- 分布式DBMS-分布式数据库(1)
- 分布式DBMS-数据库控制
- 分布式DBMS-数据库恢复(1)
- 分布式DBMS-数据库恢复
- 分布式DBMS教程
- 讨论分布式DBMS(1)
- 讨论分布式DBMS
- 分布式DBMS-概念
- 分布式 DBMS 的缺点(1)
- 分布式 DBMS 的缺点
- 分布式DBMS-有用的资源
- 分布式DBMS-有用的资源(1)
- 分布式DBMS-失败和提交
- 分布式DBMS-失败和提交(1)
- 分布式DBMS-提交协议(1)
- 分布式DBMS-提交协议
- 分布式DBMS-设计策略
- 分布式DBMS-设计策略(1)
- 分布式DBMS-复制控制
- 分布式DBMS-复制控制(1)
- 分布式数据库的概念
- 分布式数据库的概念(1)
- 分布式 DBMS 中的碎片化(1)
- 分布式 DBMS 中的碎片化
- 并行数据库和分布式数据库的区别(1)
- 并行数据库和分布式数据库的区别
- 并行数据库和分布式数据库的区别
- DBMS 中的数据库对象(1)
- DBMS 中的数据库对象
📅 最后修改于: 2021-01-07 05:23:47 🧑 作者: Mango
在本教程的这一部分中,我们将研究有助于设计分布式数据库环境的不同方面。本章从分布式数据库的类型开始。分布式数据库可以分为具有进一步划分的同质和异类数据库。本章的下一部分讨论分布式架构,即客户端-服务器,对等-对等和多DBMS。最后,介绍了不同的设计替代方案,例如复制和分段。
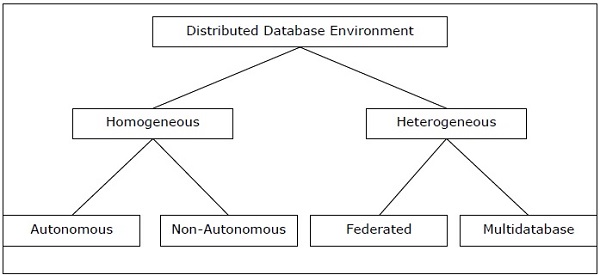
分布式数据库的类型
分布式数据库可以大致分为同类和异构的分布式数据库环境,每个环境都有进一步的细分,如下图所示。
异构分布式数据库
在同质分布式数据库中,所有站点都使用相同的DBMS和操作系统。它的特性是-
-
这些站点使用非常相似的软件。
-
这些站点使用相同的DBMS或来自同一供应商的DBMS。
-
每个站点都知道所有其他站点,并与其他站点合作以处理用户请求。
-
通过单个接口访问数据库,就好像它是单个数据库一样。
异构分布式数据库的类型
异构分布式数据库有两种类型-
-
自治-每个数据库都是独立的,可以独立运行。它们由控制应用程序集成,并使用消息传递来共享数据更新。
-
非自治-数据分布在同类节点上,中央DBMS或主DBMS协调站点之间的数据更新。
异构分布式数据库
在异构的分布式数据库中,不同的站点具有不同的操作系统,DBMS产品和数据模型。它的特性是-
-
不同的站点使用不同的架构和软件。
-
该系统可以由诸如关系,网络,层次或面向对象的各种DBMS组成。
-
由于架构不同,查询处理非常复杂。
-
由于软件不同,交易处理非常复杂。
-
一个站点可能不知道其他站点,因此在处理用户请求时合作有限。
异构分布式数据库的类型
-
联合-异构数据库系统本质上是独立的,并且集成在一起,因此它们函数充当单个数据库系统。
-
非联合-数据库系统采用中央协调模块,通过该模块可以访问数据库。
分布式DBMS架构
DDBMS体系结构通常是根据三个参数开发的-
-
分布-它指出了跨不同站点的数据的物理分布。
-
自治-表示数据库系统的控制分布以及每个组成DBMS可以独立运行的程度。
-
异构性-指数据模型,系统组件和数据库的一致性或不相似性。
建筑模型
一些常见的架构模型是-
- 客户端-DDBMS的服务器体系结构
- DDBMS的对等架构
- 多DBMS体系结构
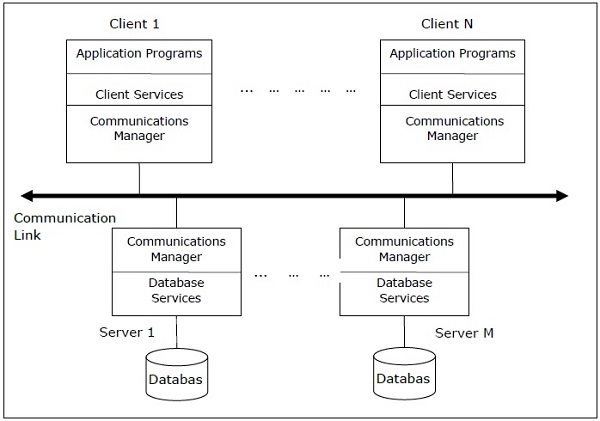
客户端-DDBMS的服务器体系结构
这是一个两级体系结构,其中功能分为服务器和客户端。服务器功能主要包括数据管理,查询处理,优化和事务管理。客户端功能主要包括用户界面。但是,它们具有一些功能,如一致性检查和事务管理。
两种不同的客户端-服务器架构是-
- 单服务器多客户端
- 多服务器多客户端(如下图所示)
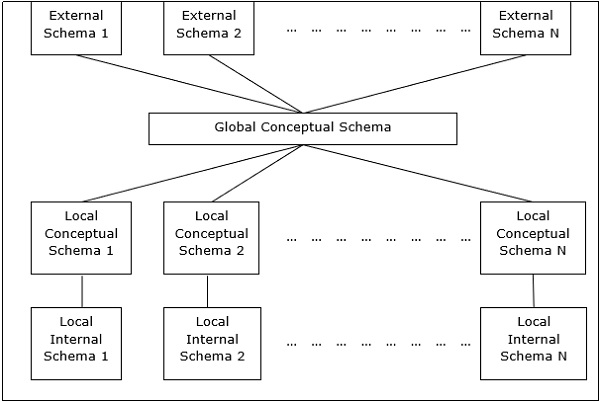
DDBMS的对等架构
在这些系统中,每个对等方都充当提供数据库服务的客户端和服务器。对等方与其他对等方共享资源并协调其活动。
这种架构通常具有四个级别的架构-
-
全局概念架构-描述数据的全局逻辑视图。
-
本地概念架构-描述每个站点的逻辑数据组织。
-
本地内部架构-描述每个站点的物理数据组织。
-
外部架构-描述数据的用户视图。
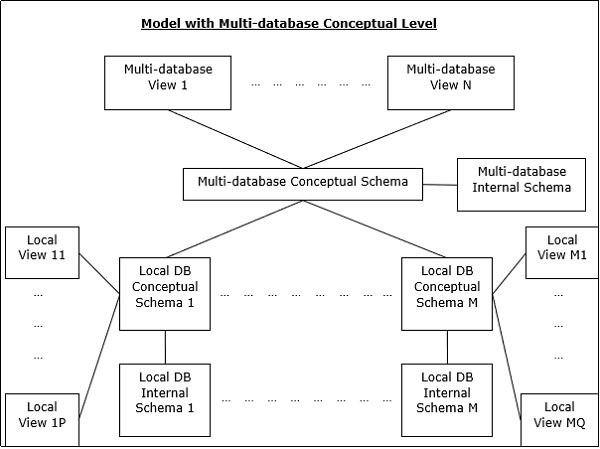
多DBMS架构
这是一个集成的数据库系统,由两个或多个自治数据库系统的集合组成。
可以通过六个级别的模式来表示多DBMS-
-
多数据库视图级别-描述由集成分布式数据库的子集组成的多个用户视图。
-
多数据库概念级别-描述了由全局逻辑多数据库结构定义组成的集成多数据库。
-
多数据库内部级别-描述跨不同站点的数据分布以及从多数据库到本地数据的映射。
-
本地数据库视图级别-描述本地数据的公共视图。
-
本地数据库概念级别-描述每个站点的本地数据组织。
-
本地数据库内部级别-描述每个站点的物理数据组织。
多DBMS有两种设计替代方案-
- 具有多数据库概念级别的模型。
- 没有多数据库概念级别的模型。
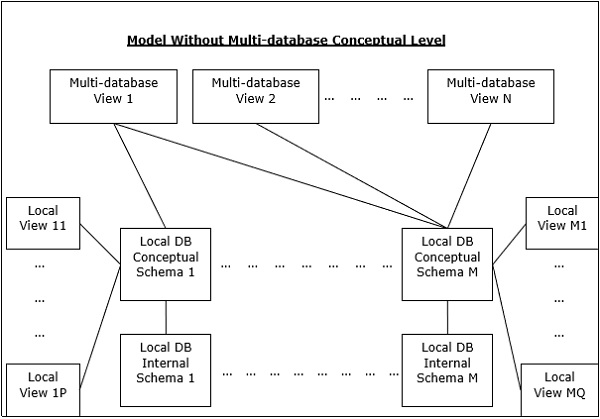
设计方案
DDBMS中表的分发设计替代方案如下-
- 无复制和无碎片
- 完全复制
- 部分复制
- 支离破碎
- 混合的
非复制和非碎片
在此设计替代方案中,将不同的表放置在不同的位置。放置数据时,应使其紧靠使用最多的站点。它最适用于将位于不同站点的表中的信息进行联接所需的查询百分比较低的数据库系统。如果采用适当的分发策略,则此设计替代方案有助于减少数据处理期间的通信成本。
完全复制
在这种设计替代方案中,在每个站点上都存储了所有数据库表的一个副本。由于每个站点都有其自己的整个数据库副本,因此查询速度非常快,所需的通信成本可忽略不计。相反,数据的大量冗余在更新操作期间需要巨大的成本。因此,这适用于需要处理大量查询而数据库更新次数很少的系统。
部分复制
表的副本或表的一部分存储在不同的位置。表的分配是根据访问频率完成的。考虑到以下事实:访问表的频率因站点而异。表(或部分)的副本数取决于访问查询的执行频率以及生成访问查询的站点。
支离破碎
在这种设计中,一张桌子被分为两部分或更多部分,称为碎片或分区,每个碎片可以存储在不同的位置。这考虑到以下事实:在给定站点上很少需要存储表中的所有数据。此外,碎片化增加了并行性,并提供了更好的灾难恢复。在此,系统中每个片段只有一个副本,即没有冗余数据。
三种碎片化技术是-
- 垂直碎片
- 水平碎片
- 杂种碎片
混合发行
这是碎片和部分复制的组合。在这里,表格最初会以任何形式(水平或垂直)进行分段,然后根据访问这些片段的频率在不同的位置部分复制这些片段。