address':['Allahabad', 'Kannuaj', 'Allahabad', 'Kanpur'], 'Qualification':['MCA', 'Phd', 'Bcom', 'B.hons']} # 将字典转换为DataFrame df = pd.DataFrame(data1, index=pd.Index(['K0', 'K1', 'K2'], name='key')) index = pd.MultiIndex.from_tuples([('K0', 'Y0'), ('K1', 'Y1'), ('K2', 'Y2'), ('K2', 'Y3')], names=['key', 'Y']) # 将字典转换为DataFrame df1 = pd.DataFrame(data2, index= index) print(df, "\n\n", df1)现在我们将单索引数据框与多索引数据框联接
# 用多索引连接单索引 result = df.join(df1, how='inner') result输出: