- 编译器中的符号表
- 编译器中的符号表(1)
- 编译器中的符号表
- 编译器中的符号表(1)
- 符号表
- 符号表(1)
- 编译器设计中的增量编译器
- 编译器设计中的增量编译器(1)
- 编译器设计中的增量编译器
- 编译器设计中的增量编译器(1)
- 编译器设计教程
- 编译器设计教程(1)
- 编译器设计-正则表达式(1)
- 编译器设计-正则表达式
- 讨论编译器设计
- 编译器设计中的解析树
- 编译器设计中的解析树(1)
- 编译器设计中的解析树
- 编译器设计中的解析树(1)
- 编译器设计中的解析树
- 编译器设计中的解析树(1)
- 编译器设计中的左递归 (1)
- 编译器设计-概述
- 编译器设计-概述(1)
- 编译器设计介绍(1)
- 编译器设计介绍(1)
- 编译器设计介绍
- 编译器设计介绍
- 编译器设计-体系结构
📅 最后修改于: 2021-01-18 05:29:14 🧑 作者: Mango
符号表是由编译器创建和维护的重要数据结构,用于存储有关各种实体(例如变量名,函数名,对象,类,接口等)的出现的信息。符号表可用于分析和综合编译器的各个部分。
根据所使用的语言,符号表可用于以下目的:
-
将所有实体的名称以结构化形式存储在一个地方。
-
验证是否已声明变量。
-
为了实现类型检查,通过验证源代码中的赋值和表达式在语义上是正确的。
-
确定名称的范围(范围分辨率)。
符号表只是可以是线性表或哈希表的表。它使用以下格式维护每个名称的条目:
例如,如果符号表必须存储有关以下变量声明的信息:
static int interest;
那么它应该存储条目,例如:
attribute子句包含与名称相关的条目。
实作
如果编译器要处理少量数据,则可以将符号表实现为无序列表,这很容易编写代码,但仅适用于小表。可以通过以下方式之一来实现符号表:
- 线性(排序或未排序)列表
- 二进制搜索树
- 哈希表
其中,符号表主要实现为哈希表,其中源代码符号本身被视为哈希函数的键,返回值是有关符号的信息。
运作方式
线性或哈希符号表应提供以下操作。
插入()
分析阶段(即在编译器的前半部分)会更频繁地使用此操作,在该阶段的前半部分将识别标记并将名称存储在表中。此操作用于在符号表中添加有关源代码中出现的唯一名称的信息。名称的存储格式或结构取决于手头的编译器。
源代码中符号的属性是与该符号关联的信息。此信息包含有关符号的值,状态,范围和类型。 insert()函数将符号及其属性作为参数,并将信息存储在符号表中。
例如:
int a;
应由编译器按以下方式处理:
insert(a, int);
抬头()
lookup()操作用于在符号表中搜索名称以确定:
- 表中是否存在该符号。
- 如果在使用前声明了它。
- 如果在范围中使用了该名称。
- 如果符号已初始化。
- 如果符号多次声明。
lookup()函数的格式根据编程语言而有所不同。基本格式应符合以下条件:
lookup(symbol)
如果符号表中不存在符号,则此方法返回0(零)。如果符号存在于符号表中,则它返回存储在表中的属性。
范围管理
编译器维护两种类型的符号表:可以由所有过程访问的全局符号表和为程序中的每个作用域创建的作用域符号表。
为了确定名称的范围,符号表按层次结构排列,如下例所示:
. . .
int value=10;
void pro_one()
{
int one_1;
int one_2;
{ \
int one_3; |_ inner scope 1
int one_4; |
} /
int one_5;
{ \
int one_6; |_ inner scope 2
int one_7; |
} /
}
void pro_two()
{
int two_1;
int two_2;
{ \
int two_3; |_ inner scope 3
int two_4; |
} /
int two_5;
}
. . .
上面的程序可以用符号表的层次结构表示:
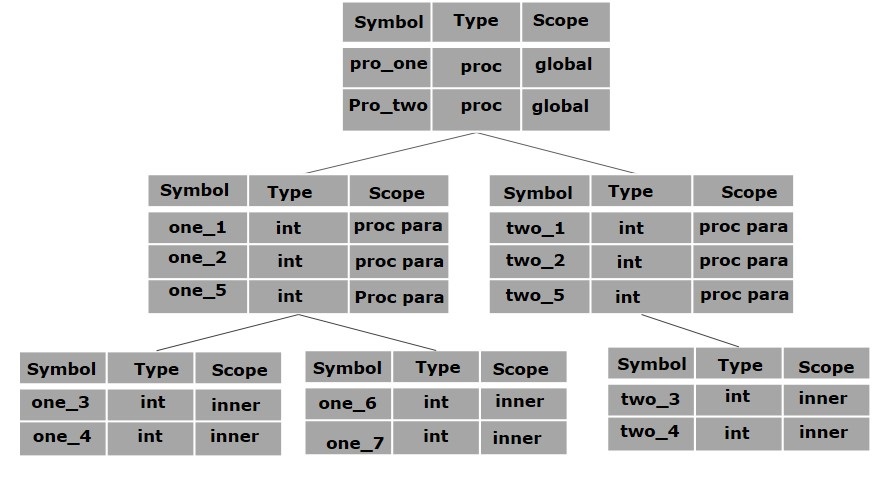
全局符号表包含一个全局变量(int值)的名称和两个过程名称,它们应可用于上面显示的所有子节点。 pro_one符号表(及其所有子表)中提到的名称不适用于pro_two符号及其子表。
该符号表数据结构层次结构存储在语义分析器中,每当需要在符号表中搜索名称时,都使用以下算法搜索该名称:
-
首先,将在当前范围(即当前符号表)中搜索符号。
-
如果找到名称,则搜索完成,否则将在父符号表中进行搜索,直到,
-
找到名称或已在全局符号表中搜索名称。