Sagemaker – 探索真实标签 |机器学习
你有没有想过完全从头开始做机器学习却不知道从哪里开始?如果是的话,有一个地方你可以只拿着数据集进入这个地方,然后带着经过充分训练的机器学习模型离开这个地方,该模型准备好部署在现实生活中的场景中。 Amazon Sagemaker 提供各种服务,这些服务提供标记数据集、训练模型、超参数调整以及创建推理供我们部署。 Sagemaker 提供以下服务:
- 地面真相
- 笔记本实例
- 训练作业/超参数。
- 推论
在本文中,我们将探索地面实况标记以及它如何有助于减轻开发人员标记数据集的负担。
亚马逊 sagemaker 基本事实:
询问任何机器学习专家“在机器学习部分消耗大量时间的主要任务是什么?”首先,他们会说准备和清理数据集,然后准确地标记它们以适合模型。因此,在一般标记中,数据集占用 70% 的时间,如果您提供给此数据集的模型足够敏感,则需要更多时间。 Amazon Ground Truth 提供了标签服务,在该服务中,它不仅会进行标签操作,还会创建模型需要理解的文件。 Ground Truth 提供三种服务,即
- 机械土耳其工人可用于标记小数据集,并且标记可以由人类工人完成。
- 私人标签劳动力,您可以选择让组织中的员工标记数据集
- 顾名思义,第三方供应商暗示数据集由其他一些供应商标记。
Ground Truth 还提供了内置的五个数据标记任务
- 边界框
- 图像分类
- 语义分割
- 文字分类
- 命名实体识别。
客户还可以带来他们的自定义标签任务。那么,首先我们将如何提供输入数据以及我们可以从真实情况中期望什么样的输出格式?
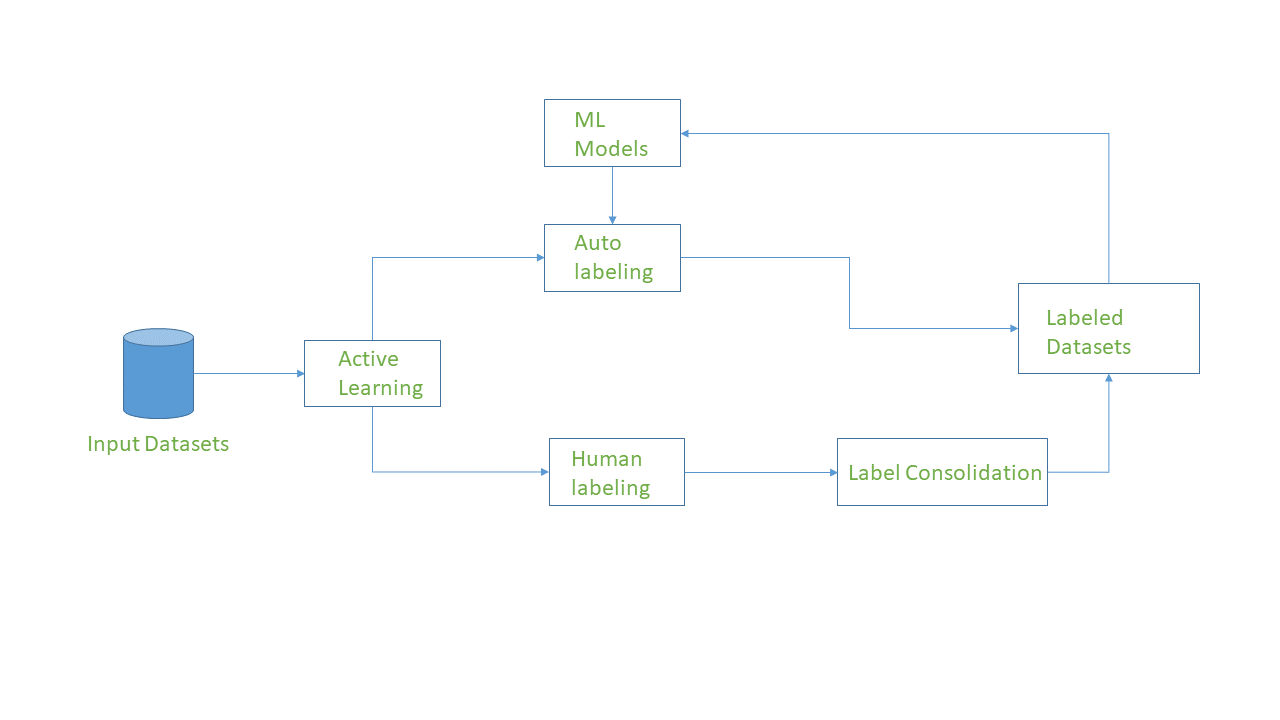
最初,我们要标记的数据集必须放在 S3 存储桶中,在创建标记作业时,我们可以提及数据集在 S3 存储桶中的位置,以便它自动创建输入清单文件。我们还必须为要存储的标记数据指定输出文件夹。如图所示,标记可以通过机器学习模型进入图片并完成工作的自动标记或人类可以完成工作的人工标记来完成。如果数据集太大,则执行自动标记。标签合并提供多数投票或检查特定图像、文本或音频等在给定数据集中的更高概率。标记完成后,ground truth 提供增强的清单文件,用于训练模型。增强清单文件包括
- Source-ref: S3 存储桶中对象的来源
- 标签作业名称:创建时启动的标签作业的名称。
代码:标记工作看起来像是在鸟类图像上执行的。
[
{
"boundingBox": {
"boundingBoxes": [
{
"height": 845,
"label": "Bird",
"left": 54,
"top": 19,
"width": 765
}
],
"inputImageProperties": {
"height": 1024,
"width": 968
}
}
}
]
现在我们已经成功地标记了我们选择的数据集,我们有了增强的清单文件,这些文件准备好提供给 sagemaker notebook 中的训练模型!