- Python中的多维数据分析(1)
- 数据分析和数据分析的区别(1)
- 数据分析和数据分析的区别
- 大数据分析-数据分析工具
- 大数据分析-数据分析工具(1)
- Python中的多维列表(1)
- Python中的多维列表
- 数据分析的使用(1)
- 数据分析的使用
- 用于数据分析的 python - Python (1)
- 多维 Java 数组 - Python (1)
- C++多维数组
- C多维数组
- C++多维数组(1)
- C / C++中的多维数组
- C#多维数组
- C多维数组(1)
- C / C++中的多维数组
- R中的多维数组(1)
- C++多维数组
- C C++中的多维数组(1)
- C++多维数组(1)
- C#多维数组(1)
- R中的多维数组
- python 多维字典 - Python (1)
- 用于数据分析的 python - Python 代码示例
- 什么是数据分析?
- 什么是数据分析?(1)
- 多维 Java 数组 - Python 代码示例
📅 最后修改于: 2020-04-22 14:19:54 🧑 作者: Mango
多维数据分析是对数据的信息分析,其中考虑了许多关系。让我们阐明一些使用Python编写的开源库来分析多维/多元数据的基本技术。
从此处找到用于说明的数据的链接。
以下代码用于从zoo_data.csv读取2D表格数据。
import pandas as pd
zoo_data = pd.read_csv("zoo_data.csv", encoding = 'utf-8',
index_col = ["animal_name"])
# 打印动物园数据的前5行
print(zoo_data.head())输出:

注意:我们这里拥有的数据类型通常是分类的。本案例研究中用于分类数据分析的技术是非常基本的技术,易于理解,解释和实施。其中包括聚类分析,相关性分析,PCA(主成分分析)和EDA(探索性数据分析)分析。
聚类分析:
由于我们拥有的数据基于不同类型动物的特征,因此我们可以使用一些著名的聚类技术将动物分为不同的组(类)或亚组,即KMeans聚类,DBscan,分层聚类和KNN(K-最近的邻居)聚类。为了简单起见,在这种情况下,KMeans聚类应该是更好的选择。使用K均值群集技术群集的数据可以使用来实现KMeans的模块cluster class的sklearn库如下:
# 从sklearn.cluster导入KMeans
clusters = 7
kmeans = KMeans(n_clusters = clusters)
kmeans.fit(zoo_data)
print(kmeans.labels_)输出:

在这里,总体群集惯性为119.70392382759556。此值存储在kmeans.inertia_ 变量中。
EDA分析:
要执行EDA分析,我们需要降低多元数据的维数,而我们必须对三元数据/(2D / 3D)数据进行处理。我们可以使用PCA(主成分分析)来完成此任务。PCA可以进行使用PCA module的class decomposition库sklearn如下:
# 从sklearn.decomposition导入PCA
pca = PCA(3)
pca.fit(zoo_data)
pca_data = pd.DataFrame(pca.transform(zoo_data))
print(pca_data.head())输出:

上面的数据输出表示我们可以在其上执行EDA分析的简化三变量(3D)数据。
注意: PCA生成的简化数据可以间接用于执行各种分析,但不能直接由人解释。
散点图是2D / 3D图,有助于分析2D / 3D数据中的各种聚类。
我们之前生成的3D缩减数据的散点图可以绘制如下:
下面的代码是一个Python代码,它生成一个颜色数组(其中颜色的数量大约等于聚类的数量),这些颜色按其色相,值和饱和度值排序。在这里,每种颜色都与单个群集相关联,并且将动物绘制在3D图形/空间(在这种情况下为散点图)时,将其表示为3D点。
from matplotlib import colors as mcolors
import math
''' 以其hsv值的升序生成不同的颜色 '''
colors = list(zip(*sorted((
tuple(mcolors.rgb_to_hsv(
mcolors.to_rgba(color)[:3])), name)
for name, color in dict(
mcolors.BASE_COLORS, **mcolors.CSS4_COLORS
).items())))[1]
# 产生n(簇)颜色的步骤数
skips = math.floor(len(colors[5 : -5])/clusters)
cluster_colors = colors[5 : -5 : skips]以下代码是Python代码,可生成3D散点图,其中每个数据点的颜色都与其对应的簇有关。
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
fig = plt.figure()
ax = fig.add_subplot(111, projection = '3d')
ax.scatter(pca_data[0], pca_data[1], pca_data[2],
c = list(map(lambda label : cluster_colors[label],
kmeans.labels_)))
str_labels = list(map(lambda label:'% s' % label, kmeans.labels_))
list(map(lambda data1, data2, data3, str_label:
ax.text(data1, data2, data3, s = str_label, size = 16.5,
zorder = 20, color = 'k'), pca_data[0], pca_data[1],
pca_data[2], str_labels))
plt.show()输出:

仔细分析散点图可以得出这样的假设:使用初始数据形成的聚类没有足够好的解释力。要解决此问题,我们需要将一组功能归为一组更有用的功能,使用这些功能我们可以生成有用的群集。产生这样一组特征的一种方法是进行相关分析。这可以通过如下绘制热图和三面图来完成:
import seaborn as sns
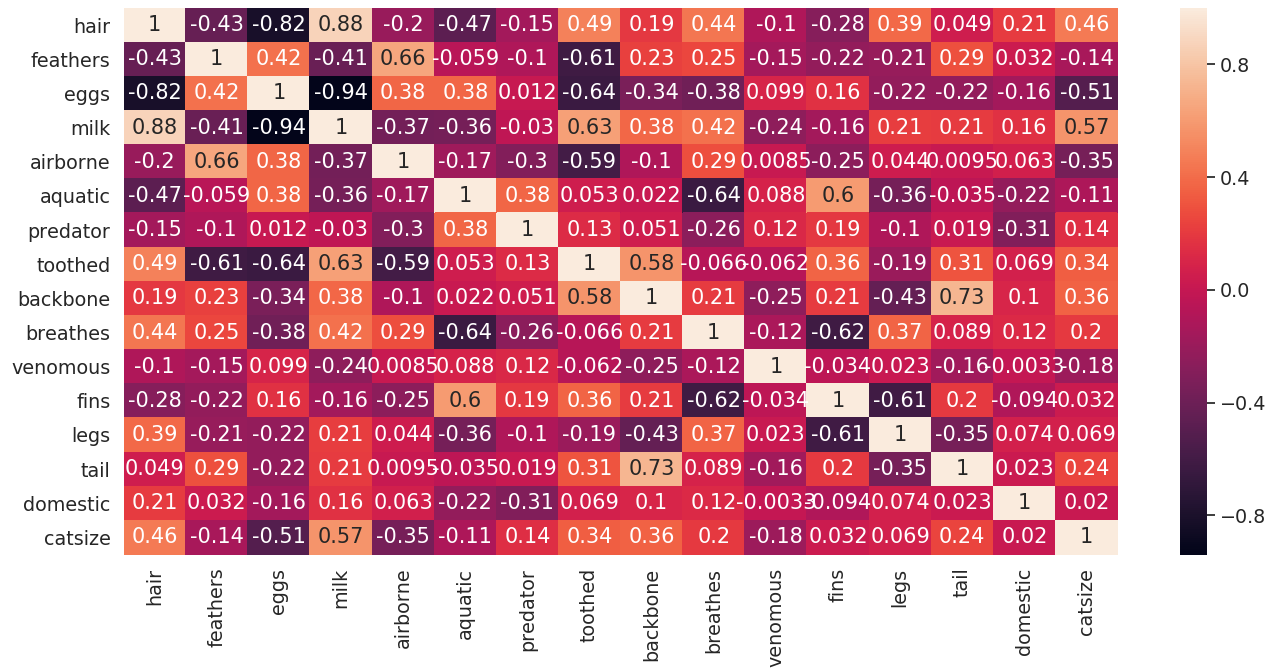
# 生成相关热图
sns.heatmap(zoo_data.corr(), annot = True)
# 将相关热图发布到输出控制台
plt.show()输出:
以下代码用于通过创建元组列表来生成相关性矩阵的三面图,其中元组包含按动物名称顺序的坐标和相关值。
上面解释的伪代码:
# 伪代码
tuple -> (position_in_dataframe(feature1),
position_in_dataframe(feature2),
correlation(feature1, feature2))用于为相关矩阵生成三面图的代码:
from matplotlib import cm
# 产生相关数据
df = zoo_data.corr()
df.index = range(0, len(df))
df.rename(columns = dict(zip(df.columns, df.index)), inplace = True)
df = df.astype(object)
''' 生成具有相应相关值的坐标 '''
for i in range(0, len(df)):
for j in range(0, len(df)):
if i != j:
df.iloc[i, j] = (i, j, df.iloc[i, j])
else :
df.iloc[i, j] = (i, j, 0)
df_list = []
# 展平数据框值
for sub_list in df.values:
df_list.extend(sub_list)
# 将元组列表转换为三元数据框
plot_df = pd.DataFrame(df_list)
fig = plt.figure()
ax = Axes3D(fig)
# 绘制3D三面图
ax.plot_trisurf(plot_df[0], plot_df[1], plot_df[2],
cmap = cm.jet, linewidth = 0.2)
plt.show()输出:
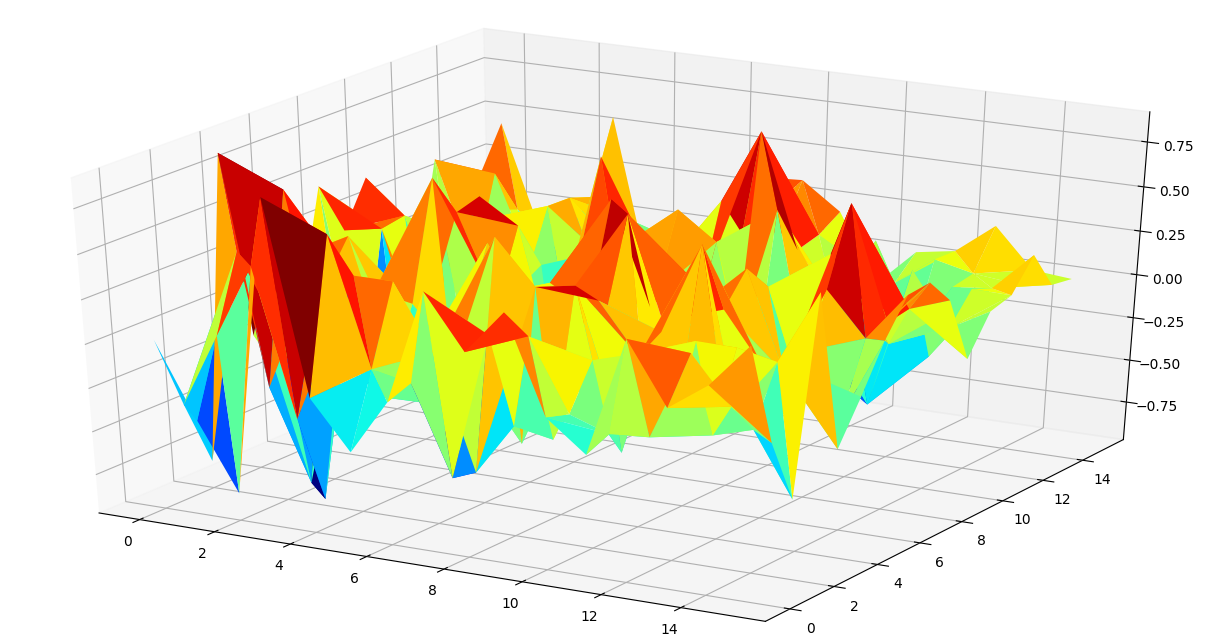
使用热图和三面图,我们可以推断出如何选择用于执行聚类分析的较小特征集。通常,具有极高相关性值的特征对具有很高的解释力,可以用于进一步分析。
在这种情况下,通过查看两个图,我们得出了7个特征的合理列表:[“牛奶”,“鸡蛋”,“头发”,“有齿”,“羽毛”,“呼吸”,“水生”]
在子集特征集上再次运行聚类分析,我们可以生成散点图,更好地推断出如何在不同组之间传播不同的动物。
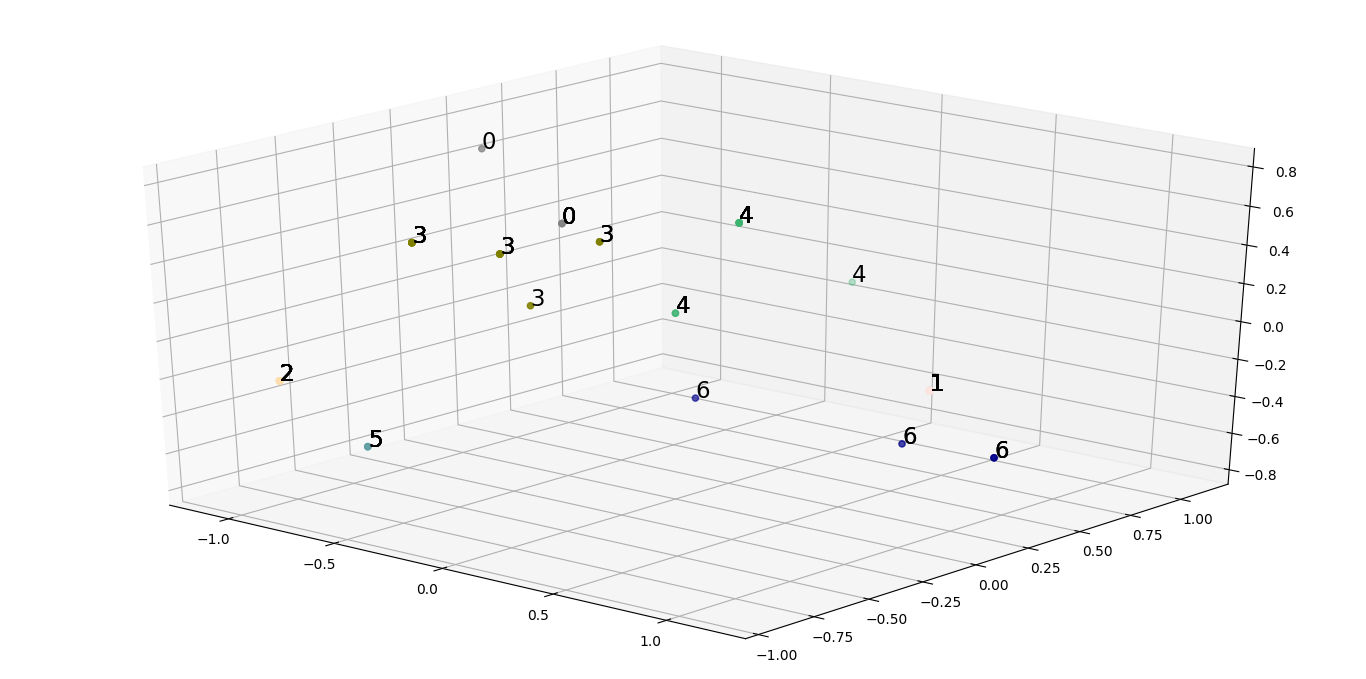
我们观察到整体惯性降低了14.479670329670329,这确实比初始惯性要小得多。