在Python中使用 Pandas 计算统计数据
在Python中执行各种复杂的统计操作可以很容易地使用 pandas 简化为单行命令。我们将在这篇文章中讨论一些最有用和最常见的统计操作。我们将使用泰坦尼克号生存数据集来演示此类操作。
Python3
# Import Pandas Library
import pandas as pd
# Load Titanic Dataset as Dataframe
dataset = pd.read_csv('train.csv')
# Show dataset
# head() bydefault show
# 5 rows of the dataframe
dataset.head()Python3
# Calculate the Mean
# of 'Age' column
mean = dataset['Age'].mean()
# Print mean
print(mean)Python3
# Calculate Median of 'Fare' column
median = dataset['Fare'].median()
# Print median
print(median)Python3
# Calculate Mode of 'Sex' column
mode = dataset['Sex'].mode()
# Print mode
print(mode)Python3
# Calculate Count of 'Ticket' column
count = dataset['Ticket'].count()
# Print count
print(count)Python3
# Calculate Standard Deviation
# of 'Fare' column
std = dataset['Fare'].std()
# Print standard deviation
print(std)Python3
# Calculate Maximum value in 'Age' column
maxValue = dataset['Age'].max()
# Print maxValue
print(maxValue)Python3
# Calculate Minimum value in 'Fare' column
minValue = dataset['Fare'].min()
# Print minValue
print(minValue)Python3
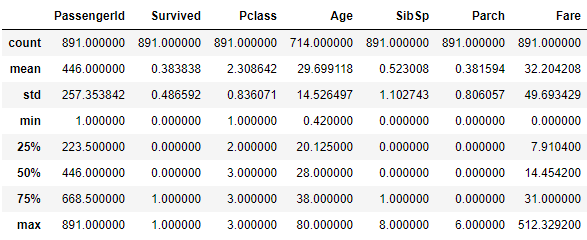
# Statistical summary
dataset.describe()输出:

1. 意思:
使用DataFrame/Series.mean()方法计算平均值或平均值。
Syntax: DataFrame/Series.mean(self, axis=None, skipna=None, level=None, numeric_only=None, **kwargs)
Parameters:
- axis: {index (0), columns (1)}
Specify the axis for the function to be applied on.
- skipna: This parameter takes bool value, default value is True
It excludes null values when computing the result.
- level: This parameter takes int value or level name, default value is None.
If the axis is a MultiIndex, count along a particular level, collapsing into a Series.
- numeric_only: This parameter takes bool value, default value is None
Include only float, int, boolean columns. If None, will attempt to use everything, then use only numeric data values. Not implemented for Series.
- **kwargs: Additional arguments to be passed to the function.
Returns: Mean of Series or DataFrame (if level specified)
代码:
Python3
# Calculate the Mean
# of 'Age' column
mean = dataset['Age'].mean()
# Print mean
print(mean)
输出:
29.699117647058822. 中位数:
使用DataFrame/Series.median()方法计算中值。
Syntax: DataFrame/Series.median(self, axis=None, skipna=None, level=None, numeric_only=None, **kwargs)
Parameters:
- axis: {index (0), columns (1)}
Specify the axis for the function to be applied on.
- skipna: This parameter takes bool value, default value is True
It excludes null values when computing the result.
- level: This parameter takes int or level name, default None
If the axis is a MultiIndex, count along a particular level, collapsing into a Series.
- numeric_only: This parameter takes bool value, default value is None
Include only float, int, boolean columns. If value is None, will attempt to use everything, then use only numeric data.
- **kwargs: Additional arguments to be passed to the function.
Returns: Median of Series or DataFrame (if level specified)
代码:
Python3
# Calculate Median of 'Fare' column
median = dataset['Fare'].median()
# Print median
print(median)
输出:
14.45423.模式:
使用DataFrame.mode()方法计算模式或最频繁的值。
Syntax: DataFrame/Series.mode(self, axis=0, numeric_only=False, dropna=True)
Parameters:
- axis: {index (0), columns (1)}
The axis to iterate over while searching for the mode value:
0 value or ‘index’ : get mode of each column
1 value or ‘columns’ : get mode of each row.
- numeric_only: This parameter takes bool value, default value is False.
If True, only apply to numeric value columns.
- dropna: This parameter takes bool value, default value is True.
Don’t consider counts of NaN/None value.
Returns: Highest frequency value.
代码:
Python3
# Calculate Mode of 'Sex' column
mode = dataset['Sex'].mode()
# Print mode
print(mode)
输出:
0 male
dtype: object4.计数:
使用DataFrame/Series.count()方法计算非空值的计数或频率。
Syntax: DataFrame/Series.count(self, axis=0, level=None, numeric_only=False)
Parameters:
- axis: {0 or ‘index’, 1 or ‘columns’}, default value is 0
If value is 0 or ‘index’ counts are generated for each column. If value is 1 or ‘columns’ counts are generated for each row.
- level: (optional)This parameter takes int or str value.
If the axis is a MultiIndex type, count along a particular level, collapsing into a DataFrame. A str is used specifies the level name.
- numeric_only: This parameter takes bool value, default False
Include only float, int or boolean data.Returns: Return the highest frequency value
Returns: For each column/row the number of non-null entries. If level is specified returns a DataFrame structure.
代码:
Python3
# Calculate Count of 'Ticket' column
count = dataset['Ticket'].count()
# Print count
print(count)
输出:
8915.标准偏差:
使用DataFrame/Series.std()方法计算值的标准差。
Syntax: DataFrame/Series.std(self, axis=None, skipna=None, level=None, ddof=1, numeric_only=None, **kwargs)
Parameters:
- axis: {index (0), columns (1)}
- skipna: This parameters takes bool value, default value is True.
Exclude NA/null values. If an entire row/column has NA values, the result will be NA value.
- level: This parameters takes int or level name, default value is None.
If the axis is a MultiIndex, count along a particular level, collapsing into a Series.
- ddof: This parameter take int value, default value is 1.
Delta Degrees of Freedom. The divisor used in calculations is N – ddof, where N value represents the number of elements.
- numeric_only: This parameter takes bool value , default None
Include only float, int, boolean columns. If None, will attempt to use everything, then use only numeric data. Not implemented for Series.
Returns: Standard Deviation
代码:
Python3
# Calculate Standard Deviation
# of 'Fare' column
std = dataset['Fare'].std()
# Print standard deviation
print(std)
输出:
49.6934285971809056.最大:
使用DataFrame/Series.max()方法计算最大值。
Syntax: DataFrame/Series.max(self, axis=None, skipna=None, level=None, numeric_only=None, **kwargs)
Parameters:
- axis: {index (0), columns (1)}
Specify the axis for the function to be applied on.
- skipna: bool, default True
It excludes null values when computing the result.
- level: int or level name, default None
If the axis is a MultiIndex type, count along a particular level, collapsing into a Series.
- numeric_only: bool, default None
Include only float, int, boolean columns. If None value, will attempt to use everything, then use only numeric data.
- **kwargs: Additional keyword to be passed to the function.
Returns: Maximum value in Series or DataFrame (if level specified)
代码:
Python3
# Calculate Maximum value in 'Age' column
maxValue = dataset['Age'].max()
# Print maxValue
print(maxValue)
输出:
80.07. 分钟:
使用DataFrame/Series.min()方法计算最小值。
Syntax: DataFrame/Series.min(self, axis=None, skipna=None, level=None, numeric_only=None, **kwargs)
Parameters:
- axis: {index (0), columns (1)}
Specify the axis for the function to be applied on.
- skipna: bool, default True
It excludes null values when computing the result.
- level: int or level name, default None
If the axis is a MultiIndex type, count along a particular level, collapsing into a Series.
- numeric_only: bool, default None
Include only float, int, boolean columns. If None value, will attempt to use everything, then use only numeric data.
- **kwargs: Additional keyword to be passed to the function.
Returns: Minimum value in Series or DataFrame (if level specified)
代码:
Python3
# Calculate Minimum value in 'Fare' column
minValue = dataset['Fare'].min()
# Print minValue
print(minValue)
输出:
0.00008. 描述:
使用DataFrame/Series.describe()方法总结一般描述性统计数据。
Syntax: DataFrame/Series.describe(self: ~ FrameOrSeries, percentiles=None, include=None, exclude=None)
Parameters:
- percentiles: list-like of numbers, optional
- include: ‘all’, list-like of dtypes or None values (default), optional
- exclude: list-like of dtypes or None values (default), optional,
Returns: Summary statistics of the Series or Dataframe provided.
Python3
# Statistical summary
dataset.describe()
输出: