- 编译器设计中的语法分析简介
- 编译器设计中的语法分析简介(1)
- 编译器设计中的语法分析简介
- 编译器设计中的增量编译器(1)
- 编译器设计中的增量编译器(1)
- 编译器设计中的增量编译器
- 编译器设计中的增量编译器
- 语法分析中的第一组(1)
- 语法分析中的第一组
- 编译器设计教程(1)
- 编译器设计教程
- 编译器设计-正则表达式(1)
- 编译器设计-正则表达式
- 语法分析中的第一个集合
- 语法分析中的第一个集合(1)
- 语法分析中的跟随集(1)
- 语法分析中的跟随集
- 讨论编译器设计
- 编译器设计中的解析树
- 编译器设计中的解析树(1)
- 编译器设计中的解析树
- 编译器设计中的解析树
- 编译器设计中的解析树(1)
- 编译器设计中的解析树(1)
- 编译器设计中的左递归 (1)
- 编译器设计-概述
- 编译器设计-概述(1)
- 编译器设计介绍(1)
- 编译器设计介绍
📅 最后修改于: 2021-01-18 05:25:48 🧑 作者: Mango
语法分析或解析是编译器的第二阶段。在本章中,我们将学习解析器构造中使用的基本概念。
我们已经看到,词法分析器可以借助正则表达式和模式规则来识别标记。但是由于正则表达式的限制,词法分析器无法检查给定句子的语法。正则表达式无法检查平衡标记,例如括号。因此,此阶段使用上下文无关文法(CFG),该上下文由下推自动机识别。
另一方面,CFG是正则语法的超集,如下所示:

这意味着每个常规语法也是无上下文关系的,但是存在一些问题,这些问题超出了常规语法的范围。 CFG是描述编程语言语法的有用工具。
上下文无关文法
在本节中,我们将首先看到上下文无关文法的定义,并介绍解析技术中使用的术语。
上下文无关的语法具有四个组成部分:
-
一组非终端(V)。非终结符是表示字符串集的语法变量。非终结符定义字符串集,以帮助定义语法生成的语言。
-
一组令牌,称为终端符号(Σ)。终端是构成字符串的基本符号。
-
一组产品(P)。语法的产生指定了可以将末端和非末端组合为字符串。每个产品包括一个非终端(称为产品的左侧),一个箭头以及一系列令牌和/或终端(称为产品的右侧)。
-
非终端之一被指定为开始符号(S);从生产开始的地方。
字符串是通过从生产符号的右侧反复替换非终结符(最初是起始符号)而从该起始符号派生的。
例
我们考虑了回文语言的问题,这不能用正则表达式来描述。也就是说,L = {w | w = w R }不是常规语言。但是可以通过CFG对其进行描述,如下所示:
G = ( V, Σ, P, S )
哪里:
V = { Q, Z, N }
Σ = { 0, 1 }
P = { Q → Z | Q → N | Q → ℇ | Z → 0Q0 | N → 1Q1 }
S = { Q }
此语法描述回文语言,例如:1001、11100111、00100、1010101、11111等。
语法分析器
语法分析器或解析器以令牌流的形式从词法分析器获取输入。解析器根据生产规则分析源代码(令牌流),以检测代码中的任何错误。此阶段的输出是一个分析树。
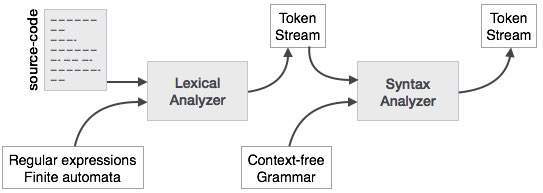
这样,解析器完成两项任务,即解析代码,查找错误并生成解析树作为阶段的输出。
即使程序中存在一些错误,解析器也应该解析整个代码。解析器使用错误恢复策略,我们将在本章后面学习这些策略。
推导
为了获得输入字符串,派生基本上是生产规则的序列。在解析期间,我们对输入的某些句子形式做出两个决定:
- 确定要替换的非终端。
- 确定生产规则,以此来替换非终端。
要决定用生产规则替换哪个非终端设备,我们可以有两个选择。
最左边的导数
如果输入的句子形式被扫描并从左到右进行替换,则称为最左派生。由最左派生的派生形式称为左派形式。
最右派生
如果我们从右到左扫描并将输入替换为生产规则,则称为最右派生。从最右派生而来的句法形式称为右句法形式。
例
生产规则:
E → E + E
E → E * E
E → id
输入字符串:id + id * id
最左边的推导是:
E → E * E
E → E + E * E
E → id + E * E
E → id + id * E
E → id + id * id
请注意,最左边的非终结符总是首先被处理。
最右边的推导是:
E → E + E
E → E + E * E
E → E + E * id
E → E + id * id
E → id + id * id
解析树
解析树是派生的图形表示。方便查看字符串是如何从起始符号派生的。派生的开始符号成为解析树的根。让我们通过上一个主题的示例来了解这一点。
我们采用a + b * c的最左导数
最左边的推导是:
E → E * E
E → E + E * E
E → id + E * E
E → id + id * E
E → id + id * id
第1步:
| E → E * E |  |
第2步:
| E → E + E * E |  |
第三步:
| E → id + E * E |  |
第4步:
| E → id + id * E |  |
步骤5:
| E → id + id * id |  |
在解析树中:
- 所有叶节点都是终端。
- 所有内部节点都是非终端节点。
- 按顺序遍历给出原始输入字符串。
解析树描述了运算符的关联性和优先级。最深的子树被遍历第一,因此在该子树中的运算符搭乘优先于运算符这是在父节点。
歧义性
如果语法G对于至少一个字符串具有多个解析树(左派或右派生),则被认为是模棱两可的。
例
E → E + E
E → E – E
E → id
对于字符串id + id – id,上面的语法生成两个解析树:
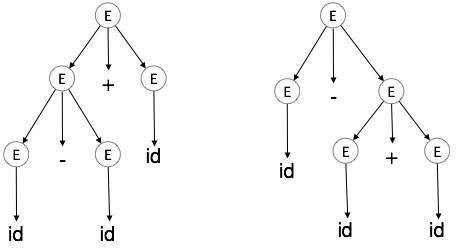
歧义语法产生的语言被认为本质上是歧义的。语法上的歧义不适用于编译器构造。没有方法可以自动检测并消除歧义,但是可以通过无歧义地重写整个语法,或者通过设置并遵循关联性和优先级约束来消除它。
关联性
如果操作数对双方的运算符,在其上运算符采用此操作的一侧通过这些运算符的结合决定。如果操作是左关联的,则操作数将由左运算符;如果操作是右关联的,则右运算符将采用操作数。
例
诸如加法,乘法,减法和除法之类的操作保持关联。如果表达式包含:
id op id op id
它将被评估为:
(id op id) op id
例如,(id + id)+ id
运算(如幂运算)是右关联的,即,同一表达式中的求值顺序为:
id op (id op id)
例如,id ^(id ^ id)
优先顺序
如果两个不同的运算符共享一个公共操作数,则运算符的优先级将决定采用哪个操作数。也就是说,2 + 3 * 4可以具有两个不同的解析树,一个对应于(2 + 3)* 4,另一个对应于2+(3 * 4)。通过在运算符之间设置优先级,可以轻松解决此问题。与前面的示例一样,数学上*(乘法)的优先级高于+(加法),因此表达式2 + 3 * 4将始终解释为:
2 + (3 * 4)
这些方法减少了语言或其语法中出现歧义的机会。
左递归
如果语法具有派生包含“ A”本身作为最左侧符号的任何非终结符“ A”,则该语法将变为左递归。对于自上而下的解析器,左递归语法被认为是一个有问题的情况。自上而下的解析器从“开始”符号开始解析,“开始”符号本身是非终结符。因此,当解析器在派生时遇到相同的非终结符时,很难判断何时停止解析左非终结符,并且陷入无限循环。
例:
(1) A => Aα | β
(2) S => Aα | β
A => Sd
(1)是立即左递归的示例,其中A是任何非终结符,而α表示字符串非终结符。
(2)是间接左递归的示例。
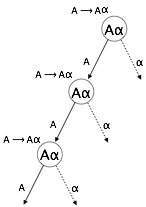
自上而下的解析器将首先解析A,这又将产生一个包含A本身的字符串,并且解析器可能永远陷入循环。
删除左递归
删除左递归的一种方法是使用以下技术:
生产
A => Aα | β
转换为以下作品
A => βA'
A'=> αA' | ε
这不会影响从语法派生的字符串,但会消除立即的左递归。
第二种方法是使用以下算法,该算法应消除所有直接和间接的左递归。
START
Arrange non-terminals in some order like A1, A2, A3,…, An
for each i from 1 to n
{
for each j from 1 to i-1
{
replace each production of form Ai ⟹Aj𝜸
with Ai ⟹ δ1𝜸 | δ2𝜸 | δ3𝜸 |…| 𝜸
where Aj ⟹ δ1 | δ2|…| δn are current Aj productions
}
}
eliminate immediate left-recursion
END
例
生产集
S => Aα | β
A => Sd
应用上述算法后,应成为
S => Aα | β
A => Aαd | βd
然后,使用第一种技术删除立即的左递归。
A => βdA'
A' => αdA' | ε
现在,任何产品都不具有直接或间接的左递归。
左分解
如果不止一个语法生产规则具有公共前缀字符串,那么自上而下的解析器将无法选择解析该字符串应采用哪种生产形式。
例
如果自上而下的解析器遇到像
A ⟹ αβ | α𝜸 | …
然后,由于两个生产都是从同一终端(或非终端)开始的,因此无法确定要跟随哪个生产来解析字符串。为了消除这种混乱,我们使用了一种称为左分解的技术。
左因子分解可转换语法,使其对自上而下的解析器有用。在这种技术中,我们为每个公共前缀制作一个产品,其余的推导被新产品添加。
例
以上作品可以写成
A => αA'
A'=> β | 𝜸 | …
现在,解析器的每个前缀只有一个乘积,这使得决策更加容易。
第一和跟随集
解析器表构造的重要部分是创建第一和第二组。这些集合可以提供派生中任何终端的实际位置。这样做是为了创建分析表,其中决定用某些生产规则替换T [A,t] =α。
第一组
创建此集合的目的是要知道非终端在第一个位置导出了哪些终端符号。例如,
α → t β
也就是说,α在第一个位置导出t(终端)。因此,t∈FIRST(α)。
计算第一组的算法
查看FIRST(α)集的定义:
- 如果α是末端,则FIRST(α)= {α}。
- 如果α是一个非末端且α→ℇ是一个乘积,则FIRST(α)= {ℇ}。
- 如果α为非末端且α→𝜸1 𝜸2 𝜸3…𝜸n并且任何FIRST(𝜸)包含t,则t在FIRST(α)中。
第一组可以看成是:
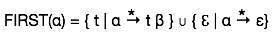
跟随集
同样,我们计算生产规则中紧跟在非终止α后面的终止符。我们不考虑非终端产生的内容,而是看到跟随非终端产生的下一个终端符号。
计算跟随集的算法:
-
如果α是开始符号,则FOLLOW()= $
-
如果α为非末端且产生α→AB,则FIRST(B)在FOLLOW(A)中,A除外。
-
如果α是一个非末端并且产生α→AB,其中B where,则FOLLOW(A)在FOLLOW(α)中。
跟随集可以看作:FOLLOW(α)= {t | S *αt*}
语法分析器的局限性
语法分析器从词法分析器接收令牌形式的输入。词法分析器负责语法分析器提供的令牌的有效性。语法分析器具有以下缺点-
- 它无法确定令牌是否有效,
- 它无法确定令牌在使用前是否已声明,
- 它无法确定令牌在使用前是否已初始化,
- 它无法确定对令牌类型执行的操作是否有效。
这些任务由语义分析器完成,我们将在语义分析中对其进行研究。