📌 相关文章
- Apache Kafka-集群体系结构(1)
- Apache Kafka-集群体系结构
- 安装Apache Kafka(1)
- 安装Apache Kafka
- Apache Kafka应用程序
- Apache Kafka-应用程序
- Apache Kafka应用程序(1)
- Apache Kafka-应用程序(1)
- Apache Kafka教程
- Apache Kafka教程(1)
- Apache Kafka教程
- Apache Kafka教程(1)
- Apache Kafka-简介
- Apache Kafka-工具(1)
- Apache Kafka-工具
- 讨论Apache Kafka
- 讨论Apache Kafka(1)
- Apache Kafka-基础
- Apache Kafka-基础(1)
- Apache Kafka与Apache Storm
- Apache Kafka与Apache Storm(1)
- Apache Kafka-安装步骤(1)
- Apache Kafka-安装步骤
- 在macOS上安装Apache Kafka
- Apache Kafka 和 Apache Flume 的区别
- Apache Kafka 和 Apache Flume 的区别(1)
- Apache Pig-体系结构
- Apache Pig-体系结构(1)
- Apache Kafka与RabbitMQ(1)
📜 Apache Kafka体系结构
📅 最后修改于: 2021-01-05 02:43:13 🧑 作者: Mango
Apache Kafka体系结构
我们已经学习了Apache Kafka的基本概念。这些基本概念,例如主题,分区,生产者,消费者等,共同构成了Kafka体系结构。
由于不同的应用程序相应地设计了Kafka的体系结构,因此设计Apache Kafka体系结构需要以下基本部分。
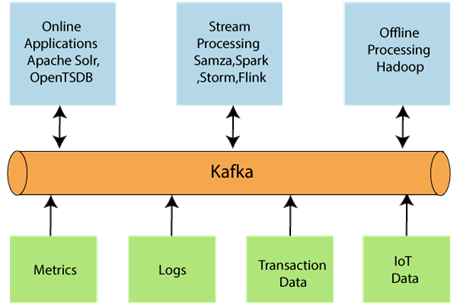
- 数据生态系统:使用Apache Kafka的多个应用程序构成了一个生态系统。该生态系统是为数据处理而构建的。它以创建数据的应用程序的形式接受输入,并以度量标准,报告等形式定义输出。下图表示Kafka的循环数据生态系统。
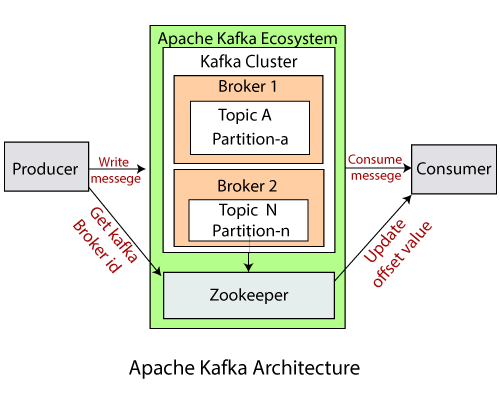
- Kafka群集: Kafka群集是一个由不同的代理,主题及其各自的分区组成的系统。数据将写入集群中的主题,并由集群本身读取。
- 生产者:生产者将数据/消息发送或写入集群中的主题。为了存储大量数据,应用程序中的不同生产者会将数据发送到Kafka集群。
- 使用者:使用者是读取或使用Kafka集群中的消息的使用者。可能有几个使用者从集群中消费了不同类型的数据。 Kafka的优点在于,每个消费者都知道需要从何处消费数据。
- 代理: Kafka服务器被称为代理。经纪人是生产者和消费者之间的桥梁。如果生产者希望将数据写入群集,则将其发送到Kafka服务器。所有经纪人都位于Kafka集群中。另外,可以有多个经纪人。
- 主题:这是一个通用名称或标题,用于表示类似的数据类型。在Apache Kafka中,集群中可以有多个主题。每个主题指定不同类型的消息。
- 分区:数据或消息分为小部分,称为分区。每个分区在其中携带具有偏移值的数据。数据始终以顺序方式写入。我们可以有无限多个具有无限偏移值的分区。但是,不能保证将消息写入哪个分区。
- ZooKeeper: ZooKeeper用于存储有关Kafka群集的信息以及消费者客户端的详细信息。它通过维护经纪人列表来管理经纪人。另外,ZooKeeper负责选择分区的领导者。如果发生诸如代理死亡,新主题等更改,则ZooKeeper会向Apache Kafka发送通知。 ZooKeeper旨在与奇数个Kafka服务器一起运行。 Zookeeper有一个负责处理所有写入操作的领导服务器,其余的服务器则是负责处理所有读取操作的跟随者。但是,用户不是直接与Zookeeper交互,而是通过代理进行交互。没有Zookeeper服务器,任何Kafka服务器都无法运行。必须运行Zookeeper服务器。
注意:对于Kafka 0.10及更高版本,Zookeeper不会存储使用者偏移值。它存储在Kafka主题中(如“ Kafka主题”部分所示)。
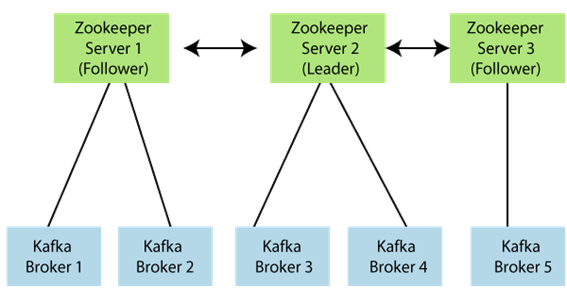
在上图中,有三个Zookeeper服务器,其中服务器2是领导者,另两个被选为其跟随者。五个代理连接到这些服务器。当代理关闭,添加更多主题等信息时,Kafka集群会自动知道。
因此,结合所有必要性,设计了一个Kafka集群体系结构。