- 编译器设计中的中间代码生成
- 编译器设计中的中间代码生成
- 编译器设计-代码生成(1)
- 编译器设计-代码生成
- 代码生成器(1)
- 代码生成
- 代码生成(1)
- 代码生成器
- 编译器设计中的目标代码生成
- 编译器设计中的目标代码生成
- 编译器设计中的目标代码生成
- 代码生成器设计中的问题(1)
- 代码生成器设计中的问题
- html 代码生成器 - Html (1)
- c# 编译器 (1)
- html 代码生成器 - Html 代码示例
- 代码生成中的流程图(1)
- 代码生成中的流程图
- php 代码生成强密码 - PHP (1)
- php 代码生成强密码 - PHP 代码示例
- 独特的代码生成器 javascript 代码示例
- 从 python 代码生成 uml - Shell-Bash (1)
- 在代码生成中注册分配(1)
- 在代码生成中注册分配
- Java中的编译器类
- Java中的编译器类(1)
- 中间字css中的行(1)
- 从 java 代码生成类图 (1)
- 从 python 代码生成 uml - Shell-Bash 代码示例
📅 最后修改于: 2021-01-18 05:29:49 🧑 作者: Mango
可以将源代码直接转换为目标机器代码,那么为什么我们需要将源代码转换为中间代码,然后再转换为目标代码呢?让我们看看需要中间代码的原因。
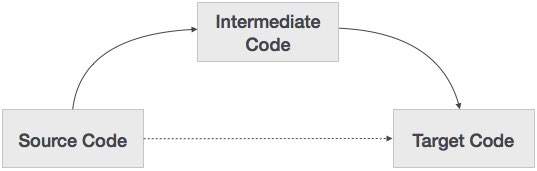
-
如果编译器将源语言翻译成目标机器语言而没有生成中间代码的选项,则对于每台新机器,都需要一个完整的本机编译器。
-
中间代码通过使所有编译器的分析部分保持相同,从而无需为每台唯一的计算机使用新的完整编译器。
-
编译器的第二部分,即综合,根据目标机器进行了更改。
-
通过在中间代码上应用代码优化技术,应用源代码修改以提高代码性能变得更加容易。
中级代表
中间代码可以用多种方式表示,它们有自己的优势。
-
高级IR-高级中间代码表示非常接近源语言本身。它们可以很容易地从源代码生成,我们可以轻松地应用代码修改来增强性能。但是对于目标机器优化,它不是首选。
-
低级IR-靠近目标计算机,这使其适合于寄存器和内存分配,指令集选择等。非常适合于与计算机有关的优化。
中间代码可以是特定于语言的(例如,Java的字节码),也可以是独立于语言的(三地址代码)。
三地址代码
中间代码生成器以注释语法树的形式从其前一阶段语义分析器接收输入。然后可以将该语法树转换为线性表示形式,例如后缀表示法。中间代码往往是与机器无关的代码。因此,代码生成器假定具有无限数量的存储器存储(寄存器)来生成代码。
例如:
a = b + c * d;
中间代码生成器将尝试将此表达式划分为子表达式,然后生成相应的代码。
r1 = c * d;
r2 = b + r1;
a = r2
r用作目标程序中的寄存器。
一个三地址代码最多具有三个地址位置来计算表达式。三地址代码可以两种形式表示:四倍和三倍。
四倍
四倍体表示法中的每条指令分为四个字段:运算符,arg1,arg2和结果。上面的示例以四倍格式表示如下:
| Op | arg1 | arg2 | result |
| * | c | d | r1 |
| + | b | r1 | r2 |
| + | r2 | r1 | r3 |
| = | r3 | a |
三元组
三元组表示法中的每条指令都有三个字段:op,arg1和arg2。各个子表达式的结果由表达式的位置表示。三元组表示与DAG和语法树的相似性。在表示表达式时,它们等效于DAG。
| Op | arg1 | arg2 |
| * | c | d |
| + | b | (0) |
| + | (1) | (0) |
| = | (2) |
三元组在优化时会遇到代码不可移动的问题,因为结果是固定的,并且更改表达式的顺序或位置可能会导致问题。
间接三元组
此表示形式是对三元组表示形式的增强。它使用指针而不是位置来存储结果。这使优化器可以自由地重新定位子表达式以生成优化的代码。
声明书
必须先声明变量或过程,然后才能使用它。声明涉及在内存中分配空间以及在符号表中输入类型和名称。可以在编写程序和设计程序时牢记目标机器的结构,但是可能无法始终将源代码准确地转换为其目标语言。
将整个程序作为过程和子过程的集合,可以声明过程本地的所有名称。内存分配以连续的方式进行,并且名称按程序中声明的顺序分配给内存。我们使用偏移量变量并将其设置为零{offset = 0},表示基地址。
源编程语言和目标计算机体系结构的名称存储方式可能有所不同,因此使用相对寻址。虽然从存储位置0 {offset = 0}开始为内存分配了名字,但稍后声明的下一名称应分配给第一个名字之后的内存。
例:
我们以C编程语言为例,其中一个整数变量分配了2个字节的内存,一个浮点变量分配了4个字节的内存。
int a;
float b;
Allocation process:
{offset = 0}
int a;
id.type = int
id.width = 2
offset = offset + id.width
{offset = 2}
float b;
id.type = float
id.width = 4
offset = offset + id.width
{offset = 6}
要在符号表中输入此详细信息,可以使用过程回车。此方法可能具有以下结构:
enter(name, type, offset)
此过程应在符号表中为变量name创建一个条目,将其类型设置为type并在其数据区域中偏移相对地址。