查找文本文件中重复次数最多的单词
Python提供了用于创建、写入和读取文件的内置函数。 Python可以处理两种类型的文件,普通文本文件和二进制文件(用二进制语言编写,0s 和 1s)。
- 文本文件:在这种类型的文件中,每行文本都以一个叫做EOL(End of Line)的特殊字符结尾,这是Python中默认的字符('\n')。
- 二进制文件:在这种类型的文件中,一行没有终止符,将数据转换成机器可以理解的二进制语言后存储。
这里我们操作的是Python中的.txt 文件。通过这个程序,我们将找到文件中重复次数最多的单词。
方法:
- 我们将文件的内容作为输入。
- 从输入字符串中删除空格和标点符号后,我们会将每个单词保存在列表中。
- 找出每个单词出现的频率。
- 打印出现频率最高的单词。
输入文件:
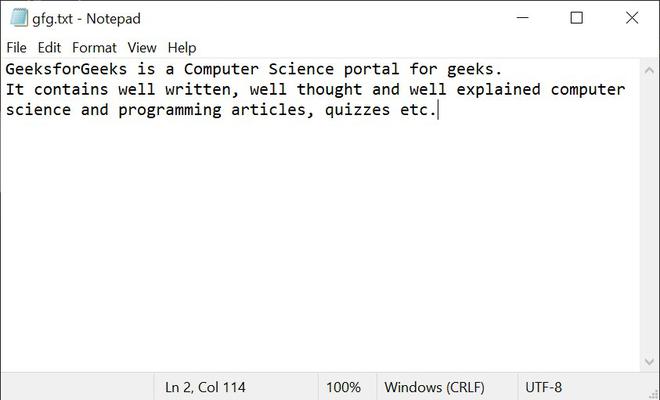
下面是上述方法的实现:
Python3
# Python program to find the most repeated word
# in a text file
# A file named "gfg", will be opened with the
# reading mode.
file = open("gfg.txt","r")
frequent_word = ""
frequency = 0
words = []
# Traversing file line by line
for line in file:
# splits each line into
# words and removing spaces
# and punctuations from the input
line_word = line.lower().replace(',','').replace('.','').split(" ");
# Adding them to list words
for w in line_word:
words.append(w);
# Finding the max occured word
for i in range(0, len(words)):
# Declaring count
count = 1;
# Count each word in the file
for j in range(i+1, len(words)):
if(words[i] == words[j]):
count = count + 1;
# If the count value is more
# than highest frequency then
if(count > frequency):
frequency = count;
frequent_word = words[i];
print("Most repeated word: " + frequent_word)
print("Frequency: " + str(frequency))
file.close();输出:
Most repeated word: well
Frequency: 3