- Apache Kafka-集群体系结构
- Apache Kafka-集群体系结构(1)
- 安装Apache Kafka
- 安装Apache Kafka(1)
- Apache Kafka-应用程序(1)
- Apache Kafka应用程序(1)
- Apache Kafka-应用程序
- Apache Kafka应用程序
- Apache Kafka教程
- Apache Kafka教程(1)
- Apache Kafka教程
- Apache Kafka教程(1)
- Apache Kafka-简介
- Apache Kafka-工具
- Apache Kafka-工具(1)
- 讨论Apache Kafka
- 讨论Apache Kafka(1)
- Apache Kafka-基础(1)
- Apache Kafka-基础
- Apache Kafka与Apache Storm
- Apache Kafka与Apache Storm(1)
- Apache Kafka体系结构(1)
- Apache Kafka体系结构
- Apache Kafka-安装步骤
- Apache Kafka-安装步骤(1)
- 在macOS上安装Apache Kafka
- Apache Kafka 和 Apache Flume 的区别(1)
- Apache Kafka 和 Apache Flume 的区别
- Apache Kafka与RabbitMQ
📅 最后修改于: 2021-01-05 02:42:18 🧑 作者: Mango
Kafka:多个集群
我们已经研究过,单个Kafka群集中可以有多个分区,主题和代理。
因此,随着Apache Kafka部署的增长,拥有多个集群是有益的。在本节中,我们将讨论多个集群,其优势以及更多其他内容。
Kafka群集是由多个代理及其各自分区组成的群集。多个Kafka集群意味着连接两个或多个集群以简化生产者和消费者的工作。
多个集群的优势
单个Kafka集群足以满足本地开发需求。但是,拥有多个集群是有益的。有几个原因可以最好地描述多个集群的优势:
- 隔离数据类型
- 多个数据中心
- 隔离安全要求
隔离数据类型
使用多个群集允许用户在不同的代理下隔离不同类型的数据。这使得获取数据变得容易。而且,用户不需要在单个群集中过滤数据。
多个数据中心
建立多个数据中心的目的是保存灾难中的数据或消息。因此,这些数据中心需要在它们之间复制数据。如果发生任何灾难,例如系统崩溃或服务器崩溃,数据仍然可以恢复。而且,在线应用程序可以轻松访问两个站点上的用户活动。
隔离安全要求
安全是任何数据或消息的主要关注点。 Apache Kafka为存储的数据提供了各种安全措施。由于多个数据中心分别存储大量数据,因此安全要求也被隔离在不同的数据中心中。
镜匠
在Apache Kafka中,复制过程仅在群集内有效,而在多个群集之间无效。因此,Kafka项目引入了一个称为MirrorMaker的工具。 MirrorMaker是消费者和生产者的结合。两者都通过队列链接在一起。一个Kafka集群的生产者生成一条消息,而另一个集群的消费者读取该消息。
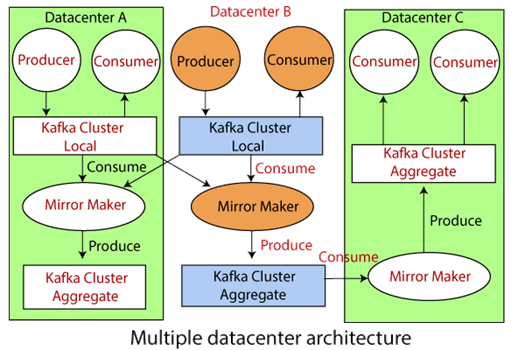
在上图中,来自两个本地数据中心的消息通过MirrorMaker聚集到一个群集中。然后将相应的集群复制到其他数据中心。
因此,为了管理大量数据和消息,MirrorMaker用于在各种Kafka群集之间复制数据。