获取DataFrame列中最大值的索引
Pandas DataFrame 是具有标记轴(行和列)的二维大小可变、可能异构的表格数据结构。
让我们看看如何获取 DataFrame 列中最大值的索引。
首先观察这个数据集。我们将使用此数据的“体重”和“工资”列,以便从 Pandas DataFrame 中的特定列中获取最大值的索引。
Python3
# importing pandas module
import pandas as pd
# making data frame
df = pd.read_csv("https://media.geeksforgeeks.org/wp-content/uploads/nba.csv")
df.head(10)Python3
# importing pandas module
import pandas as pd
# making data frame
df = pd.read_csv("nba.csv")
# Returns index of maximum weight
df[['Weight']].idxmax()Python3
# importing pandas module
import pandas as pd
# making data frame
df = pd.read_csv("nba.csv")
# from index 400 to 409
df.iloc[400:410]Python3
# importing pandas module
import pandas as pd
# making data frame
df = pd.read_csv("nba.csv")
new_row = pd.DataFrame({'Name':'Geeks', 'Team':'Boston', 'Number':3,
'Position':'PG', 'Age':33, 'Height':'6-2',
'Weight':189, 'College':'MIT', 'Salary':999999999}
, index=[0])
df = pd.concat([new_row, df]).reset_index(drop=True)
df.head(5)Python3
# Returns index of minimum salary
df[['Salary']].idxmax()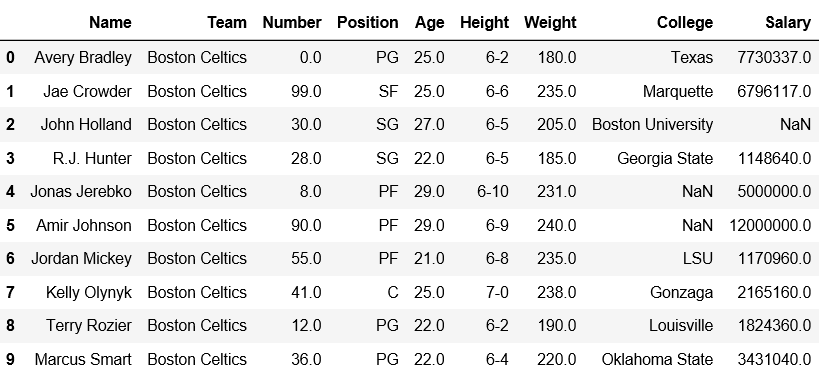
代码 #1:检查存在最大重量值的索引。
Python3
# importing pandas module
import pandas as pd
# making data frame
df = pd.read_csv("nba.csv")
# Returns index of maximum weight
df[['Weight']].idxmax()
输出:

我们可以验证最大值是否存在于索引中。
Python3
# importing pandas module
import pandas as pd
# making data frame
df = pd.read_csv("nba.csv")
# from index 400 to 409
df.iloc[400:410]
输出:

代码 #2:让我们在索引 0 处插入一个具有最高薪水的新行,然后进行验证。
Python3
# importing pandas module
import pandas as pd
# making data frame
df = pd.read_csv("nba.csv")
new_row = pd.DataFrame({'Name':'Geeks', 'Team':'Boston', 'Number':3,
'Position':'PG', 'Age':33, 'Height':'6-2',
'Weight':189, 'College':'MIT', 'Salary':999999999}
, index=[0])
df = pd.concat([new_row, df]).reset_index(drop=True)
df.head(5)
输出:

现在,让我们检查索引 0 处是否存在最高薪水。
Python3
# Returns index of minimum salary
df[['Salary']].idxmax()
输出:
